Download presentation
Presentation is loading. Please wait.

1
Toward a Universal Inference Engine Henry Kautz University of Washington With Fahiem Bacchus, Paul Beame, Toni Pitassi, Ashish Sabharwal, & Tian Sang

2
Universal Inference Engine Old dream of AI – General Problem Solver – Newell & Simon Logic + Inference – McCarthy & Hayes Reality: 1962 – 50 variable toy SAT problems 1992 – 300 variable non-trivial problems 1996 – 1,000 variable difficult problems 2002 – 1,000,000 variable real-world problems

3
Pieces of the Puzzle Good old Davis-Putnam-Logemann- Loveland Clause learning (nogood-caching) Randomized restarts Component analysis Formula caching Learning domain-specific heuristics
 Randomized restarts Component analysis Formula caching Learning domain-specific heuristics")
4
Generality SAT #SAT Bayesian Networks Bounded-alternation Quantified Boolean formulas Quantified Boolean formulas Stochastic SAT #P complete NP complete PSPACE complete

5
1. Clause Learning with Paul Beame & Ashish Sabharwal

6
DPLL( F ) // Perform unit propagation while exists unit clause (y) F F F | y if F is empty, report satisfiable and halt if F contains the empty clause return else choose a literal x DPLL( F | x ) DPLL( F | x ) DPLL Algorithm Remove all clauses containing y Shrink all clauses containing y
 // Perform unit propagation while exists unit clause (y) F F F | y if F is empty, report satisfiable and halt if F contains the empty clause return else choose a literal x DPLL( F | x ) DPLL( F | x ) DPLL Algorithm Remove all clauses containing y Shrink all clauses containing y")
7
Extending DPLL: Clause Learning Added conflict clauses Capture reasons of conflicts Obtained via unit propagations from known ones Reduce future search by producing conflicts sooner When backtracking in DPLL, add new clauses corresponding to causes of failure of the search EBL [Stallman & Sussman 77, de Kleer & Williams 87] CSP [Dechter 90] CL [Bayardo-Schrag 97, MarquesSilva-Sakallah 96, Zhang 97, Moskewicz et al. 01, Zhang et al. 01]
![Extending DPLL: Clause Learning Added conflict clauses Capture reasons of conflicts Obtained via unit propagations from known ones Reduce future search by producing conflicts sooner When backtracking in DPLL, add new clauses corresponding to causes of failure of the search EBL [Stallman & Sussman 77, de Kleer & Williams 87] CSP [Dechter 90] CL [Bayardo-Schrag 97, MarquesSilva-Sakallah 96, Zhang 97, Moskewicz et al.](http://images.slideplayer.com/25/8226056/slides/slide_7.jpg "01, Zhang et al. 01].")
8
Conflict Graphs FirstNewCut scheme (x 1 x 2 x 3 ) Decision scheme (p q b) 1-UIP scheme t pp qq b a x1x1 x2x2 x3x3 y yy false tt Known Clauses (p q a) ( a b t) (t x 1 ) (t x 2 ) (t x 3 ) (x 1 x 2 x 3 y) (x 2 y) Current decisions p false q false b true
 Decision scheme (p q b) 1-UIP scheme t pp qq b a x1x1 x2x2 x3x3 y yy false tt Known Clauses (p q a) ( a b t) (t x 1 ) (t x 2 ) (t x 3 ) (x 1 x 2 x 3 y) (x 2 y) Current decisions p false q false b true")
9
CL Critical to Performance Best current SAT algorithms rely heavily on CL for good behavior on real world problems GRASP [MarquesSilva-Sakallah 96], SATO [H.Zhang 97] zChaff [Moskewicz et al. 01], Berkmin [Goldberg-Novikov 02] However, No good understanding of strengths and weaknesses of CL Not much insight on why it works well when it does
![CL Critical to Performance Best current SAT algorithms rely heavily on CL for good behavior on real world problems GRASP [MarquesSilva-Sakallah 96], SATO [H.Zhang 97] zChaff [Moskewicz et al.](http://images.slideplayer.com/25/8226056/slides/slide_9.jpg "01], Berkmin [Goldberg-Novikov 02] However, No good understanding of strengths and weaknesses of CL Not much insight on why it works well when it does.")
10
Harnessing the Power of Clause Learning (Beame, Kautz, & Sabharwal 2003) Mathematical framework for analyzing clause learning for analyzing clause learning Characterization of its power in relation to well-studied topics in in relation to well-studied topics in proof complexity theory proof complexity theory Ways to improve solver performance based on formal analysis based on formal analysis
 Mathematical framework for analyzing clause learning for analyzing clause learning Characterization of its power in relation to well-studied topics in in relation to well-studied topics in proof complexity theory proof complexity theory Ways to improve solver performance based on formal analysis based on formal analysis")
11
Proofs of Unsatisfiability When F is unsatisfiable, Trace of DPLL on F is a proof of its unsatisfiability Bound on shortest proof of F gives bound on best possible implementation Upper bound – “There is a proof no larger than K” Potential for finding proofs quickly Best possible branching heuristic, backtracking, etc. Lower bound – “Shortest proof is at least size K” Inherent limitations of the algorithm or proof system

