Download presentation
Presentation is loading. Please wait.

1
The Multi-Layer Perceptron non-linear modelling by adaptive pre-processing Rob Harrison AC&SE

2
error, e input data, x output, y adaptive layer target, z pre-processing layer

3
Adaptive Basis Functions “linear” models –fixed pre-processing –parameters → cost “benign” –easy to optimize but –combinatorial –arbitrary choices what is best pre-processor to choose?

4
The Multi-Layer Perceptron formulated from loose biological principles popularized mid 1980s –Rumelhart, Hinton & Williams 1986 Werbos 1974, Ho 1964 “learn” pre-processing stage from data layered, feed-forward structure –sigmoidal pre-processing –task-specific output non-linear model

5
Generic MLP INPUTLAYERINPUTLAYER OUTPUTLAYEROUTPUTLAYER HIDDEN LAYERS

6
Two-Layer MLP

7
A Sigmoidal Unit

8
Combinations of Sigmoids

9
In 2-D from Pattern Classification, 2e, by Duda, Hart & Stork, © 2001 John Wiley

10
Universal Approximation linear combination of “enough” sigmoids –Cybenko, 1990 single hidden layer adequate –more may be better choose hidden parameters (w, b) optimally problem solved?
 optimally problem solved")
11
Pros compactness –potential to obtain same veracity with much smaller model c.f. sparsity/complexity control in linear models

12
Compactness of Model

13
& Cons parameter → cost “malign” –optimization difficult –many solutions possible –effect of hidden weights in output non-linear

14
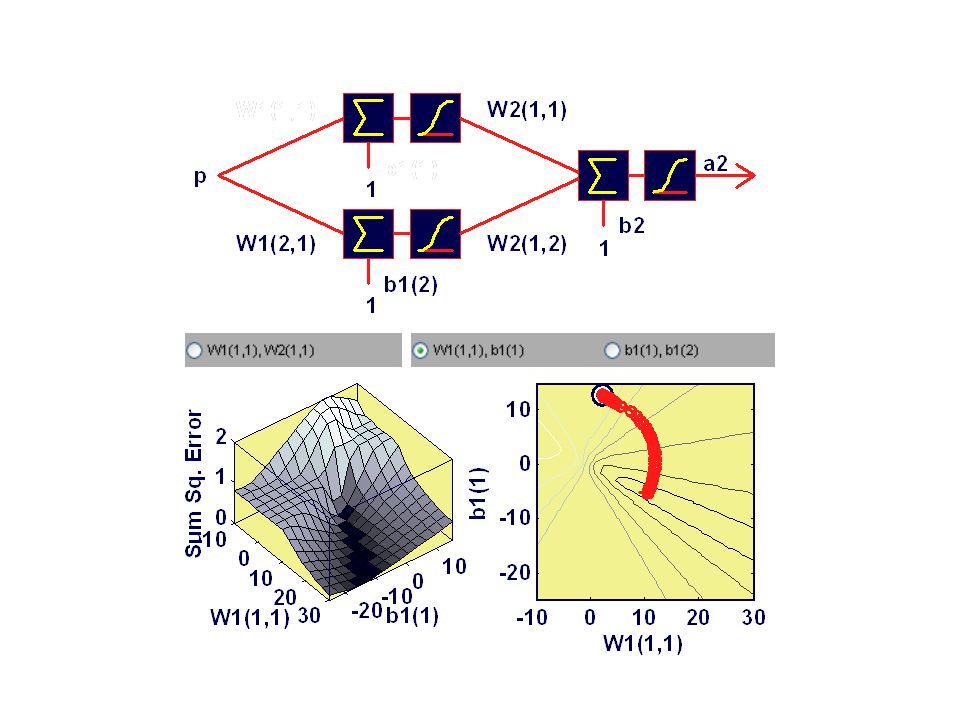
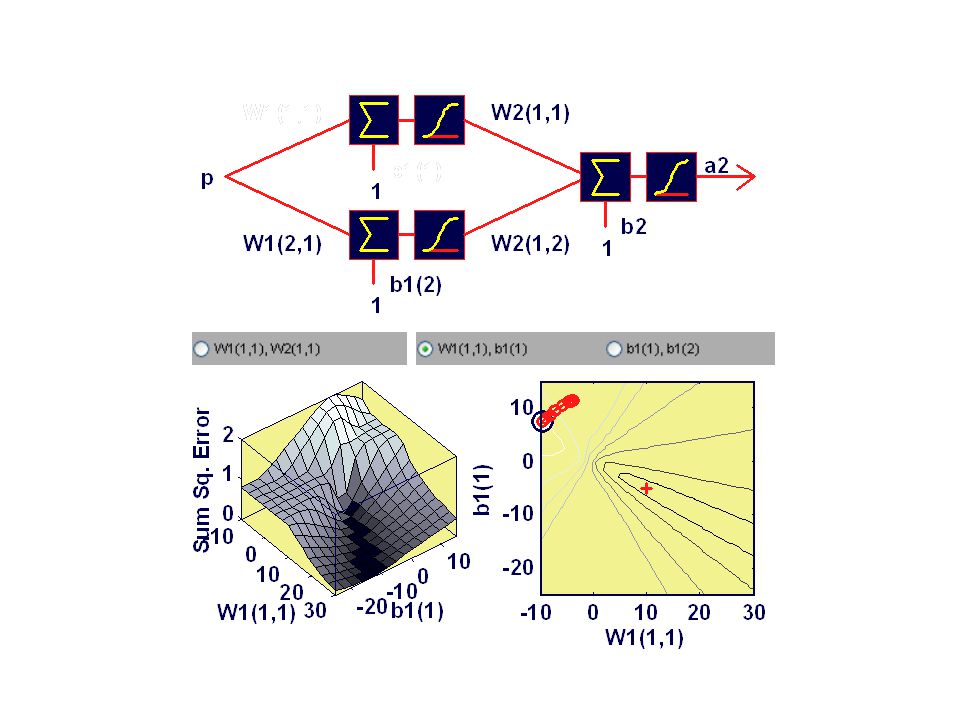
Multi-Modal Cost Surface global min local min gradient?

