Download presentation
Presentation is loading. Please wait.

1
Fuzzy Support Vector Machines (FSVMs) Weijia Wang, Huanren Zhang, Vijendra Purohit, Aditi Gupta
 Weijia Wang, Huanren Zhang, Vijendra Purohit, Aditi Gupta")
2
Outline Review of SVMs Formalization of FSVMs Training algorithm for FSVMs Noisy distribution model Determination of heuristic function Experiment results

3
SVM – brief review Classification technique Method: Maps points into high-dimensional feature space Finds a separating hyperplane that maximizes the margin

4
Set S of labeled training points: Each point belongs to one of the two classes, Let be feature space vector, with mapping from to feature space Then equation of hyperplane: For linearly separable data, Optimization problem: Subject to

5
For non-linearly separable data (soft margin), introduce slack variables Optimization problem: -> some measure of amount of misclassifications Limitation: All training points are treated equal
, introduce slack variables Optimization problem: -> some measure of amount of misclassifications Limitation: All training points are treated equal")
6
FSVM – Fuzzy SVM each training point belongs exactly to no more than one class some training points are more important than others- these meaningful data points must be classified correctly (even if some noisy, less important points, are misclassified). Fuzzy membership: s i : how much point x i belongs to one class (amount of meaningful information in the data point) : amount of noise in the data point
 : amount of noise in the data point.")
7
Set S of labeled training points: Optimization problem: large C -> narrower margin, less misclassifications - Regularization constant

8
Lagrange function: Taking derivatives:

9
Optimization problem: Kuhn-Tucker conditions : λ – lagrange multiplier g(x) – inequality constraint
 – inequality constraint")
10
Points with are support vectors (lie on red boundary). => Points with same could be different types of support vectors in FSVM due to => SVM – one free parameter (C) FSVM - number of free params = C, s i (~ number of training points) lies on margin of hyperplane Two types of support vectors: misclassified if > 1
 FSVM - number of free params = C, s i (~ number of training points) lies on margin of hyperplane Two types of support vectors: misclassified if > 1.")
11
Training algorithm for FSVMs Objective function for optimization Minimization of the error function Maximization of the margin The balance is controlled by tuning C

12
Selection of error function Least absolute value in SVMs Least square value in LS-SVMs Suykens and Vanewalle, 1999 Suykens and Vanewalle, 1999 the QP is transformed to solving a linear system the QP is transformed to solving a linear system the support values are mostly nonzero the support values are mostly nonzero

13
Selection of error function maximum likelihood method when the underlying error probability can be estimated optimization problem becomes

14
Maximum likelihood error limitation the precision of estimation of hyperplane depends on estimation of error function the estimation of error is reliable only when the underlying hyperplane is well estimated

15
Selection of error function Weighted least absolute value each data is associated with a cost or importance factor when the noise distribution model of data given p x (x) is the probability that point x is not a noise optimization becomes
 is the probability that point x is not a noise optimization becomes")
16
Weighted least absolute value Relation with FSVMs take p x (x) as a fuzzy membership, i.e p x (x) = s
 as a fuzzy membership, i.e p x (x) = s")
17
Selection of max margin term Generalized optimal plane (GOP) Robust linear programming(RLP)
 Robust linear programming(RLP)")
18
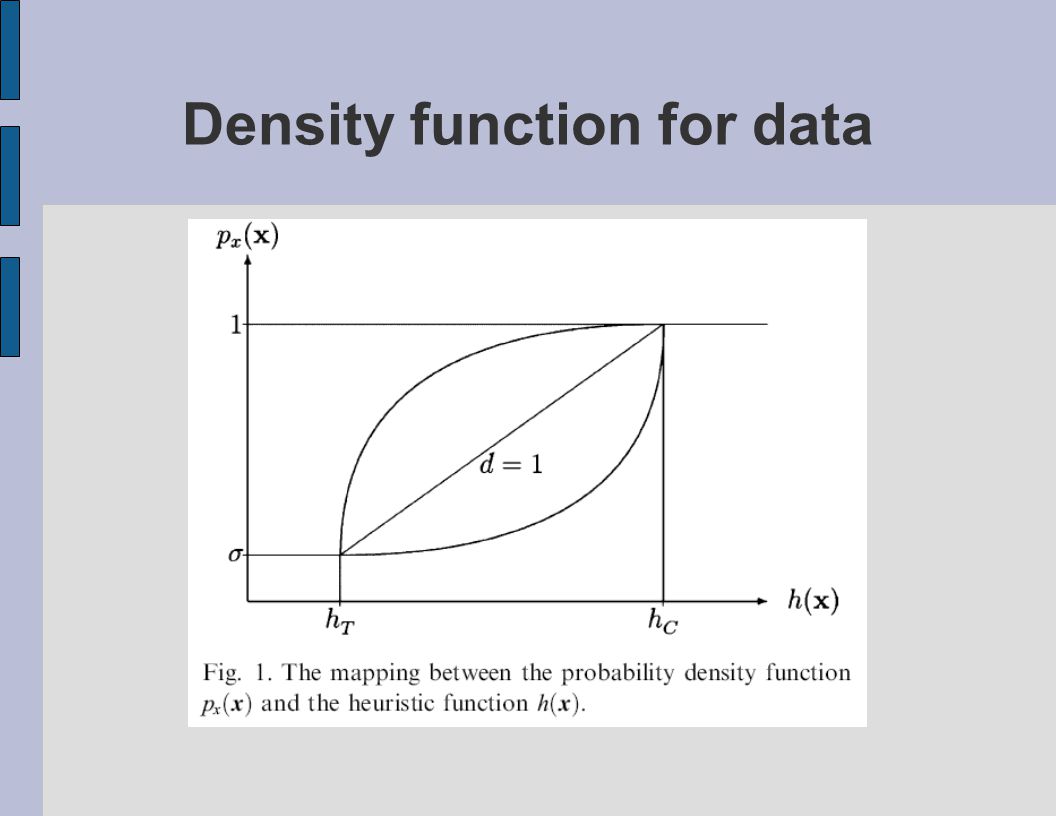
Implementation of NDM Goal build a probability distribution model for data Ingredients a heuristic function: highly relevant to p x (x) confident factor: h C trashy factor: h T
 confident factor: h C trashy factor: h T")
19
Density function for data