12
Proof System: Resolution F = ( a b) ( a c) a ( b c) (a c ) Unsatisfiable CNF formula c cc Proof size = 9 empty clause (a b)( a c)( b c)(a c) aa (b c)
 ( a c) a ( b c) (a c ) Unsatisfiable CNF formula c cc Proof size = 9 empty clause (a b)( a c)( b c)(a c) aa (b c)")
13
Special Cases of Resolution Tree-like resolution Graph of inferences forms a tree DPLL Regular resolution Variable can be resolved on only once on any path from input to empty clause Directed acyclic graph analog of DPLL tree Natural to not branch on a variable once it has been eliminated Used in original DP [Davis-Putnam 60]
![Special Cases of Resolution Tree-like resolution Graph of inferences forms a tree DPLL Regular resolution Variable can be resolved on only once on any path from input to empty clause Directed acyclic graph analog of DPLL tree Natural to not branch on a variable once it has been eliminated Used in original DP [Davis-Putnam 60]](http://images.slideplayer.com/25/8226056/slides/slide_13.jpg "Special Cases of Resolution Tree-like resolution Graph of inferences forms a tree DPLL Regular resolution Variable can be resolved on only once on any path from input to empty clause Directed acyclic graph analog of DPLL tree Natural to not branch on a variable once it has been eliminated Used in original DP [Davis-Putnam 60]")
14
Proof System Hierarchy Tree-like RES Space of formulas with poly-size proofs Regular RES [Bonet et al. 00] General RES [Alekhnovich et al. 02] Frege systems … … Pigeonhole principle [Haken 85]

