Download presentation
Presentation is loading. Please wait.

1
Presenter : Cheng-Ta Wu Kenichiro Anjo, Member, IEEE, Atsushi Okamura, and Masato Motomura IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL. 39,NO. 5, MAY 2004

2
Abstract Whats the problem Related works The proposed method Experiment Results

3
A low-cost wrapper-based bus implementation is described that performs well in system-on-chip (SOC) designs. Novel wrapper implementation techniques are used to create wrappers without embedded data buffers. The bus uses 1) a novel slave wrapper interface that supports flow control signals, 2) a write buffer switching technique for the master wrappers to achieve good performance at a small hardware cost, 3) a novel retry management technique called slave designated retry control (SDRC) to enable slow IP core connections and a livelock avoidance scheme using the SDRC technique, and 4) a novel bit-width conversion technique using data-width converters embedded in the bus multiplexers. A CPU-based SOC designed with the proposed bus showed that these techniques can increase throughput by about 14%, and reduce read and write latencies by about 16% and 11% compared to a conventional wrapper- based bus, when running a modeled average traffic pattern for this chip. The implemented results show that these techniques can reduce the hardware costs by 28% or 50% compared with two conventional wrapper-based conversion techniques. The chip is implemented using 0.15- m CMOS process technologies. The area for the on-chip bus is 3.3 mm2 and the operation clock frequency is 200 MHz.
 a novel slave wrapper interface that supports flow control signals, 2) a write buffer switching technique for the master wrappers to achieve good performance at a small hardware cost, 3) a novel retry management technique called slave designated retry control (SDRC) to enable slow IP core connections and a livelock avoidance scheme using the SDRC technique, and 4) a novel bit-width conversion technique using data-width converters embedded in the bus multiplexers. A CPU-based SOC designed with the proposed bus showed that these techniques can increase throughput by about 14%, and reduce read and write latencies by about 16% and 11% compared to a conventional wrapper- based bus, when running a modeled average traffic pattern for this chip. The implemented results show that these techniques can reduce the hardware costs by 28% or 50% compared with two conventional wrapper-based conversion techniques. The chip is implemented using m CMOS process technologies. The area for the on-chip bus is 3.3 mm2 and the operation clock frequency is 200 MHz..")
4
A reliable scheme to reuse IP cores is thus important, and on-chip communication is considered a key technology for this. On-chip buses can be classified into standard buses and wrapper based buses. Standard buses (such as AMBA bus) specify protocols over wiring connections between IP cores, IP cores designed to comply with one of these protocols can be reused in another SOC using the same bus. However, they cant be connected to a different bus without changing their bus interface logic. Wrapper based bus (such as OCP) is a promising technology for reusing IP cores because it separates the communication logic from the cores thereby avoiding the connectivity problems related to physical bus protocols. Hence, IP cores complying with the interface protocol can be integrated into SOCs that have different physical buses as backbones. However, attaching simple wrapper hardware increases the access latencies, so the wrapper must be optimized and given more hardware logic to optimize its performance.
 specify protocols over wiring connections between IP cores, IP cores designed to comply with one of these protocols can be reused in another SOC using the same bus. However, they cant be connected to a different bus without changing their bus interface logic. Wrapper based bus (such as OCP) is a promising technology for reusing IP cores because it separates the communication logic from the cores thereby avoiding the connectivity problems related to physical bus protocols. Hence, IP cores complying with the interface protocol can be integrated into SOCs that have different physical buses as backbones. However, attaching simple wrapper hardware increases the access latencies, so the wrapper must be optimized and given more hardware logic to optimize its performance..")
5
Standard on-chip bus protocols [1] AMBA [2] Core Connect IBM Wrapper interface definition [3] OCP [4] Virtual Component Interface (VCI) [8] Embed FIFOs to buffer request and write data in the wrapper This paper
![Standard on-chip bus protocols [1] AMBA [2] Core Connect IBM Wrapper interface definition [3] OCP [4] Virtual Component Interface (VCI) [8] Embed FIFOs to buffer request and write data in the wrapper This paper](http://images.slideplayer.com/5/1526472/slides/slide_5.jpg "Standard on-chip bus protocols [1] AMBA [2] Core Connect IBM Wrapper interface definition [3] OCP [4] Virtual Component Interface (VCI) [8] Embed FIFOs to buffer request and write data in the wrapper This paper")
6
Defined unique wrapper interfaces including a flow-based slave interface. Developed wrapper implementation techniques: Write buffer switching(WBS) Slave designated retry control(SDRC) Bit-width conversion technique using data-width converters embedded in the bus multiplexer.
 Slave designated retry control(SDRC) Bit-width conversion technique using data-width converters embedded in the bus multiplexer..")
9
added status signals that indicate busy or not busy for the request buffer and the write data buffer in the slave core and retry interval signals for specifying the back-off interval for retrying.

