Download presentation
Presentation is loading. Please wait.

1
By: Ryan Wendel

2
It is an ongoing analysis in which videos are analyzed frame by frame Most of the video recognition is pulled from 3-D graphic engines

3
“HAA” stands for Human Activity Analysis Surveillance systems Patient monitoring systems Human-computer interfaces

4
We are going to take a look at methodologies that have been developed for simple human actions. And high-level activities.

5
Gestures Actions Interactions Group activities

6
Basic movements of a persons body parts. For example: Raising an arm Lifting a leg

7
A Single persons activities which could entail multiple gestures. For example: Walking Waving Shaking body

8
Interactions that involve two or more people / items. For Example: Two people fighting

9
Activities performed by multiple people. For example: A group running A group walking A group fighting

10
Can be separated into two sections ◦ Single-layered approaches: An approach that deals with recognizing human activities based on a video feed (frame by frame.) ◦ Hierarchical approaches: An approach aimed at describing the high level approach to HAA by showing high level activities in simpler terms.
 ◦ Hierarchical approaches: An approach aimed at describing the high level approach to HAA by showing high level activities in simpler terms.")
11
Main objective is to analyze simple sequences of movements of humans Can be categorized into two different categories ◦ Space-time approach: takes an input video as a 3- D volume ◦ Sequential approach: takes an input video and interprets it as a sequence of observations

12
Divided into three different subsections based on features ◦ Space-time volume ◦ Space-time Trajectories ◦ Space-time features

13
Captures a group of human activities by analyzing volumes of a video (frame by frame.) Also uses types of recognition using space- time volumes to measure similarities between two volumes
 Also uses types of recognition using space- time volumes to measure similarities between two volumes")
16
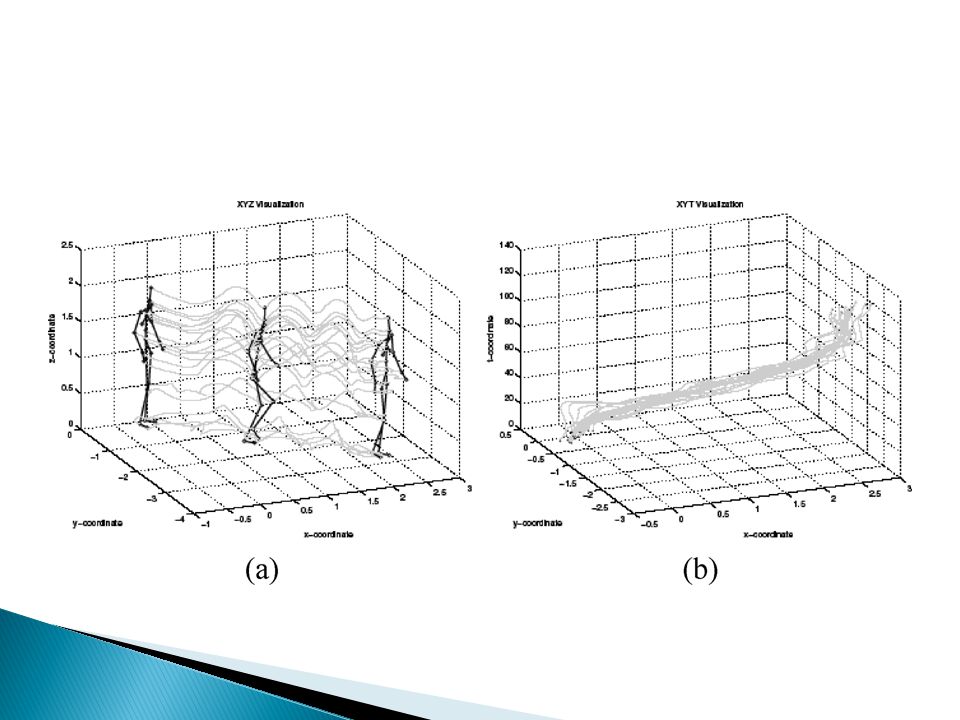
Uses stick figure modeling to extract joint positions of a person at each frame by frame

18
Does not extract features frame by frame Extracts features when there is a appearance or shape change in 3-D Space-time volume

20
Space-Time Volume ◦ Hard to differentiate between multiple people in the same scene. Space-Time Trajectories ◦ 3-D body-part detection and tracking is still an unsolved problem, and it requires a strong low- level component that can estimate 3-D join location. Space-Time features ◦ Not suitable for modeling complex activities

21
Divided into two different subsections based on features ◦ Exemplar-based ◦ State model-based

22
Review ◦ Sequential approach: takes an input video and interprets it as a sequence of observations Exemplar-based ◦ Shows human activities with a set of sample sequences of action executions

24
Sequential set of sequences that represent a human activity as a model composed of a set of states.

26
Exemplar-based is more flexible in terms of comparing multiple sample sequences Where as State Model-based can handle a probabilistic analysis of an activity better.

