Download presentation
Presentation is loading. Please wait.

1
IA Research Method & Design Year 2 IB Psych Only

2
Methodology The research method used. – Does more than outline the researchers’ methods “We conducted a survey of 50 people over a two-week period and subjected the results to statistical analysis”

3
The Scientific Method 1. Define a research problem 2. Propose a hypothesis and make predictions Hypothesis: A testable prediction Must have operational definitions (a statement of the procedures used to define the variables) Ex: human intelligence is defined as what an intelligence test measures. (teacher without a rubric?) Must be replicable. (repeatable) 3. Design and conduct a research study 4. Analyze the data 5. Communicate the results, build new theories (modify and try again)
 Ex: human intelligence is defined as what an intelligence test measures. (teacher without a rubric ) Must be replicable. (repeatable) 3. Design and conduct a research study 4. Analyze the data 5. Communicate the results, build new theories (modify and try again).")
5
Correlational Research Detects relationships between 2 variables (X & Y, dogs & cats) Does NOT say that one variable causes another. # of books read= $$ salary

6
Correlational Research perfect positive correlation perfect positive correlation (+1.00) high scores on 1 set are associated with high scores on another set – (ex: between children’s age and height) perfect negative correlation perfect negative correlation (-1.00) high negative correlation – (dancing accidents and amount of alcohol drunk) 45 degree angle +1 45 degree angle -1 X (IV) horizontal line
 high scores on 1 set are associated with high scores on another set – (ex: between children’s age and height) perfect negative correlation perfect negative correlation (-1.00) high negative correlation – (dancing accidents and amount of alcohol drunk) 45 degree angle degree angle -1 X (IV) horizontal line")
7
How to Read a Correlation Coefficient

8
Correlations X axis Independent variable on X axis Y axis Dependant variable on Y axis X axis Y axis

9
Scatterplot A graphed cluster of dots; each represents the value of 2 variables – The slope of the points indicates the relationship – The amount of scatter suggests the strength of correlation (high or low) HighLow No Correlation No Correlation (scatterplot) correlation of 0.00 shows the 2 sets are not related
 HighLow No Correlation No Correlation (scatterplot) correlation of 0.00 shows the 2 sets are not related")
10
Illusory Correlation Sometime we see relationships which do not exist – We believe there is relationship and so we recall instances which confirm our belief Ex: Length of marriage relates to male baldness? Mr. Pointy always gives me a better math score!

11
Experimental Research The researcher manipulates 1 or more factors – Explore cause and effect relationships. – Observe the effect on some behavior or mental process – Controlled Observation You control & manipulate the environment and the variables – Mozart causes depression – Bananas cause constipation

12
RESEARCH DESIGN

13
Research Design Skepticism: Skepticism: A researcher needs to be skeptical (doubt until proven) Let the data speak for itself
 Let the data speak for itself")
14
Research Design Overconfidence Overconfidence: confirmation bias (if you are not skeptical) “Of course it will be X” We tend to think we know more than we do. – 82% of U.S. drivers think they are the top 30% in safety – 81% of new business owners believe their business will succeed. Their peers? Only 39%. (Now that’s overconfidence!!!)
.")
15
Research Design Hindsight bias: Hindsight bias: “I Knew It All Along” The tendency to believe, after learning the outcome, that you knew it all along. – Looking backwards – Solving a puzzle, once it’s done – “Oh, that was obvious.” – “Of course, ANY dummy could see Sept. 11, 2001 would happen.” Not Sept 10 th !

16
Research Design Replication Replication – You are able to repeat the experiment – You will get similar results no matter how often you repeat Operational Definition Operational Definition – Procedures used in defining research variables – Narrow down the focus of the study – Study Ritalin, all kids? ADHD? Boys? WS? All schools? 1 school?

