Download presentation
Presentation is loading. Please wait.

1
Parallel and Distributed Algorithms Eric Vidal Reference: R. Johnsonbaugh and M. Schaefer, Algorithms (International Edition). 2004. Pearson Education.
 Pearson Education..")
2
Outline Introduction (case study: maximum element) – Work-optimality The Parallel Random Access Machine – Shared memory modes – Accelerated cascading Other Parallel Architectures (case study: sorting) – Circuits – Linear processor networks – (Mesh processor networks) Distributed Algorithms – Message-optimality – Broadcast and echo – (Leader election)
 – Work-optimality The Parallel Random Access Machine – Shared memory modes – Accelerated cascading Other Parallel Architectures (case study: sorting) – Circuits – Linear processor networks – (Mesh processor networks) Distributed Algorithms – Message-optimality – Broadcast and echo – (Leader election)")
3
Introduction

4
Why use parallelism? p steps on 1 printer, 1 step on p printers p = speed-up factor (best case) Given a sequential algorithm, how can we parallelize it? – Some are inherently sequential (P-complete)
 Given a sequential algorithm, how can we parallelize it. – Some are inherently sequential (P-complete).")
5
Case Study: Maximum Element In: a[] Out: maximum element in a sequential_maximum(a) { n = a.length max = a[0] for i = 1 to n – 1 { if (a[i] > max) max = a[i] } return max } 2111231748332241 21 23 48 O(n)
![Case Study: Maximum Element In: a[] Out: maximum element in a sequential_maximum(a) { n = a.length max = a[0] for i = 1 to n – 1 { if (a[i] > max) max = a[i] } return max } O(n)](http://images.slideplayer.com/25/7775789/slides/slide_5.jpg "Case Study: Maximum Element In: a[] Out: maximum element in a sequential_maximum(a) { n = a.length max = a[0] for i = 1 to n – 1 { if (a[i] > max) max = a[i] } return max } O(n)")
6
Parallel Maximum Idea: Use ⌈ n / 2 ⌉ processors Note idle processors after the first step! 2111231748332241 21234841 2348 O(lg n)
.")
7
Work-Optimality Work = number of algorithmic steps × number of processors Running time of parallelized maximum algo = O(lg n) × (n / 2) = O(n lg n) Not work-optimal! Sequential algo’s work is O(n) – Workaround: accelerated cascading…
 – Workaround: accelerated cascading….")
8
Formal Algorithm for Parallel Maximum But first!...