10
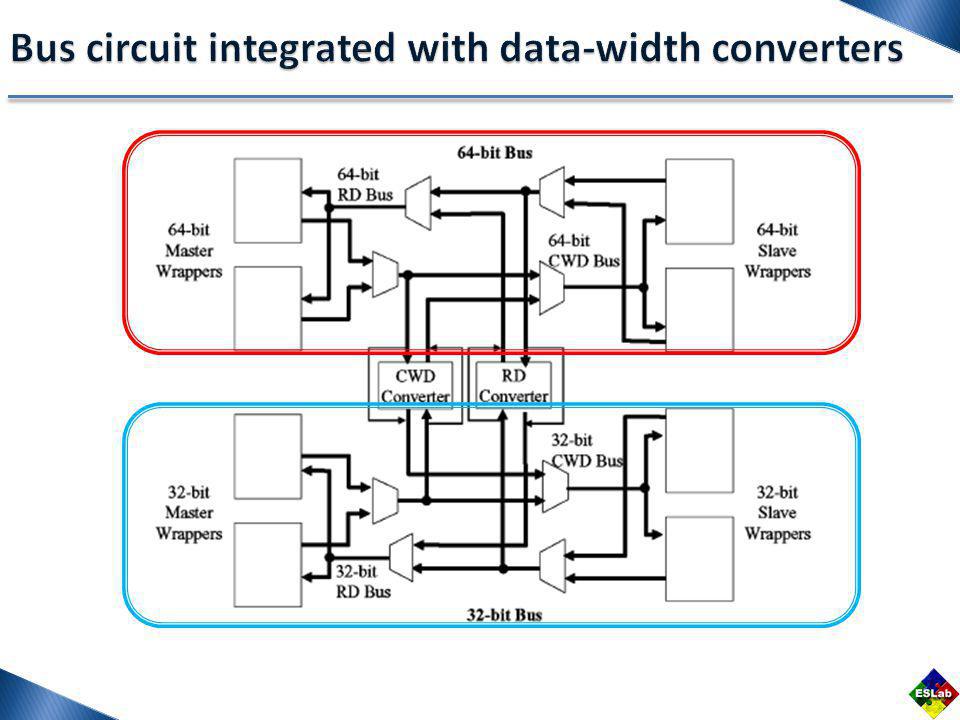
The CWD bus conveys requests, addresses, commands, sizes, command IDs, master IDs, write data, acknowledgment (ACKs), nonacknowledgements (NACKs), and retry information. The RD bus conveys responses, read data, command IDs, and master IDs.

11
With a write-data buffer, the master wrapper can output the buffered write data onto the CWD bus as soon as it receives an ACK.

12
The master wrapper determines whether to store the write data in the buffer, by comparing the requested command size to the buffer size.

18
CPU-based SOC with developed wrapper-based bus This SOC has 400-MHz 64-bit 2-issue superscalar processor core, 256-KB level-2 cache, and a DDR-SDRAM interface. The SDRAM is accessible through the L2 cache from an on-chip bus. Along with the on-chip bus, a CPU core, a PCI-X interface, two 10/100-base Ethernet MACs, a local bus interface, and a performance monitor are connected as five masters and seven slaves.

19
75% of the traffic from the master operating as a CPU was for the slow slave core and 25% was for the fast one. The traffic of the other master was randomly generated, and the ratio of read and write commands was even. When slaves became available in 1 and 16 cycles, the throughput decreased as the retry interval was increased. When they became available in 32 and 64 cycles, the tendency changed. When slaves became available in 64 cycles, the bus with a 64-cycle retry interval had the highest throughput.

20
We evaluated the throughput for three sizes of the write buffer in a master wrapper for four traffic patterns. Traffic pattern A was the average case in which all five masters accessed the slaves using bursts with random sizes from five supported sizes up to 128 bytes. In pattern B, one high-performance master required mostly longer burst transfers, while the other masters required shorter burst transfers. In pattern C, one master generated the same transactions we used in the SDRC evaluation as a CPU model, while the other masters generated shorter burst transfers with request intervals up to 20–30 cycles. Pattern D was the modeled traffic of the targeted SOC. One master was modeled as a CPU, as in pattern C; another master was modeled as a PCI-X interface that required frequent DMA transactions from off-chip I/O devices. The other masters required shorter burst transfers corresponding to those of Ethernet interfaces. With the developed WBS technique, using a 16-byte buffer improved the performance by about 1% to 9%, while a 128-byte buffer improved it by about 6% to 12%.

21
The system had two 32-bit masters, two 32-bit slaves, three 64-bit masters, three 64-bit slaves, a CWD data- width converter, and an RD data-width converter, with an early bus request (EBR), using our WBS technique and a flow-controlled interface (I/F). The arbitration request is called an early bus request (EBR) and can be asserted several cycles before the read response request is initiated.
 and can be asserted several cycles before the read response request is initiated..")
22
Automatic Interface Synthesis based on the Classification of Interface Protocols of IPs Protocol Transducer Synthesis using Divide and Conquer approach Efficient Network Interface Architecture for Network-on-chip Automatic synthesis interface Out of order wrapper architecture An Interface-Circuit Synthesis Method with Configurable Processor Core in IP- Based SoC Designs Wrapper-Based Bus Implementation Techniques for Performance Improvement and Cost Reduction Wrapper-Based Bus Implementation Techniques

Similar presentations