15
Thm1. CL can beat Regular RES Regular RES General RES Formula f Poly-size RES proof Exp-size Regular proof Example formulas GT n Ordering principle Peb Pebbling formulas [Alekhnovich et al. 02] Formula PT(f, ) Poly-size CL proof Exp-size Regular proof Regular RES CL DPLL
 Poly-size CL proof Exp-size Regular proof Regular RES CL DPLL.")
16
PT(f, ) : Proof Trace Extension Start with unsatisfiable formula f with poly-size RES proof PT(f, ) contains All clauses of f All clauses of f For each derived clause Q=(a b c) in , For each derived clause Q=(a b c) in , –Trace variable t Q –New clauses (t Q a), (t Q b), (t Q c) CL proof of PT(f, ) works by branching negatively on t Q ’s in bottom up order of clauses of
 : Proof Trace Extension Start with unsatisfiable formula f with poly-size RES proof PT(f, ) contains All clauses of f All clauses of f For each derived clause Q=(a b c) in , For each derived clause Q=(a b c) in , –Trace variable t Q –New clauses (t Q a), (t Q b), (t Q c) CL proof of PT(f, ) works by branching negatively on t Q ’s in bottom up order of clauses of ")
17
PT(f, ) : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof
 : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof ")
18
PT(f, ) : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof Trace variable t Q New clauses (t Q a) (t Q b) (t Q c) PT(f, )
 : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof Trace variable t Q New clauses (t Q a) (t Q b) (t Q c) PT(f, )")
19
PT(f, ) : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof Trace variable t Q New clauses (t Q a) (t Q b) (t Q c) PT(f, ) t Q a b c x x false FirstNewCut (a b c)
 : Proof Trace Extension (a b x)(c x) Q (a b c) ………… Formula f RES proof Trace variable t Q New clauses (t Q a) (t Q b) (t Q c) PT(f, ) t Q a b c x x false FirstNewCut (a b c)")
20
How hard is PT(f, ) ? Hard for Regular RES: reduction argument Fact 1: PT(f, ) | TraceVars = true f Fact 2: If is a Regular RES proof of g, then | x is a Regular RES proof of g | x Fact 3: f does not have small Regular RES proofs! Easy for CL: by construction CL branches exactly once on each trace variable # branches = size( ) = poly
 | TraceVars = true f Fact 2: If is a Regular RES proof of g, then | x is a Regular RES proof of g | x Fact 3: f does not have small Regular RES proofs. Easy for CL: by construction CL branches exactly once on each trace variable # branches = size( ) = poly.")
21
Implications? DPLL algorithms w/o clause learning are hopeless for certain formula classes CL algorithms have potential for small proofs Can we use such analysis to harness this potential?

