Download presentation
Presentation is loading. Please wait.

1
Christopher M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 1: INTRODUCTION Lecturer: Xiaopeng Hong These slides follow closely the course textbook “ Pattern Recognition and Machine Learning ” by Christopher Bishop and the slides “ Machine Learning and Music ” by Prof. Douglas Eck

2
免责声明

4
CV PR Feature Extraction Pattern Classification ML Statistical Symbol Contents IPSP Probability Theory Information Theory Mathematical logic …

5
PR & ML Pattern recognition has its origins in engineering, whereas machine learning grew out of computer science. However, these activities can be viewed as two facets of the same field, and together they have undergone substantial development over the past ten years.

6
Learning Learning denotes changes in the system that is adaptive in the sense that they enable the system to do the same task or tasks drawn from the same population more effectively the next time. by H. Simon 如果一个系统能够通过执行某种过程而改进它的 性能,这就是学习。 by 陆汝钤教授

9
Related Publications Conference –ICML –KDD –NIPS –IJCNN –AIML –IJCAI –COLT –CVPR –ICCV –ECCV –… Journal –Machine Learning (ML) –Journal of Machine Learning Research –Annals of Statistics –Data Mining and Knowledge Discovery –IEEE-KDE –IEEE-PAMI –Artificial Intelligence –Journal of Artificial Intelligence Research –Computational Intelligence –Neural Computation –IEEE-NN –Research, Information and Computation –…
 –Journal of Machine Learning Research –Annals of Statistics –Data Mining and Knowledge Discovery –IEEE-KDE –IEEE-PAMI –Artificial Intelligence –Journal of Artificial Intelligence Research –Computational Intelligence –Neural Computation –IEEE-NN –Research, Information and Computation –…")
14
History Classical statistical methods Division in feature space PAC Generalization Ensemble learning M. Minsky. “Perceptron” F. Rosenblatt. Perceptron BP Network

16
Leslie Gabriel Valiant He introduced the "probably approximately correct" (PAC) model of machine learning that has helped the field of computational learning theory grow. by Wikipedia 将计算复杂性作为一个必须考虑的因素。算法的复杂性必 须是多项式的。为了达到这个目的,不惜牺牲模型精度。 “ 对任意正数 ε>0 , 0≤δ<1 , |F(x)-f(x)|≤ε 成立的概率大于 1- δ ” 对这个理念,传统统计学家 难以接受 by 王珏教授
-f(x)|≤ε 成立的概率大于 1- δ 对这个理念,传统统计学家 难以接受 by 王珏教授.")
17
Vladimir N. Vapnik “ 不能将估计概率密度这个更为困难的问题作为解决机器学习分类或 回归问题的中间步骤,因此,他直接将问题变为线性判别问题其本质 是放弃机器学习建立的模型对自然模型的可解释性。 ” “ 泛化 ” “ 有限样本统计 ” – 泛化作为机器学习的核心问题 – 在线性特征空间上设计算法 – 泛化 最大边缘 “ 与其一无所有,不如求其次 ” 。这是统计学的传统 无法接受 的 by 王珏教授

18
Robert Schapire “ 对任意正数 ε>0 , 0≤δ<1 , |F(x)-f(x)|≤ε 成立的概率大于 1/2 + δ ” 构造性证明了 PAC 弱可学习的充要条件是 PAC 强可学习 集群学习有两个重要的特点: – 使用多个弱模型代替一个强模型 – 决策方法是以弱模型投票,并以少数服从多数的原则决定解答。 by 王珏教授
-f(x)|≤ε 成立的概率大于 1/2 + δ 构造性证明了 PAC 弱可学习的充要条件是 PAC 强可学习 集群学习有两个重要的特点: – 使用多个弱模型代替一个强模型 – 决策方法是以弱模型投票,并以少数服从多数的原则决定解答。 by 王珏教授")
19
Example Handwritten Digit Recognition 28 d=784 Pre-processing feature extraction 1. reduce variability ; 2. speed up computation

21
Polynomial Curve Fitting

22
Sum-of-Squares Error Function

23
0 th Order Polynomial

24
1 st Order Polynomial

25
3 rd Order Polynomial

26
9 th Order Polynomial

27
Over-fitting Root-Mean-Square (RMS) Error:
 Error:")
28
Polynomial Coefficients

29
Data Set Size: 9 th Order Polynomial

30
Data Set Size: 9 th Order Polynomial

31
Regularization Penalize large coefficient values

32
Regularization:

34
Regularization: vs.

35
Polynomial Coefficients

36
Probability Theory 统计机器学习 / 模式分类问题 可以在 贝叶斯的框架下表示 ML MAP Bayesian We now seek a more principled approach to solving problems in pattern recognition by turning to a discussion of probability theory. As well as providing the foundation for nearly all of the subsequent developments in this book.