9
The Parallel Random Access Machine

10
The Parallel Random Access Machine (PRAM) New construct: parallel loop for i = 1 to n in parallel { … } Assumption 1: use n processors to execute this loop (processors are synchronized) Assumption 2: memory shared across all processors
 New construct: parallel loop for i = 1 to n in parallel { … } Assumption 1: use n processors to execute this loop (processors are synchronized) Assumption 2: memory shared across all processors")
11
Example: Parallel Search In: a[], x Out: true if x is in a, false otherwise parallel_search(a, x) { n = a.length found = false for i = 0 to n – 1 in parallel { if (a[i] == x) found = true } return found } Is this work-optimal? Shared memory modes: Exclusive Read (ER) Concurrent Read (CR) Exclusive Write (EW) Concurrent Write (CW) Real-world systems are most commonly CREW parallel_search runs on what type?
![Example: Parallel Search In: a[], x Out: true if x is in a, false otherwise parallel_search(a, x) { n = a.length found = false for i = 0 to n – 1 in parallel { if (a[i] == x) found = true } return found } Is this work-optimal.](http://images.slideplayer.com/25/7775789/slides/slide_11.jpg "Shared memory modes: Exclusive Read (ER) Concurrent Read (CR) Exclusive Write (EW) Concurrent Write (CW) Real-world systems are most commonly CREW parallel_search runs on what type .")
12
Formal Algorithm for Parallel Maximum In: a[] Out: maximum element in a parallel_maximum(a) { n = a.length for i = 0 to ⌈ lg n ⌉ – 1 { for j = 0 to ⌈ n/2 i+1 ⌉ – 1 in parallel { if (j × 2 i+1 + 2 i < n) // boundary check a[j × 2 i+1 ] = max(a[j × 2 i+1 ], a[j × 2 i+1 + 2 i ]) } } return a[0] } Theorem: parallel_maximum is CREW and finds the maximum element in parallel time O(lg n) and work O(n lg n)
![Formal Algorithm for Parallel Maximum In: a[] Out: maximum element in a parallel_maximum(a) { n = a.length for i = 0 to ⌈ lg n ⌉ – 1 { for j = 0 to ⌈ n/2 i+1 ⌉ – 1 in parallel { if (j × 2 i i < n) // boundary check a[j × 2 i+1 ] = max(a[j × 2 i+1 ], a[j × 2 i i ]) } } return a[0] } Theorem: parallel_maximum is CREW and finds the maximum element in parallel time O(lg n) and work O(n lg n)](http://images.slideplayer.com/25/7775789/slides/slide_12.jpg "Formal Algorithm for Parallel Maximum In: a[] Out: maximum element in a parallel_maximum(a) { n = a.length for i = 0 to ⌈ lg n ⌉ – 1 { for j = 0 to ⌈ n/2 i+1 ⌉ – 1 in parallel { if (j × 2 i i < n) // boundary check a[j × 2 i+1 ] = max(a[j × 2 i+1 ], a[j × 2 i i ]) } } return a[0] } Theorem: parallel_maximum is CREW and finds the maximum element in parallel time O(lg n) and work O(n lg n)")
13
Accelerated Cascading Phase 1: Use sequential_maximum on blocks of lg n elements – We use n / lg n processors – O(lg n) sequential steps per processor – Total work = O(lg n) steps × (n / lg n) processors = O(n) Phase 2: Use parallel_maximum on the resulting n / lg n elements – lg (n / lg n) parallel steps = lg n – lg (lg n) = O(lg n) – Total work = O(lg n) steps × ((n / lg n) / 2) processors = O(n)
 sequential steps per processor – Total work = O(lg n) steps × (n / lg n) processors = O(n) Phase 2: Use parallel_maximum on the resulting n / lg n elements – lg (n / lg n) parallel steps = lg n – lg (lg n) = O(lg n) – Total work = O(lg n) steps × ((n / lg n) / 2) processors = O(n)")
14
Formal Algorithm for Optimal Maximum In: a[] Out: maximum element in a optimal_maximum(a) { n = a.length block_size = ⌈ lg n ⌉ block_count = ⌈ n / block_size ⌉ create array block_results[block_count] for i = 0 to block_count – 1 in parallel { start = i × block_size end = min(n – 1, start + block_size – 1) block_results[i] = sequential_maximum(a[start.. end]) } return parallel_maximum(block_results) }
![Formal Algorithm for Optimal Maximum In: a[] Out: maximum element in a optimal_maximum(a) { n = a.length block_size = ⌈ lg n ⌉ block_count = ⌈ n / block_size ⌉ create array block_results[block_count] for i = 0 to block_count – 1 in parallel { start = i × block_size end = min(n – 1, start + block_size – 1) block_results[i] = sequential_maximum(a[start..](http://images.slideplayer.com/25/7775789/slides/slide_14.jpg "end]) } return parallel_maximum(block_results) }.")
15
Some Notes All CR algorithms can be converted to ER algorithms! – “Broadcasting” an ER variable to all processors for concurrent access takes O(lg n) parallel time maximum is a “semigroup algorithm” – Semigroup = a set of elements + an associative binary relation (max, min, +, ×, etc.) – Same accelerated-cascading methods can be applied for min-element, summation, product of n numbers, etc.!
 parallel time maximum is a semigroup algorithm – Semigroup = a set of elements + an associative binary relation (max, min, +, ×, etc.) – Same accelerated-cascading methods can be applied for min-element, summation, product of n numbers, etc.!.")
16
Other Parallel Architectures