27
Sequential approach is able to handle and detect more complex activities performed Whereas the Space-time approach handles simpler less complex activities. Both methods are based off of some type of a sequences of images

28
Allows the recognition of high-level activities based on the recognition results of other simpler activities Advantages of the Hierarchical Approach ◦ Has the ability to recognize high-level activities with a more in depth structure ◦ Amount of data required to recognize an activity is significantly less then single-layered approach ◦ Easier to incorporate human knowledge

29
Statistical approach Syntactic approach Description-based approach

30
Statistical approaches use the state-based models to recognize activities If you use multiple layers of a state-based model you can use these separate models to recognize activities with sequential structures

32
Human activities are recognized as a string of symbols Human activities are shown as a set of production rules generating a string of actions

34
Human activities that use recognition with complex spatio-temporal structures ◦ A spatio-temporal structure is a detector used for recognizing human actions Uses Context-free grammars (CFGs) to represent activities ◦ CFGs are used to recognize high-level activities ◦ The detection extracts space-time points and local periodic motions to obtain a sparse distribution of interest points in a video
 to represent activities ◦ CFGs are used to recognize high-level activities ◦ The detection extracts space-time points and local periodic motions to obtain a sparse distribution of interest points in a video")
36
Probability theory Fuzzy logic Bayesian network: ◦ Used for recognition of an activity, based on the activities temporal structure representation ◦ Uses a large network with over 10,000 nodes

37
A group of persons marching ◦ The images are recognized as an overall motion of an entire group A group of people fighting ◦ Multiple videos are used to recognize the activity that a “group is fighting”

38
Recognition of interactions between humans and objects requires multiple components involved. A lot of human-object interaction ignores interaction between object recognition and motion estimation You can also factor in object dependencies, motions, and human activities to determine activities involved

40
J.K. Aggarwal and M.S. Ryoo. 2011. Human activity analysis: A review. ACM Comput. Surv. 43, 3, Article 16 (April 2011), 43 pages. DOI=10.1145/1922649.1922653 http://doi.acm.org/10.1145/1922649.1922653 http://doi.acm.org/10.1145/1922649.1922653 Christopher O. Jaynes. 1996. Computer vision and artificial intelligence. Crossroads 3, 1 (September 1996), 7-10. DOI=10.1145/332148.332152 http://doi.acm.org/10.1145/332148.332152 http://doi.acm.org/10.1145/332148.332152 Zhu Li, Yun Fu, Thomas Huang, and Shuicheng Yan. 2008. Real-time human action recognition by luminance field trajectory analysis. In Proceedings of the 16th ACM international conference on Multimedia (MM '08). ACM, New York, NY, USA, 671-676. DOI=10.1145/1459359.1459456 http://doi.acm.org/10.1145/1459359.1459456 http://doi.acm.org/10.1145/1459359.1459456 Paul Scovanner, Saad Ali, and Mubarak Shah. 2007. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th international conference on Multimedia (MULTIMEDIA '07). ACM, New York, NY, USA, 357-360. DOI=10.1145/1291233.1291311 http://doi.acm.org/10.1145/1291233.1291311 http://doi.acm.org/10.1145/1291233.1291311
, 43 pages. DOI= / Christopher O. Jaynes Computer vision and artificial intelligence. Crossroads 3, 1 (September 1996), DOI= / Zhu Li, Yun Fu, Thomas Huang, and Shuicheng Yan Real-time human action recognition by luminance field trajectory analysis. In Proceedings of the 16th ACM international conference on Multimedia (MM 08). ACM, New York, NY, USA, DOI= / Paul Scovanner, Saad Ali, and Mubarak Shah A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th international conference on Multimedia (MULTIMEDIA 07). ACM, New York, NY, USA, DOI= /")
Similar presentations