Download presentation
Presentation is loading. Please wait.

1
Spatio-Temporal Relationship Match: Video Structure Comparison for Recognition of Complex Human Activities M. S. Ryoo and J. K. Aggarwal ICCV2009

2
Introduction Human activity recognition, an automated detection of ongoing activities from video is an important problem. This technology can use on surveillance systems, robots, human-computer interface. When using on serveillance systems,automaically detect violent activities is very important.

3
Introduction Spatial-temporal feature-based approaches have been proposed by many researchers. The method above have benn successful on short video containing simple action such as walking and waving. In real-world applications, actions and activities are seldom like this.

4
Related works Methods focused on tracking persons and bodies are developed [4,11],but their results rely on background subtraction. Approaches that analyze a 3-S XYT volume gained particular in past few years[3,5,6,9,13,16], they extracted relationship on features and trained a model.
![Related works Methods focused on tracking persons and bodies are developed [4,11],but their results rely on background subtraction.](http://images.slideplayer.com/7/1664394/slides/slide_4.jpg "Approaches that analyze a 3-S XYT volume gained particular in past few years[3,5,6,9,13,16], they extracted relationship on features and trained a model..")
5
[3] P. Dollar, V. Rabaud, G. Cottrell, and S. Belongie. Behaviorrecognition via sparse spatio- temporal features. In IEEEInternational Workshop on VS-PETS, pages 65–72, 2005. [4] S. Hongeng, R. Nevatia, and F. Bremond. Video-based eventrecognition: activity representation and probabilistic recognitionmethods. CVIU, 96(2):129–162, 2004. [5] H. Jhuang, T. Serre, L. Wolf, and T. Poggio. A biologicallyinspired system for action recognition. In ICCV, 2007. [6] I. Laptev, M. Marszalek, C. Schmid, and B. Rozenfeld.Learning realistic human actions from movies. In CVPR,2008. [9] J. C. Niebles, H. Wang, and L. Fei-Fei. Unsupervised learning of human action categories using spatial-temporal words. IJCV, 79(3), Sep 2008. [11] M. S. Ryoo and J. K. Aggarwal. Semantic representation and recognition of continued and recursive human activities. IJCV, 82(1):1–24, April 2009. [13] C. Schuldt, I. Laptev, and B. Caputo. Recognizing humanactions: a local svm approach. In ICPR, 2004. [16] S.-F. Wong, T.-K. Kim, and R. Cipolla. Learning motion categories using both semantic and structural information. In CVPR, 2007.
![[3] P. Dollar, V. Rabaud, G. Cottrell, and S. Belongie.](http://images.slideplayer.com/7/1664394/slides/slide_5.jpg "Behaviorrecognition via sparse spatio- temporal features. In IEEEInternational Workshop on VS-PETS, pages 65–72, [4] S. Hongeng, R. Nevatia, and F. Bremond. Video-based eventrecognition: activity representation and probabilistic recognitionmethods. CVIU, 96(2):129–162, [5] H. Jhuang, T. Serre, L. Wolf, and T. Poggio. A biologicallyinspired system for action recognition. In ICCV, [6] I. Laptev, M. Marszalek, C. Schmid, and B. Rozenfeld.Learning realistic human actions from movies. In CVPR,2008. [9] J. C. Niebles, H. Wang, and L. Fei-Fei. Unsupervised learning of human action categories using spatial-temporal words. IJCV, 79(3), Sep [11] M. S. Ryoo and J. K. Aggarwal. Semantic representation and recognition of continued and recursive human activities. IJCV, 82(1):1–24, April [13] C. Schuldt, I. Laptev, and B. Caputo. Recognizing humanactions: a local svm approach. In ICPR, [16] S.-F. Wong, T.-K. Kim, and R. Cipolla. Learning motion categories using both semantic and structural information. In CVPR,")
6
Related works In this paper, we propose a new spatial- temporal feature-based methodology. Kernel functions are built on relationship between features. After training features, match function uses for matching test data.