17
PRAM may not be the best model Shared memory = expensive! – Some algorithms require communication between processors (= memory locking issues) – Better to use channels! Extreme case: very simple processors with no shared memory (just communication channels)
 – Better to use channels. Extreme case: very simple processors with no shared memory (just communication channels).")
18
Circuits Each processor is a gate with a specialized function (e.g., comparator gate) Circuit = a layout of gates to perform a full task (e.g., sorting) x y min(x, y) max(x, y)
 Circuit = a layout of gates to perform a full task (e.g., sorting) x y min(x, y) max(x, y)")
19
Sorting circuit for 4 elements (depth 3) Step 1Step 2Step 3 (Depth of network = 3) 17 42 23 7 17 42 7 23 17 7 23 42 7
 Step 1Step 2Step 3 (Depth of network = 3)")
20
Sorting circuit for n elements? Simpler problem: max element Idea: Add as many of these diagonals as needed

21
Odd-Even Transposition Network Theorem: The odd-even transposition network sorts n numbers in n steps and O(n 2 ) processors 18 42 31 56 12 11 19 34 18 42 31 56 11 12 19 34 18 31 42 11 56 12 19 34 18 31 11 42 12 56 19 34 18 11 31 12 42 19 56 34 11 18 12 31 19 42 34 56 11 12 18 19 31 34 42 56 11 12 18 19 31 34 42 56 11 12 18 19 31 34 42 56
 processors")
22
Zero-One Principle of Sorting Networks Lemma: If a sorting network works correctly on all inputs consisting of only 0’s and 1’s, it works for any arbitrary input – Assume there is a network that sorts 0-1 sequences but not another arbitrary input a 0.. a n-1 – Let b 0.. b n-1 be the output of that network – There must exist s b t – Label all a i < b s with 0 and all else with 1 – If we run all a 0.. a n-1 with their labels, then b s ’s label will be 1 and b t ’s label will be 0 – Contradiction: The network is assumed to sort 0-1 sequences properly but did not do so here!

23
Correctness of the Odd-Even Transposition Network Assume binary sequence a 0.. a n–1 Let a i = first 0 in the sequence Two cases: i is odd or even To sort a 0.. a i, we need i steps (worst-case) Induction: Given a 0.. a k (where k ≥ i) will sort in k steps, will a 0.. a k+1 get sorted in k+1 steps? 1 1 1 0 1 1 0 1 1 0 1 0 1 0 1 1 1 1 0 1 1 1 1 0 1 1 1 0 1 1 0 0 10 1
 Induction: Given a 0.. a k (where k ≥ i) will sort in k steps, will a 0.. a k+1 get sorted in k+1 steps")
24
Better Sorting Networks Batcher’s Bitonic Sorter (1968) – Depth O(lg 2 n), size O(n lg 2 n) – Idea: sort 2 groups (recursively), then merge using a network that can sort bitonic sequences AKS Network (1983) – Ajtai, Komlós and Szemerédl – Depth O(lg n), size O(n lg n) – Not practical! Hides a very large c in the cn lg n algorithm

25
More Intelligent Processors: Processor Networks Star Linear/Ring Completely-connected Mesh Diameter = 2 Diameter = n – 1 (or n – 2) Diameter = 1
 Diameter = 1")
26
Sorting on Linear Networks Emulate an odd-even transposition network! O(n) steps, work is O(n 2 ) – We can’t expect better on a linear network 18423156121119 18423156111219 18314211561219 18311142125619 18113112421956 11181231194256 11121819314256 11121819314256
 steps, work is O(n 2 ) – We can’t expect better on a linear network")
27
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Row phase Sort rows, sort columns, repeat 154106 11751 1214138 91623

28
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Column phase Sort rows, sort columns, repeat 461015 11751 8121314 16932