15
Heading Downhill assume –minimization (e.g. SSE) –analytically intractable step parameters downhill w new = w old + step in right direction backpropagation (of error) –slow but efficient conjugate gradients, Levenburg/Marquardt –for preference
 –analytically intractable step parameters downhill w new = w old + step in right direction backpropagation (of error) –slow but efficient conjugate gradients, Levenburg/Marquardt –for preference.")
18
backprop conjugate gradients

19
Implications correct structure can get “wrong” answer –dependency on initial conditions –might be good enough train / test (cross-validation) required –is poor behaviour due to network structure? ICs? additional dimension in development

20
Is It a Problem? pros seem to outweigh cons good solutions often arrived at quickly all previous issues apply –sample density –sample distribution –lack of prior knowledge

21
How to Use to “generalize” a GLM –linear regression – curve-fitting linear output + SSE –logistic regression – classification logistic output + cross-entropy (deviance) extend to multinomial, ordinal –e.g. softmax outptut + cross entropy –Poisson regression – count data

22
What is Learned? the right thing –in a maximum likelihood sense theoretical conditional mean of target data, E(z|x) –implies probability of class membership for classification P(C i |x) estimated if good estimate then y → E(z|x)
 –implies probability of class membership for classification P(C i |x) estimated if good estimate then y → E(z|x).")
23
Simple 1-D Function

24
More Complex 1-D Example

25
Local Solutions

26
A Dichotomy data courtesy B Ripley

27
Class-Conditional Probabilities

28
Linear Decision Boundary induced by P(C 1 |x) = P(C 2 |x)
 = P(C 2 |x)")
29
Class-Conditional Probabilities

30
Non-Linear Decision Boundary

31
Class-Conditional Probabilities

32
Over-fitted Decision Boundary

33
Invariances e.g. scale, rotation, translation augment training data design regularizer –tangent propagation (Simmard et al, 1992) build into MLP structure –convolutional networks (LeCun et al, 1989)
 build into MLP structure –convolutional networks (LeCun et al, 1989).")
34
Multi-Modal Outputs assumed distribution of outputs unimodal sometimes not –e.g. inverse robot kinematics E(z|x) not unique use mixture model for output density Mixture Density Networks (Bishop, 1996)
 not unique use mixture model for output density Mixture Density Networks (Bishop, 1996).")
35
Bayesian MLPs deterministic treatment point estimates, E(z|x) can use MLP as estimator in a Bayesian treatment –non-linearity → approximate solutions approximate estimate of spread E((z-y) 2 |x)
 can use MLP as estimator in a Bayesian treatment –non-linearity → approximate solutions approximate estimate of spread E((z-y) 2 |x)")
36
NETTalk Introduced by T Sejnowski & C Rosenberg First realistic ANNs demo English text-to-speech non-phonetic Context sensitive –brave, gave, save, have(within word) –read, read(within sentence) Mimicked DECTalk (rule-based)
 –read, read(within sentence) Mimicked DECTalk (rule-based)")
37
Representing Text 29 “letters” (a–z + space, comma, stop) –29 binary inputs indicating letter Context –local (within word) – global (sentence) 7 letters at a time: middle → AFs –3 each side give context, e.g. boundaries

38
Coding

39
NETTalk Performance 1024 words continuous, informal speech 1000 most common words Best performing MLP 26 o/p, 7x29 i/p, 80 hidden 309 units, 18,320 weights 94% training accuracy 85% testing accuracy

Similar presentations

>")








, take home, turn in at noon time of 03/02 (Friday)>")






 by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley.>")

