Download presentation
Presentation is loading. Please wait.

1
MURI Meeting July 2002 Gert Lanckriet ( gert@eecs.berkeley.edu ) gert@eecs.berkeley.edu L. El Ghaoui, M. Jordan, C. Bhattacharrya, N. Cristianini, P. Bartlett U.C. Berkeley Convex Optimization in Machine Learning

3
QP LP QCQP SDP SOCP Advanced Convex Optimization in Machine Learning

5
Linear Programming (LP)
")
6
Quadratic Programming (QP)
")
7
Quadratic Constrained Quadratic Programming (QCQP)
")
8
Second Order Cone Programming (SOCP)
")
9
Semi-Definite Programming

10
Advanced Convex Optimization in Machine Learning

11
MPM: Problem Sketch (1) a T z = b : decision hyperplane
 a T z = b : decision hyperplane")
12
MPM: Problem Sketch (2)
")
13
MPM: Problem Sketch (3) Probability of misclassification… … for worst-case class- conditional density… … should be minimized !
 Probability of misclassification… … for worst-case class- conditional density… … should be minimized !")
14
MPM: Main Result (1) Marshall & Olkin / Popescu & Bertsimas ??
 Marshall & Olkin / Popescu & Bertsimas")
15
MPM: Main Result (2)
")
16
Lemma MPM: Main Result (3)
")
17
MPM: Main Result (4) Lemma Probabilistic Constraint Deterministic Constraint
 Lemma Probabilistic Constraint Deterministic Constraint")
18
MPM: Main Result (5)
")
19
MPM: Geometric Interpretation

20
MPM: Link with FDA (1)
")
21
MPM: Link with FDA (2)
")
22
MPM: Link with FDA (3)
")
23
Robustness to Estimation Errors: Robust MPM (R-MPM)
")
26
MPM: Convex Optimization to solve the problem Linear Classifier Nonlinear Classifier Kernelizing Convex Optimization: Second Order Cone Program (SOCP) ) competitive with Quadratic Program (QP) SVMs Lemma
 ) competitive with Quadratic Program (QP) SVMs Lemma")
27
MPM: Empirical results =1– and TSA (test-set accuracy) of the MPM, compared to BPB (best performance in Breiman's report (Arcing classifiers, 1996)) and SVMs. (averages for 50 random partitions into 90% training and 10% test sets) Comparable with existing literature, SVMs = 1- is indeed smaller than the test-set accuracy in all cases (consistent with as worst-case bound on probability of misclassification) Kernelizing leads to more powerfull decision boundaries ( linear decision boundary < nonlinear decision boundary (Gaussian kernel) )
 Comparable with existing literature, SVMs = 1- is indeed smaller than the test-set accuracy in all cases (consistent with as worst-case bound on probability of misclassification) Kernelizing leads to more powerfull decision boundaries ( linear decision boundary < nonlinear decision boundary (Gaussian kernel) ).")
28
Conclusions

