Download presentation
Presentation is loading. Please wait.

1
N.U.S. - January 13, 2006 Gert Lanckriet (gert@ece.ucsd.edu) U.C. San Diego Classification problems with heterogeneous information sources

2
Motivation Statistical machine learning –Blends statistics, computer science, signal processing, optimization –Involves solving large-scale data analysis problems autonomously in tandem with a human Challenges: –Massive scale of data sets –On-line issues –Diversity of information sources describing data

3
Example: web-related applications Data point = web page Sources of information about the webpage: –Content: Text Images Structure Sounds –Relation to other webpages: links network –Users (log data): click behavior origin
: click behavior origin")
4
Example: web-related applications Data point = web page Sources of information about the webpage: –Content: Text Images Structure Sounds –Relation to other webpages: links network –Users (log data): click behavior origin Information in diverse (heterogeneous) formats
: click behavior origin Information in diverse (heterogeneous) formats")
5
Example: bioinformatics mRNA expression data upstream region data (TF binding sites) protein-protein interaction data hydrophobicity data sequence data (gene, protein)
 protein-protein interaction data hydrophobicity data sequence data (gene, protein)")
6
Overview Kernel methods Classification problems Kernel methods with heterogeneous information Classification with heterogeneous information (SDP) Applications in computational biology
 Applications in computational biology")
7
Overview Kernel methods Classification problems Kernel methods with heterogeneous information Classification with heterogeneous information (SDP) Applications in computational biology
 Applications in computational biology")
8
Kernel-based learning Linear algorithm SVM, MPM, PCA, CCA, FDA… Data Embed data x1x1 xnxn if data described by numerical vectors: embedding ~ (non-linear) transformation non-linear versions of linear algorithms
 transformation non-linear versions of linear algorithms")
9
Kernel-based learning Linear algorithm SVM, MPM, PCA, CCA, FDA… Data Embed data x1x1 xnxn embedding can be defined for non-vector data

10
Kernel-based learning Embed data K i j IMPLICITLY: Inner product measures similarity Property: Any symmetric positive definite matrix specifies a kernel matrix & every kernel matrix is symmetric positive definite

11
Kernel-based learningData Embed data x1x1 xnxn

12
Kernel-based learning Data Embed data Linear algorithm SVM, MPM, PCA, CCA, FDA… Kernel design Kernel algorithm K x1x1 xnxn

13
Kernel methods Unifying learning framework –connections to statistics, convex optimization, functional analysis –different data analysis problems can be formulated within this framework Classification Clustering Regression Dimensionality reduction Many successful applications

14
Kernel methods Unifying learning framework –connections to statistics, convex optimization, functional analysis –different data analysis problems can be formulated within this framework Many successful applications –hand-writing recognition –text classification –analysis of micro-array data –face detection –time series prediction

15
Training data: {(x i,y i )} i=1...n –x i : description i th object –y i 2 {-1,+1} : label Binary classification Problem: design a classification rule such that, given a new x, it predicts y with minimal probability of error HEART URINE DNA BLOOD SCAN HEART URINE DNA BLOOD SCAN x1x1 x2x2 y 1 = -1y 2 = +1
} i=1...n –x i : description i th object –y i 2 {-1,+1} : label Binary classification Problem: design a classification rule such that, given a new x, it predicts y with minimal probability of error HEART URINE DNA BLOOD SCAN HEART URINE DNA BLOOD SCAN x1x1 x2x2 y 1 = -1y 2 = +1")
16
Find hyperplane that separates the two classes Binary classification HEART URINE DNA BLOOD SCAN x1x1 HEART URINE DNA BLOOD SCAN x2x2 Classification Rule:

17
Maximal margin classification Maximize margin: –Position hyperplane between two classes –Such that 2-norm distance to closest point from each class is maximized

18
If not linearly separable: –Allow some errors –Try to maximize margin for data points with no error Maximal margin classification

19
max margin min error correctly classified error slack Maximal margin classification: training algorithm