17
Research Design Hypothesis: Hypothesis: what problem or situation do you want to solve, test, or discover? Example: I want to see the results of Ritalin on young boys (age 13-16) who have ADHD, and live in Winston Salem, NC.
 who have ADHD, and live in Winston Salem, NC..")
18
Research Design Population Population - large group – The subjects or people to be studied Sample: Sample: draw from your Population – Age, gender, geographic location – Random from population – Random selection and assignment Representativeness Representativeness – Sample accurately reflects the population

19
Random Sampling

20
Research Design Representativeness: Representativeness: What percentage do you need? population Depends on the population in the study. – 100 out of 500= 20% (larger pop, lower %) – 10-15 out of a class of 25= 40-50% (smaller pop, larger %) – Netherlands studies 800,000, only need 4-5% (40,000 people in study)
 – out of a class of 25= 40-50% (smaller pop, larger %) – Netherlands studies 800,000, only need 4-5% (40,000 people in study).")
21
Research Design Random Assignment to Groups Random Assignment to Groups – Do not categorize based on gender, age, size, GPA, etc. Control Group: Control Group: No change (not exposed to IV) Experimental Group: Experimental Group: Change 1 variable (only 1)
 Experimental Group: Experimental Group: Change 1 variable (only 1).")
22
Research Design Independent Variable (IV) Independent Variable (IV) – What is being introduced, what is new, what are you changing? – What is being manipulated? Dependent Variable (DV) Dependent Variable (DV) – What is being measured? – The change caused (or not caused) by the indep. variable.
 Dependent Variable (DV) – What is being measured. – The change caused (or not caused) by the indep. variable..")
23
Confounding Variables Any extraneous variables that could cause data contamination False consensus effect False consensus effect - we tend to overestimate the extent others share our beliefs and behaviors. Reactivity: Reactivity: When a subject’s behavior is changed because s/he knows that s/he is being observed

24
Confounding Variables Demand Characteristics Demand Characteristics: When a subject behaves in the way that s/he thinks the experimenter wants, rather than in a natural fashion Experimenter Bias Experimenter Bias: Certain behaviors from the researcher bias the subject’s behavior (*) Experimental condition Experimental condition - actual setting, paint color, music, noise, time or day, what the subject ate for breakfast, the weather, the season of year
 Experimental condition Experimental condition - actual setting, paint color, music, noise, time or day, what the subject ate for breakfast, the weather, the season of year")
25
Research Design Prevention of Contamination Prevention of Contamination – How to stop those Confounding Variables – Single Blind – Single Blind: subject is unaware (Persistent/Stubborn) – Double Blind – Double Blind: Assistant & Subject Unaware
 – Double Blind – Double Blind: Assistant & Subject Unaware")
26
Research Design Statistics & Data Statistics & Data T-test, CHI-square, Z-score Psychometrics Statistical Significance Statistical Significance 95% – “I want to prove that my independent variable causes my dependent variable 95% of the time” – 95% to be valid P<.05(5%) – Probability= P<.05(5%) chance, random, chaos theory
 – Probability= P<.05(5%) chance, random, chaos theory")
27
STATISTICAL METHODOLOGY T-Test, Chi-Squared, Mean, Median, Mode

28
2 Types of Statistics 2 types of analysis techniques: Descriptive statistics 1. Descriptive statistics: techniques that help summarize large amounts of info. Include measures of variability and measures of correlation (Describe the data) PopulationBag of M&Ms Population, Bag of M&Ms Inferential statistics 2. Inferential statistics: techniques that help researchers make generalizations about a finding, based on a limited number of subjects SampleHandful of M&Ms Sample, Handful of M&Ms
 PopulationBag of M&Ms Population, Bag of M&Ms Inferential statistics 2. Inferential statistics: techniques that help researchers make generalizations about a finding, based on a limited number of subjects SampleHandful of M&Ms Sample, Handful of M&Ms.")
29
Descriptive Statistics – Frequency distribution – Frequency distribution - organizational technique that shows the number of times each score occurs, so that the scores can be interpreted Graph depictions – frequency polygon – frequency polygon - curve – frequency histogram – frequency histogram - bars

30
Descriptive Statistics – Central Tendency – Central Tendency - a number that represents the entire group or sample – Tend to hover towards the center Average IQ score, around 100 2 genius parents tend to have average IQ child Politicians (Dem or Rep) dance in the center for max. votes Weight distribution

31
Descriptive Statistics – The Bell Curve – Grades, IQ, Poverty – Link between intelligence and salary When did a C become an F? Is a C acceptable? C=average Does everyone get a trophy, ribbon? Can everyone get an A?