22
Pebbling Formulas (a1 a2)(a1 a2) E ABC F T f G = Pebbling(G) A node X is “pebbled” if (x1 or x2) holds Source axioms: A, B, C are pebbled Pebbling axioms: A and B are pebbled D is pebbled Target axioms: T is not pebbled (b1 b2)(b1 b2)(c1 c2)(c1 c2) (e1 e2)(e1 e2) (d1 d2)(d1 d2) (t1 t2)(t1 t2)
(a1 a2) E ABC F T f G = Pebbling(G) A node X is pebbled if (x1 or x2) holds Source axioms: A, B, C are pebbled Pebbling axioms: A and B are pebbled D is pebbled Target axioms: T is not pebbled (b1 b2)(b1 b2)(c1 c2)(c1 c2) (e1 e2)(e1 e2) (d1 d2)(d1 d2) (t1 t2)(t1 t2)")
23
Pebbling Formulas (a1 a2)(a1 a2) E ABC F T f G = Pebbling(G) A node X is “pebbled” if (x1 or x2) holds Source axioms: A, B, C are pebbled Pebbling axioms: A and B are pebbled D is pebbled Target axioms: T is not pebbled (b1 b2)(b1 b2)(c1 c2)(c1 c2) (e1 e2)(e1 e2) (d1 d2)(d1 d2) (t1 t2)(t1 t2)
(a1 a2) E ABC F T f G = Pebbling(G) A node X is pebbled if (x1 or x2) holds Source axioms: A, B, C are pebbled Pebbling axioms: A and B are pebbled D is pebbled Target axioms: T is not pebbled (b1 b2)(b1 b2)(c1 c2)(c1 c2) (e1 e2)(e1 e2) (d1 d2)(d1 d2) (t1 t2)(t1 t2)")
24
Grid vs. Randomized Pebbling (a1 a2)(a1 a2) b1b1 (c 1 c 2 c 3 ) (d 1 d 2 d 3 ) l1l1 (h1 h2)(h1 h2) (i 1 i 2 i 3 i 4 ) e1e1 (g1 g2)(g1 g2) f1f1 (n1 n2)(n1 n2) m1m1 (a1 a2)(a1 a2)(b1 b2)(b1 b2)(c1 c2)(c1 c2)(d1 d2)(d1 d2) (e1 e2)(e1 e2) (h1 h2)(h1 h2) (t1 t2)(t1 t2) (i1 i2)(i1 i2) (g1 g2)(g1 g2)(f1 f2)(f1 f2)
(a1 a2) b1b1 (c 1 c 2 c 3 ) (d 1 d 2 d 3 ) l1l1 (h1 h2)(h1 h2) (i 1 i 2 i 3 i 4 ) e1e1 (g1 g2)(g1 g2) f1f1 (n1 n2)(n1 n2) m1m1 (a1 a2)(a1 a2)(b1 b2)(b1 b2)(c1 c2)(c1 c2)(d1 d2)(d1 d2) (e1 e2)(e1 e2) (h1 h2)(h1 h2) (t1 t2)(t1 t2) (i1 i2)(i1 i2) (g1 g2)(g1 g2)(f1 f2)(f1 f2).")
25
Branching Sequence B = (x 1, x 4, : x 3, x 1, : x 8, : x 2, : x 4, x 7, : x 1, x 2 ) OLD: “Pick unassigned var x” NEW: “Pick next literal y from B; delete it from B; if y already assigned, repeat”
 OLD: Pick unassigned var x NEW: Pick next literal y from B; delete it from B; if y already assigned, repeat")
26
Statement of Results DPLL-Learn*: Any clause learner with 1-UIP learning scheme and fast backtracking, e.g. zChaff [Moskewicz et al ’01] Efficient : (|f G |) time to generate B G Effective: (|f G |) branching steps to solve f G using B G Given a pebbling graph G, can efficiently generate a branching sequence B G such that DPLL-Learn*(f G, B G ) is empirically exponentially faster than DPLL-Learn*(f G )
 time to generate B G Effective: (|f G |) branching steps to solve f G using B G Given a pebbling graph G, can efficiently generate a branching sequence B G such that DPLL-Learn*(f G, B G ) is empirically exponentially faster than DPLL-Learn*(f G ).")
27
Genseq on Grid Pebbling Graphs (a1 a2)(a1 a2)(b1 b2)(b1 b2)(c1 c2)(c1 c2)(d1 d2)(d1 d2) (e1 e2)(e1 e2) (h1 h2)(h1 h2) (t1 t2)(t1 t2) (i1 i2)(i1 i2) (g1 g2)(g1 g2)(f1 f2)(f1 f2)
(a1 a2)(b1 b2)(b1 b2)(c1 c2)(c1 c2)(d1 d2)(d1 d2) (e1 e2)(e1 e2) (h1 h2)(h1 h2) (t1 t2)(t1 t2) (i1 i2)(i1 i2) (g1 g2)(g1 g2)(f1 f2)(f1 f2)")
28
Results: Grid Pebbling Original zChaff Modified zChaff Naive DPLL

29
Results: Randomized Pebbling Original zChaff Modified zChaff Naive DPLL

30
2. Randomized Restarts

31
Restarts Run-time distribution typically has high variance across instances or random seeds tie-breaking in branching heuristic heavy-tailed – infinite mean & variance! Leverage by restart strategies Heavy-tailed exponential distribution short long

32
Generalized Restarts At conflict backtrack to arbitrary point in search tree Lowest conflict decision variable = backjumping Root = restart Other = partial restart Adding clause learning makes almost any restart scheme complete (J. Marques-Silva 2002)
.")
33
Aggressive Backtracking zChaff – at conflict backtrack to above highest conflict variable Not traditional backjumping! Wasteful? Learned clause saves “most” work Learned clause provides new evidence about best branching variable and value!

