Download presentation
Presentation is loading. Please wait.

1
Beyond Text Representation Building on Unicode to Implement a Multilingual Text Analysis Framework Thomas Hampp – IBM Germany Content Management Development

2
Thomas Hampp IBM18th International Unicode Conference2 Basic Text Analysis Tasks Code page conversion and text representation Segmentation (tokens, sentences, paragraphs) Morphological analysis / dictionary lookup Compound word decomposition Spell Checking/Spell Aid …
 Morphological analysis / dictionary lookup Compound word decomposition Spell Checking/Spell Aid …")
3
Thomas Hampp IBM18th International Unicode Conference3 Advanced Text Analysis Tasks Summarization Categorization/Clustering Extraction of names, terms or relations Information extraction Parsing All task should be provided for all languages

4
Thomas Hampp IBM18th International Unicode Conference4 A Library for Text Analysis The same text analysis tasks are needed in different multilingual contexts/systems The same software library should be used in all contexts/systems to perform the analysis The library should work language neutral The text analysis tasks required for a given context/system should be an input parameter for the library

5
Thomas Hampp IBM18th International Unicode Conference5 Two Problems and One Solution The realization of such a library faces two kinds of challenges: A. Implementing the actual language specific analysis tasks B. Encapsulating the language specific processing by representing input and output in a language neutral fashion Unicode plays a major role in solving problem B

6
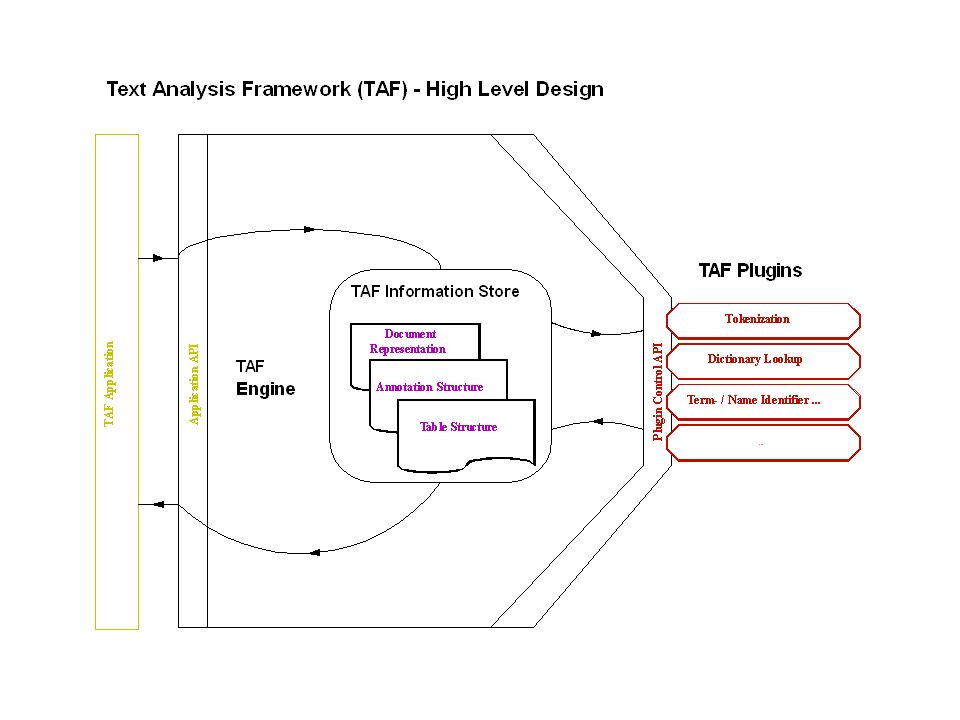
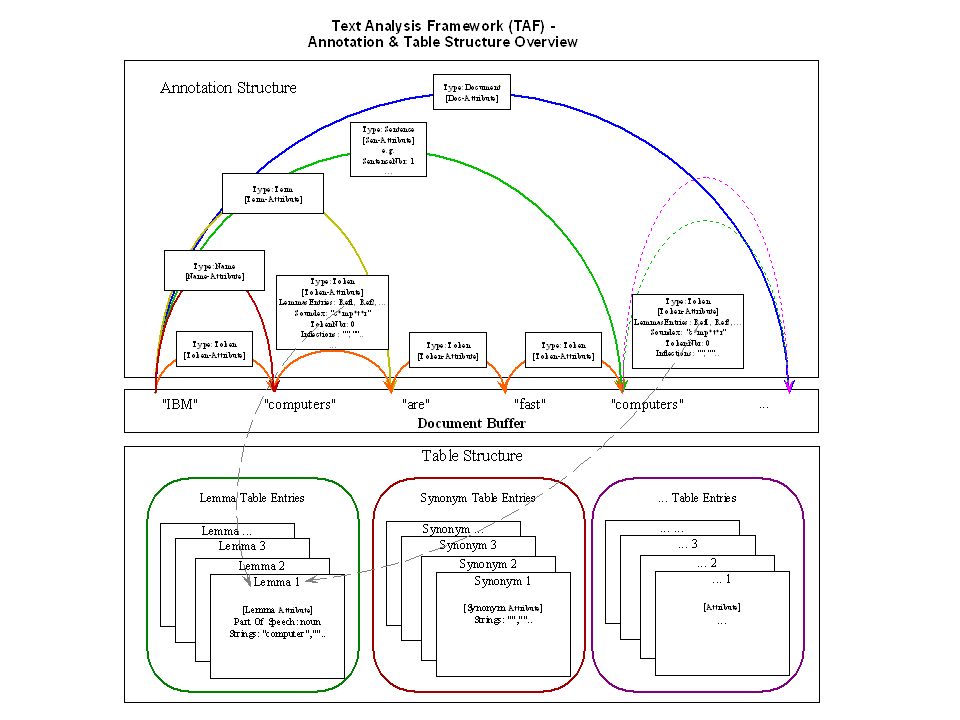
Thomas Hampp IBM18th International Unicode Conference6 A Software Design for a Text Analysis Library Single API towards the application Separated but combinable language- specific processing modules Central representation system for linguistic information Centralized flow of control driven by linguistic analysis targets