32
Descriptive Statistics mean mean - the arithmetic average median median - middle score when arranged lowest to highest mode mode - the most frequent score in a distribution – unimodal – unimodal - one high point – bimodal – bimodal - two high points Set: 2, 2, 3, 5, 8Median: 3Mode: 2 Mean: Add up (20), divide by 5= 4
, divide by 5= 4")
33
Descriptive Statistics – bimodal – bimodal - two high points – The more overlap in the bimodal arches, the higher the variable link between the data – The less overlap, the lower the connection

35
Descriptive Measures 2 ways we measure: Range 1. Range: Highest score minus the lowest score-- tells how far apart the scores are – simplest measures of variability to calculate. (weakness of range: it can easily be influenced by one extreme score, Savant IQ of 220) Set: 2, 2, 3, 5, 8 6 Range: 8 - 2 = 6 Ex: Age Range 15-17, Difference 2 7-17, Difference 10 Child prodigies, Dougie Houser, Chess, sci, art, music
 Set: 2, 2, 3, 5, 8 6 Range: = 6 Ex: Age Range 15-17, Difference , Difference 10 Child prodigies, Dougie Houser, Chess, sci, art, music.")
36
Descriptive Measures The other way to measure is: Standard Deviation 2. Standard Deviation: measure of variability that describes how scores are distributed around the mean. – (1 SD, 2 SD, -1, -2) – Central Tendency: tend to hover near the center.
 – Central Tendency: tend to hover near the center..")
37
Standard Deviation 34% 13.5% 2% 68% 95% 99% 1% outliers Savant, 220 1 in 30 million