34
4. Component Analysis #SAT – Model Counting

35
Why #SAT? Prototypical #P complete problem Can encode probabilistic inference Natural encoding for counting problems

36
Bayesian Nets to Weighted Counting Introduce new vars so all internal vars are deterministic A B A~A B.2.6 A.1

37
Bayesian Nets to Weighted Counting Introduce new vars so all internal vars are deterministic A B A~A B.2.6 A.1 A B PQ A.1P.2Q.6

38
Bayesian Nets to Weighted Counting Weight of a model is product of variable weights Weight of a formula is sum of weights of its models A B PQ A.1P.2Q.6

39
Bayesian Nets to Weighted Counting Let F be the formula defining all internal variables Pr(query) = weight(F & query) A B PQ A.1P.2Q.6
 = weight(F & query) A B PQ A.1P.2Q.6")
40
Bayesian Nets to Counting Unweighted counting is case where all non-defined variables have weight 0.5 Introduce sets of variables to define other probabilities to desired accuracy In practice: just modify #SAT algorithm to weighted #SAT

41
Component Analysis Can use DPLL to count models Just don’t stop when first assignment is found If formula breaks into separate components (no shared variables), can count each separately and multiply results: #SAT(C1 C2) = #SAT(C1) * #SAT(C2) RelSat (Bayardo) – CL + component analysis at each node in search tree 50 variable #SAT State of the art circa 2000
, can count each separately and multiply results: #SAT(C1 C2) = #SAT(C1) * #SAT(C2) RelSat (Bayardo) – CL + component analysis at each node in search tree 50 variable #SAT State of the art circa 2000")
42
5. Formula Caching with Fahiem Bacchus, Paul Beame, Toni Pitassi, & Tian Sang

43
Formula Caching New idea: cache counts of residual formulas at each node Bacchus, Dalmao & Pitassi 2003 Beame, Impagliazzo, Pitassi, & Segerlind 2003 Matches time/space tradeoffs of best known exact probabilistic inference algorithms

44
#SAT with Component Caching #SAT(F) a = 1; a = 1; for each G to_components(F) { if (G == ) m = 1; else if ( G) m = 0; else if (in_cache(G)) m = cache_value(G); else { select v F; m = ½ * #SAT(G|v) + m = ½ * #SAT(G|v) + ½ * #SAT(G| v); ½ * #SAT(G| v); insert_cache(G,m);} insert_cache(G,m);} a = a * m; } return a;
 a = 1; a = 1; for each G to_components(F) { if (G == ) m = 1; else if ( G) m = 0; else if (in_cache(G)) m = cache_value(G); else { select v F; m = ½ * #SAT(G|v) + m = ½ * #SAT(G|v) + ½ * #SAT(G| v); ½ * #SAT(G| v); insert_cache(G,m);} insert_cache(G,m);} a = a * m; } return a;")
45
#SAT with Component Caching #SAT(F) a = 1; a = 1; for each G to_components(F) { if (G == ) m = 1; else if ( G) m = 0; else if (in_cache(G)) m = cache_value(G); else { select v F; m = ½ * #SAT(G|v) + m = ½ * #SAT(G|v) + ½ * #SAT(G| v); ½ * #SAT(G| v); insert_cache(G,m);} insert_cache(G,m);} a = a * m; } return a; Computes probability m that a random truth assignment satisfies the formula: # models = 2 m
 a = 1; a = 1; for each G to_components(F) { if (G == ) m = 1; else if ( G) m = 0; else if (in_cache(G)) m = cache_value(G); else { select v F; m = ½ * #SAT(G|v) + m = ½ * #SAT(G|v) + ½ * #SAT(G| v); ½ * #SAT(G| v); insert_cache(G,m);} insert_cache(G,m);} a = a * m; } return a; Computes probability m that a random truth assignment satisfies the formula: # models = 2 m")
46
Putting it All Together Goal: combine Clause learning Component analysis Formula caching to create a practical #SAT algorithm to create a practical #SAT algorithm Not quite as straightforward as it looks!