37
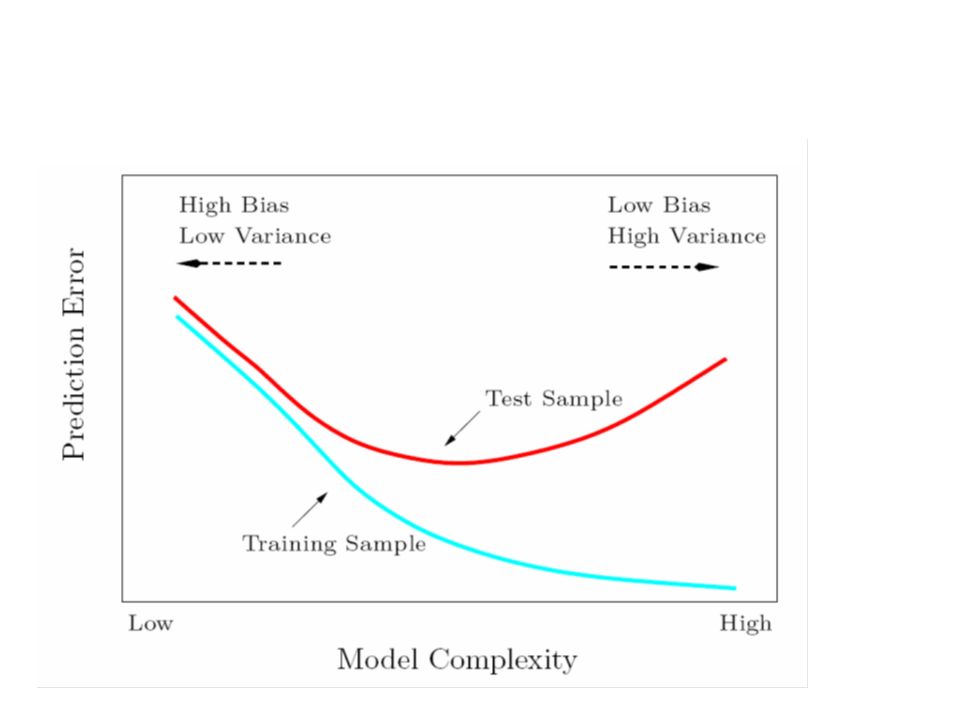
Probability Theory Apples and Oranges

38
Probability Theory Marginal Probability Conditional Probability Joint Probability

39
Probability Theory Sum Rule Product Rule

40
The Rules of Probability Sum Rule Product Rule

41
Bayes ’ Theorem posterior likelihood × prior

42
Probability Densities

43
Transformed Densities

44
Expectations Conditional Expectation (discrete) Approximate Expectation (discrete and continuous)
 Approximate Expectation (discrete and continuous)")
45
Variances and Covariances

47
The Gaussian Distribution

48
Gaussian Mean and Variance

49
The Multivariate Gaussian

50
Gaussian Parameter Estimation Likelihood function

51
Maximum (Log) Likelihood
 Likelihood")
52
Properties of and

53
Curve Fitting Re-visited precision para.

54
Maximum Likelihood Determine by minimizing sum-of-squares error,. 1. mean W ML 2. precision β

55
Predictive Distribution

56
MAP: A Step towards Bayes Determine by minimizing regularized sum-of-squares error,.

57
Bayesian Curve Fitting fully Bayesian approach Section 3.3

58
Bayesian Predictive Distribution

59
1.3 Model Selection Many parameters… we need to determine the values of such parameters, and the principal objective in doing so is usually to achieve the best predictive performance on new data. Section 3.3 we may wish to consider a range of different types of model in order to find the best one for our particular application.