7
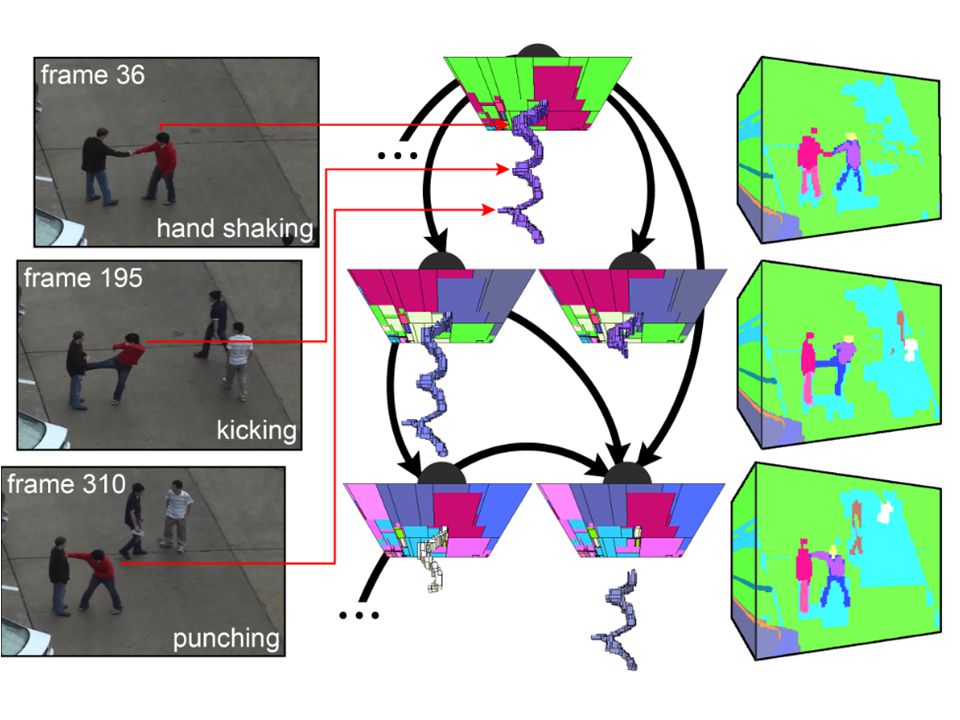
Example matching result

8
Spatio-temporal relationship match The method is based on matching two videos and output a real number for result. K : V x V R V -> input video, R-> result

9
Features and their relations A spatial-temporal feature extractor [3,14]detects each interest point locating a salient change.
![Features and their relations A spatial-temporal feature extractor [3,14]detects each interest point locating a salient change.](http://images.slideplayer.com/7/1664394/slides/slide_9.jpg "Features and their relations A spatial-temporal feature extractor [3,14]detects each interest point locating a salient change.")
11
Features and their relations f= (f des,f loc ) f des ->descriptor,f loc -> 3-D coordinate The features are clustered into k types using k-means on f des.
 f des ->descriptor,f loc -> 3-D coordinate The features are clustered into k types using k-means on f des.")
12
Features and their relations Each f loc have n elements, f 1 loc,…..f n loc. There are types to describe temporal relations:

13
Features and their relations Spatial relation are described below:

15
Features and their relations

16
Human activity recognition Our system maintains one training dataset D α per activity α. Let D α m extracted from mth training video in the set D α, then use the matching function.

17
Localization

18
Hierarchical recognition We can combine low-level action into high- level action. For instance, hand-shake includes two sub- action, arm streching and arm withdrawing. Detecting hand-shake may like : st1 before wd1,st2 before wd2, st1 equals st2,wd1 equals wd2.

19
Experiments The dataset is UT-interaction dataset. The actions are performed by actors, each video contains shake hands,point,hug,push,kick and punch.

20
Experiments

22
Conclusion This method rely on the extracted feature and spatial-temporal relationship on features. Can hierarchically detect high-level actions. Miss-detect on unusual feature combination.

Similar presentations







 LIRIS (Lyon) (1/02/2014 -2018) Elisa Fromont,>")






>")
 Dept of Numerical Analysis and Computer Science KTH (Royal Institute.>")

![2.Our Framework 2.1. Enforcing Temporal Consistency by Post Processing Human Detection from Yang and Ramanan [1] Articulated Pose Estimation using Flexible.](/15/4546929/big_thumb.jpg "2.Our Framework 2.1. Enforcing Temporal Consistency by Post Processing Human Detection from Yang and Ramanan [1] Articulated Pose Estimation using Flexible.>")