47
Issue 1: How Much to Cache? Everything Infeasible – 10 50 + nodes Only sub-formulas on current branch Linear space Fixed variable ordering + no clause learning == Recursive Conditioning (Darwiche 2002) Surely we can do better...
 Surely we can do better....")
48
Efficient Cache Management Ideal: make maximum use of RAM, but not one bit more Space & age-bounded caching Separate-chaining hash table Lazy deletion of entries older than K when searching chains Constant amortized time If sum of all chains becomes too large, do global cleanup Rare in practice

49
Issue 2: Interaction of Component Analysis & Clause Learning Without CL, sub-formulas decrease in size With CL, sub-formulas may become huge 1,000 clauses 1,000,000 learned clauses F F|p F|pF|p

50
Why this is a Problem Finding connected components at each node requires linear time Way too costly for learned clauses Components using learned clauses unlikely to reoccur Defeats purpose of formula caching

51
Suggestion Use only clauses derived from original formula for Component analysis “Keys” for cached entries Use all the learned clauses for unit propagation Can this possibly be sound? Almost!

52
Main Theorem Therefore: for SAT sub-formulas it is safe to use learned clauses for unit propagation! F| G| A2A1A3

53
UNSAT Sub-formulas But if F| is unsatisfiable, all bets are off... Without component caching, there is still no problem – because the final value is 0 in any case With component caching, could cause incorrect values to be cached Solution Flush siblings (& their descendents) of unsat components from cache
 of unsat components from cache.")
54
#SAT CC+CL #SAT(F) a = 1; s = ; for each G to_components(F) { if (in_cache(G)) { m = cache_value(G);} else{ m = split(G); insert_cache(G,m); insert_cache(G,m); a = a * m; a = a * m; if (m==0) { flush_cache(s); if (m==0) { flush_cache(s); break; } break; } else s = s {G}; else s = s {G}; }} }} return a;
 a = 1; s = ; for each G to_components(F) { if (in_cache(G)) { m = cache_value(G);} else{ m = split(G); insert_cache(G,m); insert_cache(G,m); a = a * m; a = a * m; if (m==0) { flush_cache(s); if (m==0) { flush_cache(s); break; } break; } else s = s {G}; else s = s {G}; }} }} return a;")
55
#SAT CC+CL continued split(G) if (G == ) return 1; if ( G) { learn_new_clause() return 0; } select v G; return ½ * #SAT(G|v) + ½ * #SAT(G| v);
 if (G == ) return 1; if ( G) { learn_new_clause() return 0; } select v G; return ½ * #SAT(G|v) + ½ * #SAT(G| v);")
56
Results: Pebbling Formulas 30 layers = 930 variables, 1771 clauses