38
Standard Deviation To calculate standard deviation (SD): mean4 1. find the mean of the distribution 4 subtractmean 4-2, 4-2, 4-3, 4-5, 4-8 2. subtract each score from the mean 4-2, 4-2, 4-3, 4-5, 4-8 square4-2=2 2 squared=4 3. square each result – “deviations” 4-2=2 2 squared=4 add4 + 4 + 1 + 1 + 16 = 26 4. add the squared deviations 4 + 4 + 1 + 1 + 16 = 26 dividenumber variance 26 / 4 (5 – 1) = 6.5 (V) 5. divide by the total number (n - 1) of scores; this result is called the variance 26 / 4 (5 – 1) = 6.5 (V) square root variancestandard deviation (SD)2.55 (SD) 6. find the square root of the variance; this is the standard deviation (SD)2.55 (SD) n = biased sample 5 7. n = biased sample – does not accurately represent population being tested (out of the norm, get rid of out-liers) 5 (n - 1) unbiased sample4 8. (n - 1) = unbiased sample4 (ex: 3 different class scores, 78, 80, 92) 9. now you can compare distributions with different means and standard deviations (ex: 3 different class scores, 78, 80, 92) Set: 2, 2, 3, 5, 8
 = 6.5 (V) 5. divide by the total number (n - 1) of scores; this result is called the variance 26 / 4 (5 – 1) = 6.5 (V) square root variancestandard deviation (SD)2.55 (SD) 6. find the square root of the variance; this is the standard deviation (SD)2.55 (SD) n = biased sample 5 7. n = biased sample – does not accurately represent population being tested (out of the norm, get rid of out-liers) 5 (n - 1) unbiased sample4 8. (n - 1) = unbiased sample4 (ex: 3 different class scores, 78, 80, 92) 9. now you can compare distributions with different means and standard deviations (ex: 3 different class scores, 78, 80, 92) Set: 2, 2, 3, 5, 8.")
39
Sigma Sigma Σ Σ Σ the symbol for standard deviation (SD) is s. – Greek letter “sigma” (lower case form) S S upper case letter (other Greek “sigma”) – Standard meaning in mathematics, “add up a list of numbers.” – Represents Sum, i.e. add together
 S S upper case letter (other Greek sigma ) – Standard meaning in mathematics, add up a list of numbers. – Represents Sum, i.e. add together.")
40
Z-Score Z-scores Z-scores: a way of expressing a score’s distance from the mean in terms of the standard deviation (SD) subtract meandivide standard deviation 8 – 4 (M)= 4 / 2.55 (SD) = 1.56 to find a Z-score for a number in a distribution, subtract the mean from that number, and divide the result by the standard deviation 8 – 4 (M)= 4 / 2.55 (SD) = 1.56 positive a positive Z-score shows that the number is higher than the mean (You’re OK, IQ, health average or higher) negative a negative Z-score allows psychologists to compare distributions with different means and standard deviations (Below average, health, psych concerns) Sometimes Z-scores are necessary to explain standard deviation in an experiment’s results/discussion POS Z NEG Z
 subtract meandivide standard deviation 8 – 4 (M)= 4 / 2.55 (SD) = 1.56 to find a Z-score for a number in a distribution, subtract the mean from that number, and divide the result by the standard deviation 8 – 4 (M)= 4 / 2.55 (SD) = 1.56 positive a positive Z-score shows that the number is higher than the mean (You’re OK, IQ, health average or higher) negative a negative Z-score allows psychologists to compare distributions with different means and standard deviations (Below average, health, psych concerns) Sometimes Z-scores are necessary to explain standard deviation in an experiment’s results/discussion POS Z NEG Z")
41
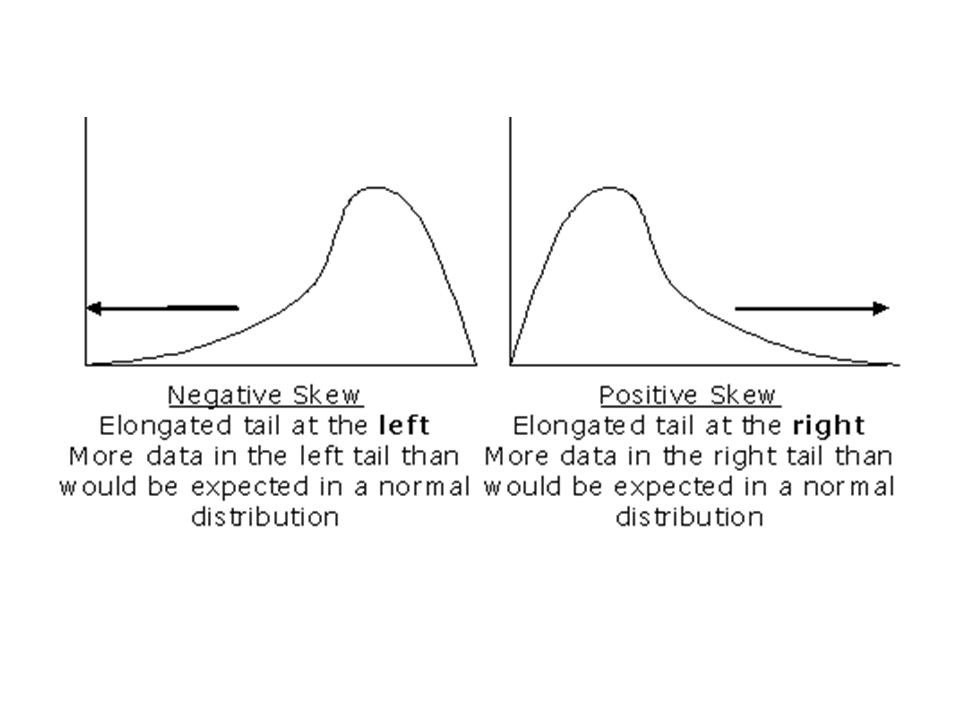
Skewed Results highlow skewed When there are more scores at the high or low end of a distribution it is said to be skewed – tail signifies the extreme score – Single tailed – Single tailed = extreme score on either side – Which direction are the “outliers?” – Called Right/Left Skew – Also Pos./Neg. Skew Majority Outliers: fringe, oddball, genius, bad egg