29
Future directions

30
Advanced Convex Optimization in Machine Learning

31
The idea (1) Machine learning Kernel-based machine learning
 Machine learning Kernel-based machine learning")
32
The idea (2)
")
33
The idea (3)
")
34
training set (labelled) test set (unlabelled) The idea (4)
 test set (unlabelled) The idea (4)")
35
The idea (5)
")
36
Hard margin SVM classifiers (1)
")
37
Hard margin SVM classifiers (2)
")
38
Hard margin SVM classifiers (3)
")
39
Hard margin SVM classifiers (4)
")
40
SDP ! Hard margin SVM classifiers (5)
")
41
Optimization Learning the kernel matrix ! Learning Hard margin SVM classifiers (6)
")
42
training set (labelled) test set (unlabelled) Learning the kernel matrix ! Hard margin SVM classifiers (7)
.")
43
? Hard margin SVM classifiers (8)
")
44
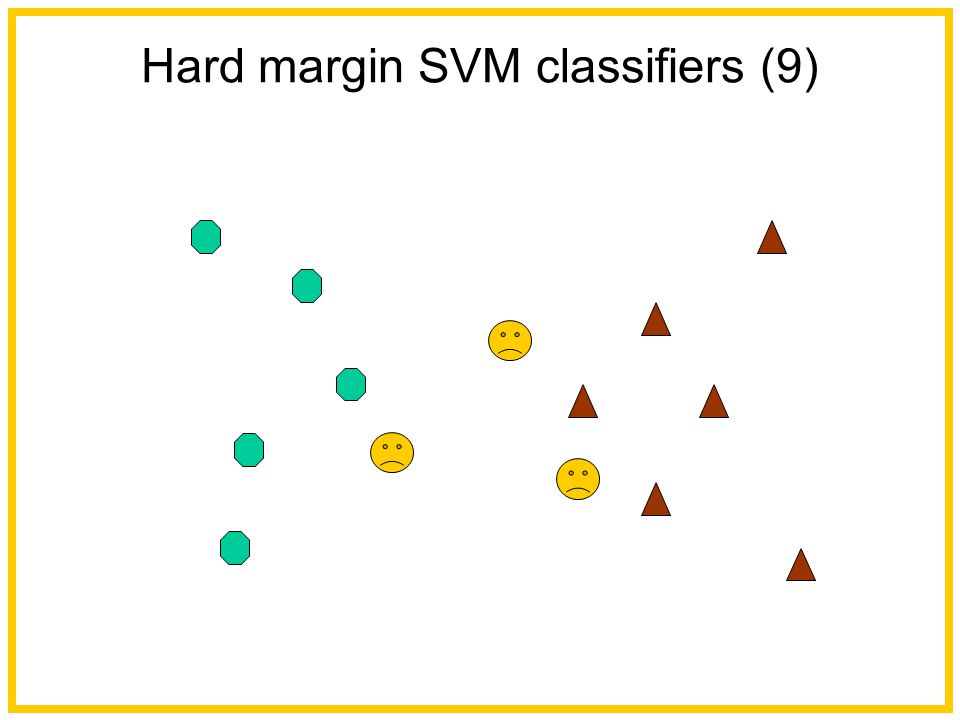
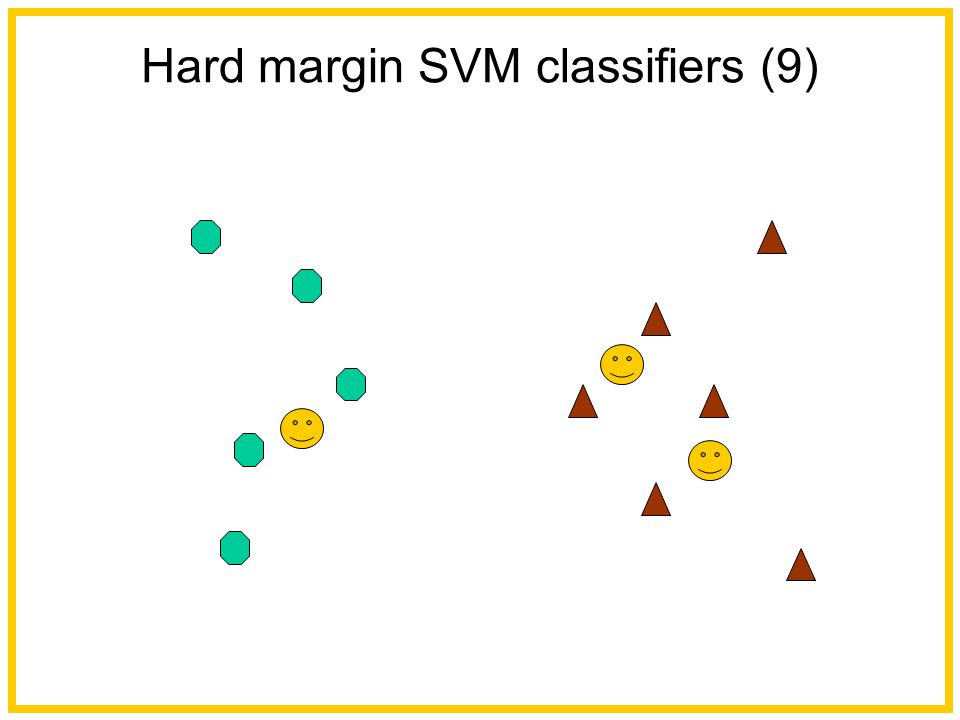
Hard margin SVM classifiers (9)
")
47
Hard margin SVM classifiers (10)
")
48
Hard margin SVM classifiers (11) Learning Kernel Matrix with SDP !
 Learning Kernel Matrix with SDP !")
49
Empirical results hard margin SVMs

50
Conclusions and future directions

52
See also

Similar presentations





>")













 Weijia Wang, Huanren Zhang, Vijendra Purohit, Aditi Gupta.>")
 Chapter 5 (Duda et al.)>")

 The hyperplanethat solves the minimization problem: realizes the maximal margin hyperplane.>")