57
Results: Planning Problems

58
Results: Circuit Synthesis

59
Random 3-SAT

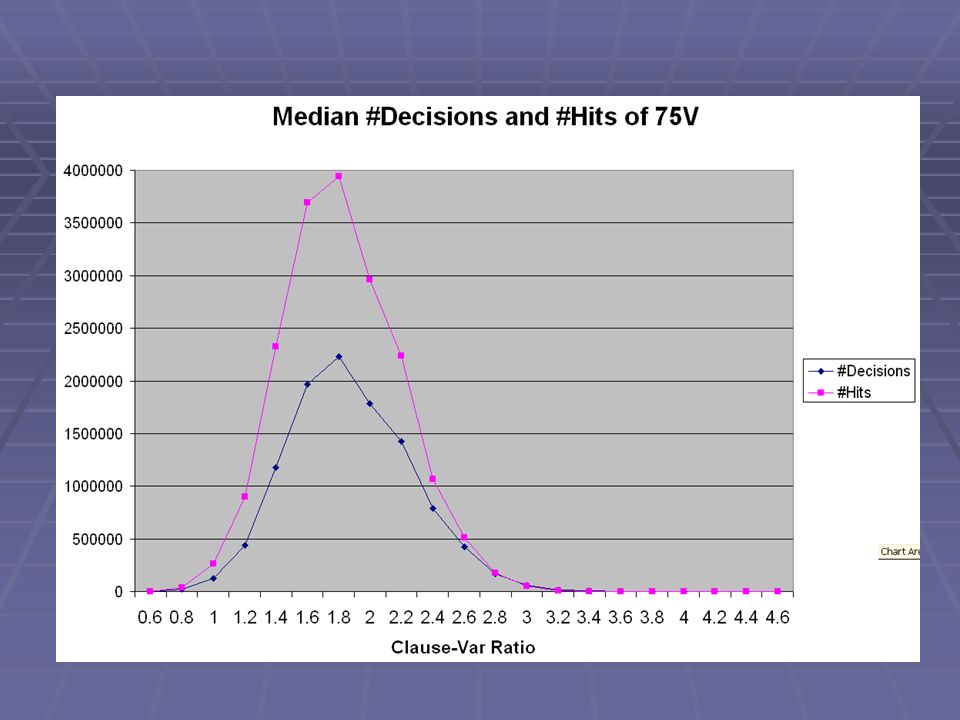
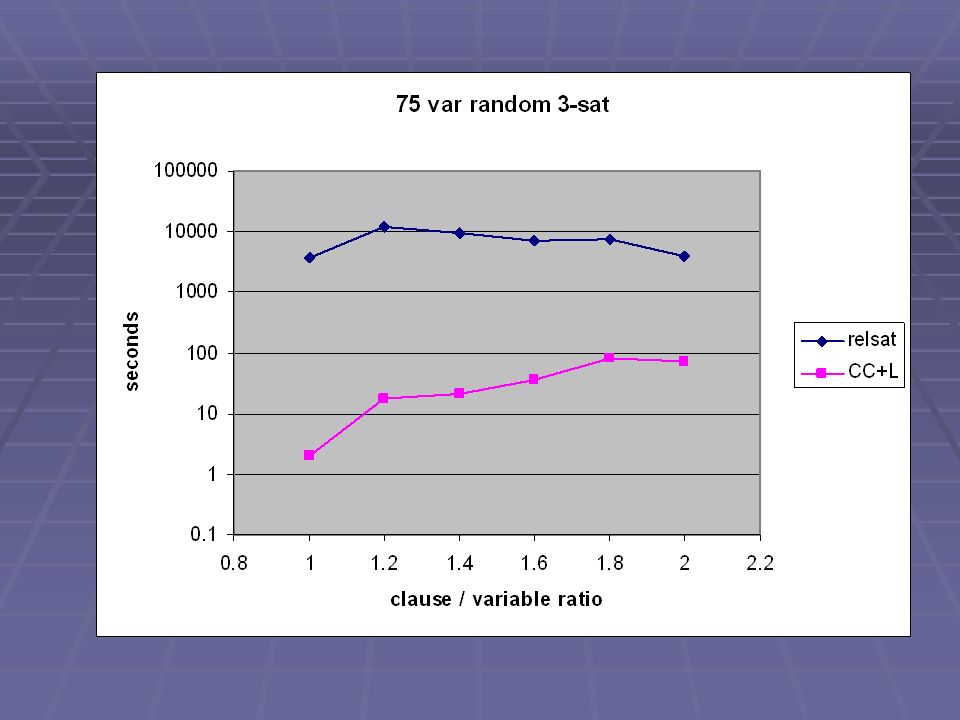
62
Summary Dramatic progress in automating propositional inference over last decade Progress due to the careful refinement of a handful of ideas – DPLL, clause learning, restarts, component analysis, formula caching The successful unification of these elements for #SAT gives renewed hope for a universal reasoning engine!

63
What’s Next? Evaluation of weighted-#SAT version on Bayesian networks Better component ordering and component-aware variable branching heuristics Optimal restart policies for #SAT CC+CL Adapt techniques for sampling methods – approximate inference???

Similar presentations





 two kinds: Application of inference rules: Legitimate (sound)>")







 A.I. Planning problems: can we reach a desired state in k steps? Verification of safety properties:>")

 two kinds: –Application of inference rules Legitimate (sound) generation of new sentences from old Proof.>")