29
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Row phase Sort rows, sort columns, repeat 4631 8752 1191014 16121315

30
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Column phase Sort rows, sort columns, repeat 1346 8752 9101114 16151312

31
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Row phase Sort rows, sort columns, repeat 1342 8756 9101112 16151314

32
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Column phase Sort rows, sort columns, repeat 1234 8765 9101112 16151413

33
Sorting on Mesh Networks: Shearsort Arrange numbers in “boustrophedon” order a = { 15, 4, 10, 6, 1, 5, 7, 11, 12, 14, 13, 8, 9, 16, 2, 3 } Done! Sort rows, sort columns, repeat 1234 8765 9101112 16151413

34
Sorting on Mesh Networks: Shearsort Theorem: Shearsort sorts n 2 elements in O(n lg n) steps on an n × n mesh We can use the Zero-One Principle! – Only because algorithm is comparison-exchange Can be implemented using comparators only – and oblivious Outcome of comparator does not influence comparisons made later on – (Disclaimer: reference is actually very unclear about this)
.")
35
Correctness of Shearsort 01001001 01110111 00101001 10010010 11101010 00011101 00111111 11001111

36
00000111 11111100 00000111 11100000 00011111 11110000 00111111 11111100 1 full row of 1’s 1 full row of 0’s 1 full row of 1’s

37
Correctness of Shearsort lg(n) × 2 phases, each phase takes n steps 00000000 00000000 00000100 00110100 11111111 11111111 11111111 11111111 Sort space guaranteed to be halved after 2 phases
 × 2 phases, each phase takes n steps Sort space guaranteed to be halved after 2 phases")
38
Distributed Algorithms