43
A Skewed Distribution Are the results positively or negatively skewed? Positive Skew or Skewed Right

44
Inferential Statistics Tests of Significance experimentalcontrol groups independent variable random chance Tests of Significance - used for determining whether the difference in scores between the experimental and control groups is really due to the effects of the independent variable or just due to random chance p <.05 (95%) If p <.05 (95%) the outcome (or the difference between experimental and control groups) has a probability of occurring by random chance less than 5 x per 100 – Researchers conclude the effect of the independent variable is significant (real).
 If p <.05 (95%) the outcome (or the difference between experimental and control groups) has a probability of occurring by random chance less than 5 x per 100 – Researchers conclude the effect of the independent variable is significant (real).")
45
Inferential Statistics Statistically Significant Statistically Significant – It is concluded that the independent variable made a real difference between the experimental group and the control group – Ritalin really DOES help ADHD – Raising serotonin levels DOES help Depression (yoga)
")
46
Null Hypothesis Null Hypothesis: Null Hypothesis: any alternative hypothesis, if yours is wrong! Significance testsacceptrejectnull hypothesis Significance tests are used to accept or reject the null hypothesis. <.05 (95%) – If the probability of observing your result is <.05 (95%) truereject the null hypothesis – Your theory is true, reject the null hypothesis Meaning that your original hypothesis is possible (without chance, random, chaos) >.05 – If the probability of observing your result is >.05 accept the null. Meaning that your original hypothesis is not possible (too much left to chance, random events) You need a backup, alternative hypothesis
 – If the probability of observing your result is <.05 (95%) truereject the null hypothesis – Your theory is true, reject the null hypothesis Meaning that your original hypothesis is possible (without chance, random, chaos) >.05 – If the probability of observing your result is >.05 accept the null. Meaning that your original hypothesis is not possible (too much left to chance, random events) You need a backup, alternative hypothesis.")
47
Null Hypothesis Practice Accept or Reject the Null? Accept or Reject the Null? My hypothesis: Drug X will stop sleep walking 95%. Do the testing. Do the data. Drug X has a probability of 63%. 5% Is it greater than or less than 5% chance? <>.05? Do you accept the Null or reject the Null Hypothesis? ACCEPT the NULL! My theory was wrong! 37% chance, error, random – Maybe it’s the patients I chose? – Maybe too much caffeine before bed? – Maybe drug was contaminated in the lab? – Start over, new test, new drug, new data

48
Null Hypothesis Practice Accept or Reject the Null? Accept or Reject the Null? My hypothesis: Stress causes mice to gain weight. Do the testing. Do the data. The “stressed mice” gained weight 97%. The “control group” of mice showed no weight gain. 5% Is it greater than or less than 5% chance? <>.05? Do you accept the Null or reject the Null Hypothesis? REJECT the NULL! My theory was right! 3% chance, error, random – Good Job! Bonus and a raise!

49
Types of Tests 1. T-Test 1. T-Test 2. Chi-Square Test 2. Chi-Square Test 3. Mann-Whitney U 3. Mann-Whitney U 4. Sign Test 4. Sign Test 5. Wilcoxon Matched-Pairs Signed-Rank Test 5. Wilcoxon Matched-Pairs Signed-Rank Test

50
When to Use the T-Test? T-Test1variable2 situations T-Test – when 1 variable is used in 2 situations -- Ex: Ritalin effects in either ADHD males or ADHD females -- Ex: subject has to pick out a letter in a round list or a square list