21
Heuristic function Kernel-target alignment K-nearest neighbors Basic idea: Outliers have higher probability to be noise

22
Kernel-target alignment Measurement of how likely the point x i is noise.

23
K-nearest neighbors: example Gaussian kernel can be written as the cosine of the angel between two vectors in the feature space

24
The outlier data point x i will have smaller value of f K (x i,y i ) Use f K (x,y) as a heuristic function h(x)
 Use f K (x,y) as a heuristic function h(x)")
25
K-nearest neighbors (k-NN) For each x i, the set S i k consists k nearest neighbors of x i n i is the number of data points in the set S i k that the class label is the same as the class label of data point x i Heuristic function h(x i )=n i
 For each x i, the set S i k consists k nearest neighbors of x i n i is the number of data points in the set S i k that the class label is the same as the class label of data point x i Heuristic function h(x i )=n i")
26
Comparison of two heuristic function Kernel-target alignment Operate in the feature space, use the information of all data points to determine the heuristic for one point k-NN Operate in the original space, use the information of k data points to determine the heuristic for one point How about combine them two?!

27
Overall Procedure for FSVMs 1. Use SVM algorithm to get the optimal kernel parameters and the regularization parameter C 2. Fix the kernel parameters and the regularization parameter C, determine heuristic function h(x), and use exhaustive search to choose the confident factor h c and trashy factor h T, mapping degree d and the fuzzy membership lower bound σ
, and use exhaustive search to choose the confident factor h c and trashy factor h T, mapping degree d and the fuzzy membership lower bound σ.")
28
Experiments Data with time property

29
SVM results for data with time property FSVM results for data with time property

30
Experiments Two classes with different weighting

31
Results from SVM Results from FSVM

32
Experiments Using class center to reduce effect of outliers.

33
Results from SVM Results from FSVM

34
Experiments (setting fuzzy membership) Kernel Target Alignment Two step strategy Fix f UB k and f LB k as following: f UB k = max i f k (x i, yi ) and f LB k = min i f k (x i, yi ) Find σ and d using a two-dimensional search. Now, find f UB k and f LB k

35
Experiments (setting fuzzy membership) k-Nearest Neighbor Perform a two-dimensional search for parameters σ and k. k UB = k/2 and d=1 are fixed.

36
Experiments Comparison of results from KTA and k-NN with other classifiers (Test Errors)
")
37
Conclusion FSVMs work well when the average training error is high, which means it can improve performance of SVMs for noisy data. No. of free parameters for FSVMs is very high C, s i for each data point. Results using KTA and k-NN are similar but KTA is more complicated and takes more time to find optimal values of parameters. This papers studies FSVMs only for two classes, multi-class scenarios are not explored.

Similar presentations
>")
>")











>")
 Chapter 5 (Duda et al.)>")

 Each record contains a set of attributes, one of the attributes is the class.>")
>")