20
Training: convex optimization problem (QP) Dual problem: Maximal margin classification
 Dual problem: Maximal margin classification")
21
Training: convex optimization problem (QP) Dual problem: Optimality condition: Maximal margin classification
 Dual problem: Optimality condition: Maximal margin classification")
22
Training: Classification rule: classify new data point x: Maximal margin classification

23
Training: Classification rule: classify new data point x: Maximal margin classification

24
Kernel-based classification Data Embed data Linear classification algorithm Support vector machine (SVM) Kernel design Kernel algorithm K x1x1 xnxn
 Kernel design Kernel algorithm K x1x1 xnxn")
25
Overview Kernel methods Classification problems Kernel methods with heterogeneous information Classification with heterogeneous information (SDP) Applications in computational biology
 Applications in computational biology")
26
Kernel methods with heterogeneous info Data points: proteins Information sources: K i j

27
Kernel methods with heterogeneous info Data points: proteins Information sources: K

28
Kernel methods with heterogeneous data Proposed approach –First focus on every single source j of information individually –Extract relevant information from source j into K j –Design algorithm to learn the optimal K, by “mixing” any number of kernel matrices K j, for a given learning problem

29
Kernel methods with heterogeneous data 1 K 2

30
Proposed approach –First focus on every single source k of information individually –Extract relevant information from source j into K j –Design algorithm that learns the optimal K, by “mixing” any number of kernel matrices K j, for a given learning problem Focus on kernel design for specific types of information Flexibility Can ignore information irrelevant for learning task Homogeneous, standardized input 1 2

31
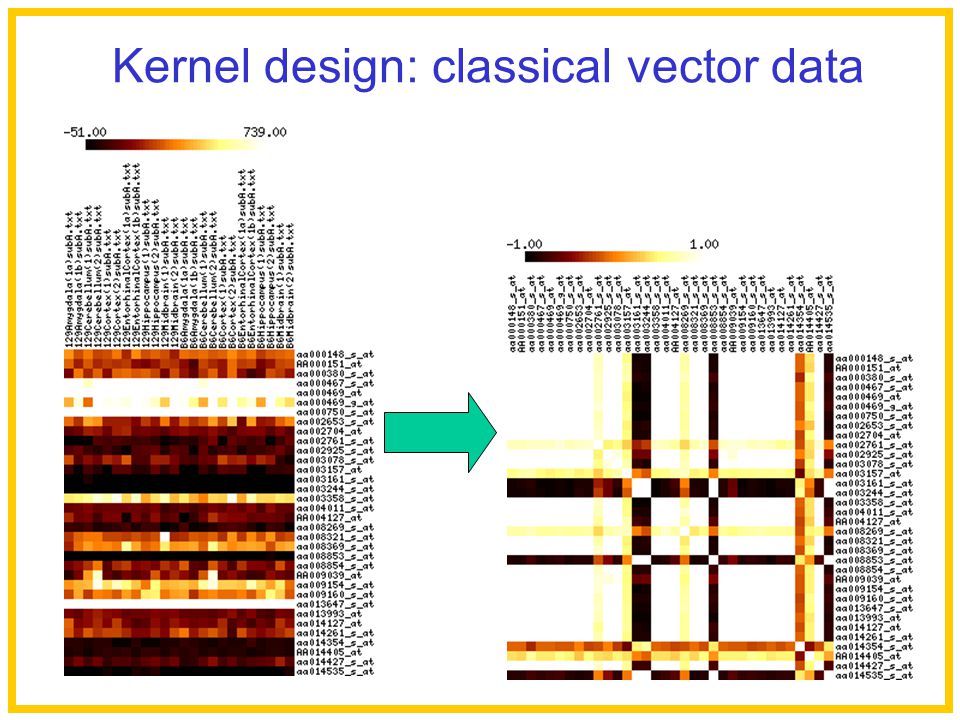
Data matrix: –each row corresponds to a gene (data point) –each column corresponds to an experiment (mRNA expression level) Each gene: described by vector of numbers Kernel design: classical vector data
 –each column corresponds to an experiment (mRNA expression level) Each gene: described by vector of numbers Kernel design: classical vector data")
32
Inner product : Normalized inner product : Similar Dissimilar Kernel design: classical vector data