51
Common situation in psychology: “experimental” “control” Randomly assign people to an “experimental” group or a “control” group to study the effect mean 2 conditions – In this situation, we are interested in the mean difference between the 2 conditions. significance test – The significance test used in this kind of scenario is called a t-test. observedmean difference Used to determine whether the observed mean difference is within the range (less that.05) that would be expected if the null hypothesis were true. When to Use the T-Test?
 that would be expected if the null hypothesis were true. When to Use the T-Test .")
52
How to Use the T-Test? T-Test T-Test Subtractmean 1. Subtract mean from each score 2. Rank items Positive 3. Sum of Positive Ranks Negative 4. Sum of Negative Ranks 5. Smallest score = T t > 1.96 1.96 or < - 1.96, then p <.05 (Test is Valid) GIRLSBOYS 74 52 23 14 41 53 64 3021
 GIRLSBOYS")
53
How to Use the T-Test? T-Test T-Test Subtractmean 1. Subtract mean from each score Mean= 21 divided by 7 = 3 4-3, 2-3, 3-3, 4-3, 1-3, 3-3, 4-3 1, -1, 0, 1, -2, 0, 1 2. Rank items 1, 1, 1, 0, -1, -2 Positive 3. Sum of Positive Ranks 1+1+1+0=3 Negative 4. Sum of Negative Ranks -1 + -2 = -3 5. Smallest score = t (-3) t > 1.96 1.96 or < - 1.96, then p <.05 BOYS 4 2 3 4 1 3 4 21 7 scores Test is VALID
 t > or < , then p <.05 BOYS scores Test is VALID.")
54
We have to redo our hypothesis ??? That bites

55
Awesome Calculators! www.graphpad.com/quickcalcs/index.cfm T-Test Chi-Square

56
When do I Use Chi-Square? A common situation in psychology is when a researcher is interested in the relationship between 2 nominal or categorical variables. The significance test used in this kind of situation is called a chi-square ( 2 ). Ex: We are interested in whether single men vs. women are more likely to own cats vs. dogs. Ex: We are interested in whether single men vs. women are more likely to own cats vs. dogs. Notice that both variables are categorical. – Kind of pet – Gender male or female. Chai-squared
. Ex: We are interested in whether single men vs. women are more likely to own cats vs. dogs. Ex: We are interested in whether single men vs. women are more likely to own cats vs. dogs. Notice that both variables are categorical. – Kind of pet – Gender male or female. Chai-squared.")
57
Example Data: Observed (Actual Data) Males dogs Males are more likely to have dogs as opposed to cats Females cats Females are more likely to have cats than dogs CatDog Male203050 Female302050 100 NHST NHST (Null Hypothesis Significance Testing) Question: Are these differences best accounted for by the null hypothesis? Is there is a real relationship between gender and pet ownership?

58
Chi-Square Test – when there are 2 variables – The closer your results (Experimental and Control), the harder to prove if indep. variable (IV) really worked. – Further apart, you can see definite difference.
 really worked. – Further apart, you can see definite difference..")
59
Example Data: Expected Data expected value To find expected value for a cell of the table, multiply the corresponding row total by the column total, and divide by the grand total For the first cell (and all other cells) (50 x 50)/100 = 25 Thus, if the two variables are unrelated, we would expect to observe 25 people in each cell CatDog Male25 50 Female25 50 100
 (50 x 50)/100 = 25 Thus, if the two variables are unrelated, we would expect to observe 25 people in each cell CatDog Male25 50 Female")
60
Example Data: Expected vs. Observed expected values (25) observed values(see boxes) The differences between these (E) expected values (25) and the (O) observed values (see boxes) are aggregated according to the Chi-square formula: CatDog Male203050 Female302050 100
 observed values(see boxes) The differences between these (E) expected values (25) and the (O) observed values (see boxes) are aggregated according to the Chi-square formula: CatDog Male Female")
61
chi-square chi-square sampling distribution Once you have the chi-square statistic, it can be evaluated against a chi-square sampling distribution if the null hypothesis is true The sampling distribution characterizes the range of chi-square values we might observe if the null hypothesis is true, but sampling error is giving rise to deviations from the expected values. 4.0p- value was >.05 In our example in which the chi-square was 4.0, the associated p- value was >.05 Null Hypothesis Accept the Null Hypothesis, need an Alternative Hypothesis, You did NOT prove your experiment Do We Accept or Reject the Null?