10
Thomas Hampp IBM18th International Unicode Conference10 Implementation Implemented as C++ DLL/shared Lib Provides an extensive object oriented API for applications and plugins Uses Unicode (ICU based) for all text content Ported to 9 platforms (therefore no platform dependant solutions acceptable) Because of use in search/indexing strong focus on performance Supports 30+ languages and 90+ code pages
 for all text content Ported to 9 platforms (therefore no platform dependant solutions acceptable) Because of use in search/indexing strong focus on performance Supports 30+ languages and 90+ code pages")
11
Thomas Hampp IBM18th International Unicode Conference11 Enter Unicode Used as internal character representation format (character set) Converters from/to over 90 external code pages had to be written/integrated A decision had to be made on the Unicode encoding format: we choose UTF-16
 Converters from/to over 90 external code pages had to be written/integrated A decision had to be made on the Unicode encoding format: we choose UTF-16")
12
Thomas Hampp IBM18th International Unicode Conference12 The Pros UTF-16 We started out without knowledge of surrogate issues False assumption: Fixed length encoding Good balance between size and straightforward representation Efficient interoperability with Windows, Java, XML4C APIs etc

13
Thomas Hampp IBM18th International Unicode Conference13 The Cons of UTF-16 Not a fixed length encoding because of surrogates Can not be passed to legacy functions (C library, OS APIs) Character classification functions have to work on pointers for surrogates Wastes some space with western languages
 Character classification functions have to work on pointers for surrogates Wastes some space with western languages")
14
Thomas Hampp IBM18th International Unicode Conference14 ANSI C/C++ Compatibility ANSI C++ does define a type w_char for wide character representation (and a matching wide string class wstring ) Unfortunately size and encoding of w_char are not standardized So we combined the ANSI C++ basic_string template class with the Unicode character data type from ICU to create a C++ and Unicode conformant string class
 Unfortunately size and encoding of w_char are not standardized So we combined the ANSI C++ basic_string template class with the Unicode character data type from ICU to create a C++ and Unicode conformant string class")
15
Thomas Hampp IBM18th International Unicode Conference15 Impact Beyond Character Representation Tokenization Finite state processing Dictionary formats Environmental issues Development tools support

16
Thomas Hampp IBM18th International Unicode Conference16 Impact: Tokenization Tokenization needs access to character properties Most but not all relevant are provided by Unicode character database For application defined properties there is no more fast & simple 256 character property lookup Approach limited to western scripts

17
Thomas Hampp IBM18th International Unicode Conference17 Impact: Finite State Processing Finite state character processing in C usually works with transition tables encoded as arrays This is easy to implement and very fast in execution To cover the full range of all Unicode characters, more sophisticated transition tables are required

18
Thomas Hampp IBM18th International Unicode Conference18 Impact: Dictionaries Dictionaries tend to be large As much of them as possible has to be loaded in memory for performance reasons For multilingual (server) applications multiple dictionaries will be in memory Therefore dictionary size matters much Doubling dictionary size might not be an viable option
 applications multiple dictionaries will be in memory Therefore dictionary size matters much Doubling dictionary size might not be an viable option")
19
Thomas Hampp IBM18th International Unicode Conference19 Impact: Environmental Issues There is always as residue of single byte string data (from message catalog, command line, library calls etc.) which sometimes has to be mixed with Unicode string data Interfaces for console, messages, logs etc. are mostly single byte Configuration files should be platform-neutral, easily editable and support the full Unicode character set

20
Thomas Hampp IBM18th International Unicode Conference20 Impact: Development Tools Support Only specialized editors can handle Unicode text Most debuggers dont display Unicode Source code string constants are hard to maintain Message catalog compilers on some platforms are not Unicode enabled

21
Thomas Hampp IBM18th International Unicode Conference21 A Word About Unicode Normalization Forms For reasons of efficient interoperability a fixed Unicode normalization had to be specified Early normalization is performance critical Since round trip convertibility was not a design goal Unicode Kompatibility Composed Normal Form has been chosen Normalization and cope page conversion can and should be done in one step

22
Thomas Hampp IBM18th International Unicode Conference22 Benefits of Unicode Use No more code page troubles within the boundaries of the application Very often algorithms can be established for groups of languages Multilanguage document collections and even mixed language documents are no problem to represent Easy and efficient Java (JNI) integration
 integration")
23
Thomas Hampp IBM18th International Unicode Conference23 Summing Up: Building on Unicode… …solves only the basic character representation problem for multilingual text analysis …sets a solid foundation for a multilingual system …enables algorithms to be reused for groups of languages. …can have impact on the system far beyond the character representation level …has been worth the trouble

Similar presentations















 –>")