33
A more advanced similarity measurement for vector data: Gaussian kernel Corresponds to highly non-linear embedding Kernel design: classical vector data

35
>ICYA_MANSE GDIFYPGYCPDVKPVNDFDLSAFAGAWHEIAKLPLENENQGKCTIAEYKY DGKKASVYNSFVSNGVKEYMEGDLEIAPDAKYTKQGKYVMTFKFGQRVVN LVPWVLATDYKNYAINYMENSHPDKKAHSIHAWILSKSKVLEGNTKEVVD NVLKTFSHLIDASKFISNDFSEAACQYSTTYSLTGPDRH >LACB_BOVIN MKCLLLALALTCGAQALIVTQTMKGLDIQKVAGTWYSLAMAASDISLLDA QSAPLRVYVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTKIPAVFKI DALNENKVLVLDTDYKKYLLFCMENSAEPEQSLACQCLVRTPEVDDEALE KFDKALKALPMHIRLSFNPTQLEEQCHI Data points: proteins Described by variable-length, discrete strings (amino acid sequences) Kernel design: derive valid similarity measure, based on non-vector information Kernel design: strings protein 1 protein 2
 Kernel design: derive valid similarity measure, based on non-vector information Kernel design: strings protein 1 protein 2")
36
>ICYA_MANSE GDIFYPGYCPDVKPVNDFDLSAFAGAWHEIAKLPLENENQGKCTIAEYKY DGKKALVLDTDVSNGVKEYMENSLEIAPDAKYTKQGKYVMTFKFGQRVVN LVPWVLATDYKNYAINYNCDYHPDKKAHSIHAWILSKSKVLEGNTKEVVD NVLKTFSHLIDASKFISNDFSEAACQYSTTYSLTGPDRH >LACB_BOVIN MKCLLLALALTCGAQALIVTQTMKGLDIQKVAGTWYSLAMAASDISLLDA QSAPLRVYVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTKIPAVFKI DALNENKVLVLDTDYKKYLLFCMENSAEPEQSLACQCLVKYVNTFKEALE KFDKALKALPMHIRLSFNPTQLEEQCHI Kernel design: strings >ICYA_JAKSE GDIFYPGYCPDVKPVNDFDLSAFAGAWHEIAKLPLENENQGKCTIAEYKY DGKKASVYNSFVSNGVKEYMEGDLEIAPDAKYTKQGKYVMTFKFGQRVVN LVPWVLATDYKNYAINYNCDYHPDKKAHSIHAWILSKSKVLEGNTKEVVD NVLKTFSHLIDASKFISNDFSEAACQYSTTYSLTGPDRH >LACB_BOVIN MKCLLLALALTCGAQALIVTQTMKGLDIQKVAGTWYSLAMAASDISLLDA QSAPLRVYVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTKIPAVFKI DALNENKVLVLDTDYKKYLDYCMENSAEPEQSLACQCLVRTPEVDDEALE KFDKALKALPMHIRLSFNPTQLEEQCHI more similar String kernels less similar

37
Diffusion kernel: establishes similarities between vertices of a graph, based on the connectivity information –based upon a random walk –efficiently accounts for all paths connecting two vertices, weighted by path lengths Data points: vertices Information: connectivity described by graph Kernel design: graph

38
Kernel methods with heterogeneous data 1 K 2 ?

39
Learning the kernel matrix K ?? Any symmetric positive definite matrix specifies a kernel matrix Define cost function to assess the quality of a kernel matrix Positive semidefinite matrices form a convex cone Restrict to convex cost functions Learn K from the convex cone of positive-semidefinite matrices… … according to a convex quality measure