39
Different concerns altogether… Problems usually easy to parallelize Main problems: – Inherently asynchronous – How to broadcast data and ensure every node gets it – How to minimize bandwidth usage – What to do when nodes go down (decentralization) – (Do we trust the results given by the nodes?) 2, 3, 5, 7, 13 … … 2 42643801 -1, 2 43112609 -1… DES (56-bit) SETI@Home
 – (Do we trust the results given by the nodes ) 2, 3, 5, 7, 13 … … , … DES (56-bit)")
40
Message-Optimality New language constructs: send to p receive from p terminate Message-complexity = number of messages sent by a distributed algorithm (also uses O-notation)
")
41
Broadcast Initiators vs. noninitiators Simple case: ring network w/ one initiator init_ring_broadcast() { send token to successor receive token from predecessor terminate } ring_broadcast() { receive token from predecessor send token to successor terminate } Theorem: init_ring_broadcast + ring_broadcast broadcasts to n machines using time and message complexity O(n)
 { send token to successor receive token from predecessor terminate } ring_broadcast() { receive token from predecessor send token to successor terminate } Theorem: init_ring_broadcast + ring_broadcast broadcasts to n machines using time and message complexity O(n).")
42
Broadcast on a tree network init_broadcast() { N = { q | q is a child neighbor of p } for each q ∈ N send token to q terminate } broadcast() { receive token from parent N = { q | q is a child neighbor of p } for each q ∈ N send token to q terminate } Note: no acknowledgment! 2 1 3 6 4 5
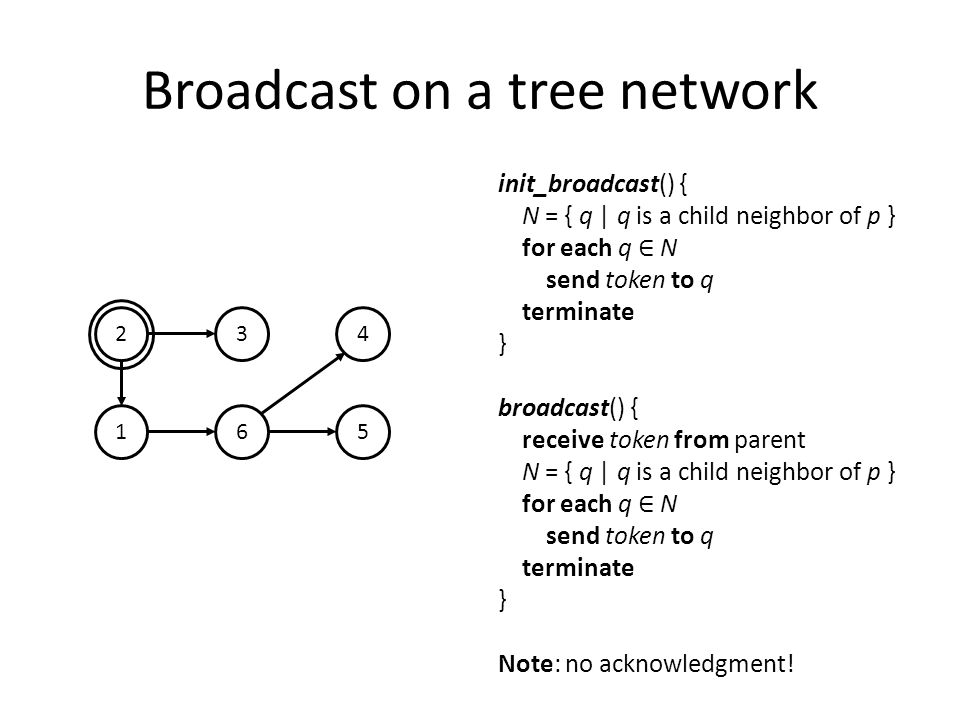
43
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate }")
44
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 0 nul
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } nul")
45
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 0 0 nul
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } nul")
46
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 0 0 nul 0
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } nul 0")
47
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 0 0 nul 0 0
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } nul 0 0")
48
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 1 0 0 0 1 2
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate }")
49
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 1 0 2 2 3 2
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate }")
50
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 2 0 fin 4
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } fin 4")
51
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 2 1 fin
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } fin")
52
Echo Creates a spanning tree out of any connected network init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 3 fin
 { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } fin")
53
Echo Creates a spanning tree out of any connected network Theorem: init_echo + echo has time complexity O(diameter) and message complexity O(edges) init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } 2 1 3 6 4 5 fin
 and message complexity O(edges) init_echo() { N = { q | q is a neighbor of p } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } terminate } echo() { receive token from parent N = { q | q is a neighbor of p } – { parent } for each q ∈ N send token to q counter = 0 while (counter < |N|) { receive token counter = counter + 1 } send token to parent terminate } fin")
54
Leader Election (for ring networks) init_election() { send token, p.ID to successor min = p.ID receive token, token_id while (p.ID != token_id) { if token_id < min min = token_id send token, token_id to successor receive token, token_id } if (p.ID == min) i_am_the_leader = true else i_am_the_leader = false terminate } election() { i_am_the_leader = false do { receive token, token_id send token, token_id to successor } while (true) } Theorem: init_election + election runs in n steps with message complexity O(n 2 )
 init_election() { send token, p.ID to successor min = p.ID receive token, token_id while (p.ID != token_id) { if token_id < min min = token_id send token, token_id to successor receive token, token_id } if (p.ID == min) i_am_the_leader = true else i_am_the_leader = false terminate } election() { i_am_the_leader = false do { receive token, token_id send token, token_id to successor } while (true) } Theorem: init_election + election runs in n steps with message complexity O(n 2 )")
Similar presentations
 Parallel: perform more than one operation at a time. PRAM model: Parallel Random Access Model. p0p0 p1p1.>")








 { temp=A; A=B; B=temp; } Potential Speed-up –Optimal Comparison Sort: O(N lg N) –Optimal Parallel.>")
>")

 ▪ Informal Work Depth Model PRAM Model Technique:>")


 Algorithm Design Parallel Computing Fall 2007.>")