60
Model Selection Cross-Validation complexity information criteria tend to favour overly simple models Section 3.4 & 4.4.1

62
1.4 Curse of Dimensionality we will have to deal with spaces of high dimensionality comprising many input variables. this poses some serious challenges and is an important factor influencing the design of pattern recognition techniques.

63
Curse of Dimensionality

64
Polynomial curve fitting, M = 3

65
1.5 Decision Theory Determination of p(x, t) from a set of training data is an example of inference and is typically a very difficult problem whose solution forms the subject of much of this book. In a practical application, we often make a specific prediction for the value of t, or more generally take a specific action based on our understanding of the values t is likely to take, and this aspect is the subject of decision theory.

66
Decision Theory Inference step Determine either or. Decision step For given x, determine optimal t.

67
Minimum Misclassification Rate If our aim is to minimize the chance of assigning x to the wrong class, then intuitively we would choose the class having the higher posterior probability. decision regions

68
Minimum Expected Loss Example: classify medical images as ‘ cancer ’ or ‘ normal ’ Decision Truth loss function / cost function

69
Minimum Expected Loss Regions are chosen to minimize

70
Reject Option

71
Why Separate Inference and Decision? Minimizing risk (loss matrix may change over time) Reject option Unbalanced class priors Combining models
 Reject option Unbalanced class priors Combining models.")
72
Decision Theory for Regression Inference step Determine. Decision step For given x, make optimal prediction, y(x), for t. Loss function:
, for t. Loss function:.")
73
Generative vs Discriminative Generative approach: Model Use Bayes ’ theorem Discriminative approach: Model directly Discriminant function

74
1.6 Information Theory Information theory will also prove useful in our development of pattern recognition and machine learning techniques Considering a discrete random variable x, how much information is received when we observe a specific value for this variable. The amount of information can be viewed as the ‘degree of surprise’ on learning the value of x.

75
Entropy Important quantity in coding theory statistical physics machine learning

76
Entropy Coding theory: x discrete with 8 possible states; how many bits to transmit the state of x ? All states equally likely

77
Entropy

78
Conditional Entropy

79
The Kullback-Leibler Divergence

80
Mutual Information

81
Conclusion Machine Learning Generalization Classification/Regression fitting/over-fitting Regularization Bayes ’ Theorem Bayes ’ Decision Entropy/KLD/MI

82
Q & A

Similar presentations











![首 页 首 页 上一页 下一页 本讲内容 投影法概述三视图形成及其投影规律平面立体三视图、尺寸标注 本讲内容 复习: P25~P31 、 P84~P85 作业: P7, P8, P14[2-32(2) A3 (1:1)]](/12/3353742/big_thumb.jpg "首 页 首 页 上一页 下一页 本讲内容 投影法概述三视图形成及其投影规律平面立体三视图、尺寸标注 本讲内容 复习: P25~P31 、 P84~P85 作业: P7, P8, P14[2-32(2) A3 (1:1)]>")




 节目录 2.1 随机变量与分布函数 2.2 离散型随机变量的概率分布 2.3 连续型随机变量的概率分布 第二章 随机变量及其分布.>")

相 互联系的质点组成的系统 研究方法: 1. 分离体法 2. 从整体考虑 把质点的三个定理推广到质点组.>")


 数据 原始事实 如:员工姓名, 数据可以有数值、图形、声音、视觉数据等 信息 以一定规则组织在一起的事实的集合。>")


 离散数学. 最后,我们构造能识别 A 的 Kleene 闭包 A* 的自动机 M A* =(S A* , I , f A* , s A* , F A* ) , 令 S A* 包括所有的 S A 的状态以及一个 附加的状态 s.>")



 部分电离学说 (1878 年 ) 弱电解质溶液体系 离子间相互作用 (1923 年 ) 强电解质溶液体系.>")
倍加到第 n 行上,第( n-2 ) 行( -1 )倍加到第 n-1 行上,以此类推, 直到第 1 行( -1 )倍加到第 2 行上。>")
,n ∈ N +, 所以,数列 {x n } 的极限为 a, 就是 当自变量 n.>")