40
Learning the kernel matrix K ? Learn K from the convex cone of positive-semidefinite matrices… ? … according to a convex quality measure Semidefinite Programming (SDP) : deals with optimizing convex cost functions over the convex cone of positive semidefinite matrices (or a convex subset of it)
 : deals with optimizing convex cost functions over the convex cone of positive semidefinite matrices (or a convex subset of it).")
41
K Integrate constructed kernels Large margin classifier (SVM) ? Learn K from the convex cone of positive-semidefinite matrices (or a convex subset) … ? … according to a convex quality measure Classification with multiple kernels
 … . … according to a convex quality measure Classification with multiple kernels.")
42
K Integrate constructed kernels learn a linear combination Large margin classifier (SVM) ? Learn K from the convex cone of positive-semidefinite matrices (or a convex subset) … ? … according to a convex quality measure Classification with multiple kernels
 … . … according to a convex quality measure Classification with multiple kernels.")
43
K Large margin classifier (SVM) maximize the margin ? Learn K from the convex cone of positive-semidefinite matrices (or a convex subset) … ? … according to a convex quality measure Classification with multiple kernels Integrate constructed kernels learn a linear combination
 … . … according to a convex quality measure Classification with multiple kernels Integrate constructed kernels learn a linear combination.")
44
SVM, one kernel, dual formulation SVM, multiple kernels, dual formulation Classification with multiple kernels Convex (pointwise max of set of convex functions) Semidefinite programming problem
 Semidefinite programming problem")
45
SVM, one kernel, dual formulation SVM, multiple kernels, dual formulation Classification with multiple kernels Need to reformulate this in standard SDP format

46
Integrate constructed kernels learn a linear mix Large margin classifier (SVM) maximize the margin SDP (standard form) Classification with multiple kernels
 maximize the margin SDP (standard form) Classification with multiple kernels")
47
Integrate constructed kernels learn a linear mix Large margin classifier (SVM) maximize the margin Theoretical performance guarantees Classification with multiple kernels
 maximize the margin Theoretical performance guarantees Classification with multiple kernels")
48
Yeast membrane protein prediction Yeast protein function prediction Applications in computational biology

49
Yeast Membrane Protein Prediction Membrane proteins: –anchor in various cellular membranes –serve important communicative functions across the membrane –important drug targets About 30% of the proteins are membrane proteins

50
Protein sequences: SW scores Protein sequences: BLAST scores E-values of Pfam domains Protein-protein interactions mRNA expression profiles Hydropathy profile Yeast Membrane Protein Prediction Diffusion Gaussian

51
Protein sequences: SW scores Protein sequences: BLAST scores E-values of Pfam domains Protein-protein interactions mRNA expression profiles Hydropathy profile Yeast Membrane Protein Prediction K

53
Five different types of data: –Pfam domains –genetic interactions (CYGD) –physical interactions (CYGD) –protein-protein interaction (TAP) –mRNA expression profiles Compare our approach to approach using Markov Random Fields (Deng et al.) –using the five types of data –also reporting improved accuracy compared to using any single data type Yeast Protein Function Prediction
 –physical interactions (CYGD) –protein-protein interaction (TAP) –mRNA expression profiles Compare our approach to approach using Markov Random Fields (Deng et al.) –using the five types of data –also reporting improved accuracy compared to using any single data type Yeast Protein Function Prediction")
54
MRF SDP/SVM (binary) SDP/SVM (enriched) Yeast Protein Function Prediction
 SDP/SVM (enriched) Yeast Protein Function Prediction")
55
Conclusion Computational and statistical framework to integrate data from heterogeneous information sources –flexible and unified approach –within kernel methodology –specifically: classification problems –resulting formulation: semidefinite programming Applications show classification performance can be enhanced by integrating diverse genome-wide information sources

Similar presentations




 of the slides are taken from Prof.>")






 Lab University of Maryland Baltimore County.>")