62
Mann-Whitney U Test Skewed results? Are they from the same distribution? – Use to determine if there were problems with sampling, population, contamination – Use for 2 groups (samples) – Sub. For T-Score (T-Test) – Ex: Experimental & Control
 – Sub. For T-Score (T-Test) – Ex: Experimental & Control.")
63
How To Use Mann-Whitney U Test – Ex: Experimental & Control – Lay out all of your scores (in both groups) Rank 1Rank 15 – Rate them Rank 1 (lowest) - Rank 15 (highest) Experimental GroupControl Group Experimental GroupControl Group Time (min)RankTime (min)Rank 1 14041301 14761352 15381383 160101445 165111487 170131559 1711416812 15 19315
 Rank 1Rank 15 – Rate them Rank 1 (lowest) - Rank 15 (highest) Experimental GroupControl Group Experimental GroupControl Group Time (min)RankTime (min)Rank")
64
How To Use Mann-Whitney U Test Add up the sum of both groups (+) Experimental GroupControl Group Experimental GroupControl Group Time (min)RankTime (min)Rank 14041301 14761352 15381383 160101445 N1=8 16511 N1=8 1487 170131559 1711416812 19315________________________________ R1 =81, N1=8 R2 =39, N2=7 R1 =81, N1=8 R2 =39, N2=7 N2=7
 Experimental GroupControl Group Experimental GroupControl Group Time (min)RankTime (min)Rank N1= N1= ________________________________ R1 =81, N1=8 R2 =39, N2=7 R1 =81, N1=8 R2 =39, N2=7 N2=7")
65
How To Use Mann-Whitney U Test Experimental GroupControl Group Experimental GroupControl Group R1 =81, N1=8 R2 =39, N2=7 R1 =81, N1=8 R2 =39, N2=7 Formula to find U Formula to find U (Hypothetical Data Statistics) U=N1N2 + N1(N1+1)-R1 2 U=(8)(7) + 8(9) -81 2 U= 56 + 36 – 81 U= 11
 U=N1N2 + N1(N1+1)-R1 2 U=(8)(7) + 8(9) U= – 81 U= 11")
66
How To Use Mann-Whitney U Test Experimental GroupControl Group Experimental GroupControl Group R1 =81, N1=8 R2 =39, N2=7U=11 R1 =81, N1=8 R2 =39, N2=7U=11 Is 11 in between the N1-N2 range of #s on the chart? (6-50) YES Is 11 in between the N1-N2 range of #s on the chart? (6-50) YES Go to the Mann-Whitney Chart (Table 1) N12345678 N2 2 3 4 5 6 76/50
 YES Is 11 in between the N1-N2 range of #s on the chart. (6-50) YES Go to the Mann-Whitney Chart (Table 1) N N /50.")
67
How To Use Mann-Whitney U Test Experimental GroupControl Group Experimental GroupControl Group R1 =81, N1=8 R2 =39, N2=7U=11 R1 =81, N1=8 R2 =39, N2=7U=11 Is 11 in between the N1-N2 range of #s on the chart? (6-50) Is 11 in between the N1-N2 range of #s on the chart? (6-50) If YES, If YES, reject the Null Hypothesis, your data is acceptable to use Your distribution and population is acceptable, even though a skew has occurred, you are within the acceptable range If NO If NO, accept the Null Hypothesis, your data is not acceptable Something has contaminated your population or your data, you must go to a Null, or Alternate Hypothesis.
 Is 11 in between the N1-N2 range of #s on the chart. (6-50) If YES, If YES, reject the Null Hypothesis, your data is acceptable to use Your distribution and population is acceptable, even though a skew has occurred, you are within the acceptable range If NO If NO, accept the Null Hypothesis, your data is not acceptable Something has contaminated your population or your data, you must go to a Null, or Alternate Hypothesis..")
Similar presentations


>")
>")
 Chapter 1 Thinking Critically with Psychological Science James A. McCubbin, PhD Clemson University Worth Publishers.>")

 Chapter 1 Thinking Critically with Psychological Science James A. McCubbin, PhD Clemson.>")














