Download presentation
Presentation is loading. Please wait.

1
Analyzing CUDA Workloads Using a Detailed GPU Simulator
Ali Bakhoda, George L. Yuan, Wilson W. L. Fung, Henry Wong and Tor M. Aamodt University of British Columbia

2
GPUs and CPUs on a collision course
1st GPUs with programmable shaders in 2001 Today: TeraFlop on a single card. Turing complete. Highly accessible: senior undergrad students can learn to program CUDA in a few weeks (not good perf. code) Rapidly growing set of CUDA applications (209 listed on NVIDIA’s CUDA website in February). With OpenCL safely expect number of non-graphics applications written for GPUs to explode. GPUs are massively parallel systems: Multicore + SIMT + fine grain multithreaded
 Rapidly growing set of CUDA applications (209 listed on NVIDIA’s CUDA website in February). With OpenCL safely expect number of non-graphics applications written for GPUs to explode. GPUs are massively parallel systems: Multicore + SIMT + fine grain multithreaded.")
3
No academic detailed simulator for studying this?!?

4
GPGPU-Sim An academic detailed (“cycle-level”) timing simulator developed from the ground up at the University of British Columbia (UBC) for modeling a modern GPU running non-graphics workloads. Relatively accurate (no effort expended trying to make it more accurate relative to real hardware)
 timing simulator developed from the ground up at the University of British Columbia (UBC) for modeling a modern GPU running non-graphics workloads. Relatively accurate. (no effort expended trying to make it more accurate relative to real hardware)")
5
GPGPU-Sim Currently supports CUDA version 1.1 applications “out of the box”. Microarchitecture model Based on notion of “shader cores” which approximate NVIDIA GeForce 8 series and above notion of “Streaming Multiprocessor”. Connect to memory controllers using a detailed network-on-chip simulator (Dally & Towles’ booksim) Detailed DRAM timing model (everything except refresh) GPGPU-Sim v2.0b available:
 Detailed DRAM timing model (everything except refresh) GPGPU-Sim v2.0b available:")
6
Rest of this talk Obligatory brief introduction to CUDA
GPGPU-Sim internals (100,000’ view) Simulator software overview Modeled Microarchitecture Some results from the paper
 Simulator software overview. Modeled Microarchitecture. Some results from the paper.")
7
CUDA Example Runs on CPU nthreads x nblocks copies run in
main() { … cudaMalloc((void**) &d_idata, bytes); cudaMalloc((void**) &d_odata, maxNumBlocks*sizeof(int)); cudaMemcpy(d_idata, h_idata, bytesin, cudaMemcpyHostToDevice); reduce<<< nthreads, nblocks, smemSize >>>(d_idata, d_odata); cudaThreadSynchronize(); cudaMemcpy(d_odata, h_odata, bytesout, cudaMemcpyDeviceToHost); } __global__ void reduce(int *g_idata, int *g_odata) extern __shared__ int sdata[]; unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); for(unsigned int s=1; s < blockDim.x; s *= 2) { if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; if (tid == 0) g_odata[blockIdx.x] = sdata[0]; Runs on CPU nthreads x nblocks copies run in Parallel on GPU
 { … cudaMalloc((void**) &d_idata, bytes); cudaMalloc((void**) &d_odata, maxNumBlocks*sizeof(int)); cudaMemcpy(d_idata, h_idata, bytesin, cudaMemcpyHostToDevice); reduce<<< nthreads, nblocks, smemSize >>>(d_idata, d_odata); cudaThreadSynchronize(); cudaMemcpy(d_odata, h_odata, bytesout, cudaMemcpyDeviceToHost); } __global__ void reduce(int *g_idata, int *g_odata) extern __shared__ int sdata[]; unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); for(unsigned int s=1; s < blockDim.x; s *= 2) { if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; if (tid == 0) g_odata[blockIdx.x] = sdata[0]; Runs on CPU. nthreads x. nblocks. copies run in. Parallel on GPU.")
8
Normal CUDA Flow Applications written in a mixture of C/C++ and CUDA.
“nvcc” takes CUDA (.cu) files and generates host C code and “Parallel Thread eXecution” assembly language (PTX). PTX is passed to assembler / optimizer “ptxas” to generate machine code that is packed into a C array (not human readable). Combine whole thing and link to CUDA runtime API using regular C/C++ compiler linker. Run your app on the GPU.
 files and generates host C code and Parallel Thread eXecution assembly language (PTX). PTX is passed to assembler / optimizer ptxas to generate machine code that is packed into a C array (not human readable). Combine whole thing and link to CUDA runtime API using regular C/C++ compiler linker. Run your app on the GPU.")
9
GPGPU-Sim Flow Uses CUDA nvcc to generate CPU C code and PTX.
flex/bison parser reads in PTX. Link together host (CPU) code and simulator into one binary. Intercept CUDA API calls using custom libcuda that implements functions declared in header files that come with CUDA.
 code and simulator into one binary. Intercept CUDA API calls using custom libcuda that implements functions declared in header files that come with CUDA.")
10
GPGPU-Sim Microarchitecture
Set of “shader cores” connected to set of memory controllers via a detailed interconnection network model (booksim). Memory controllers reorder requests to reduce activate /precharge overheads. Vary topology / bandwidth of interconnect Cache for global memory operations.
. Memory controllers reorder requests to reduce activate /precharge overheads. Vary topology / bandwidth of interconnect. Cache for global memory operations.")
11
Shader Core Details Shader core roughly like a “Streaming Multiprocessor” in NVIDIA terminology. Set of scalar threads grouped together into an SIMD unit called a “warp” (NVIDIA uses 32 on current hardware). Warps grouped into CTAs. CTAs grouped into “grids”. Set of warps on a core are fine grain interleaved on pipeline to hide off-chip memory access latency. Threads in one CTA can communicate via an on chip 16KB “shared memory”.
. Warps grouped into CTAs. CTAs grouped into grids . Set of warps on a core are fine grain interleaved on pipeline to hide off-chip memory access latency. Threads in one CTA can communicate via an on chip 16KB shared memory .")
12
Interconnection Network
Baseline: Mesh Variations: Crossbar, Ring, Torus Baseline mesh memory controller placement:

13
Are more threads better?
More CTAs on a core Helps hide the latency when some wait for barriers Can increase memory latency tolerance Needs more resources Less CTAs on a core Less contention in interconnection and memory system

14
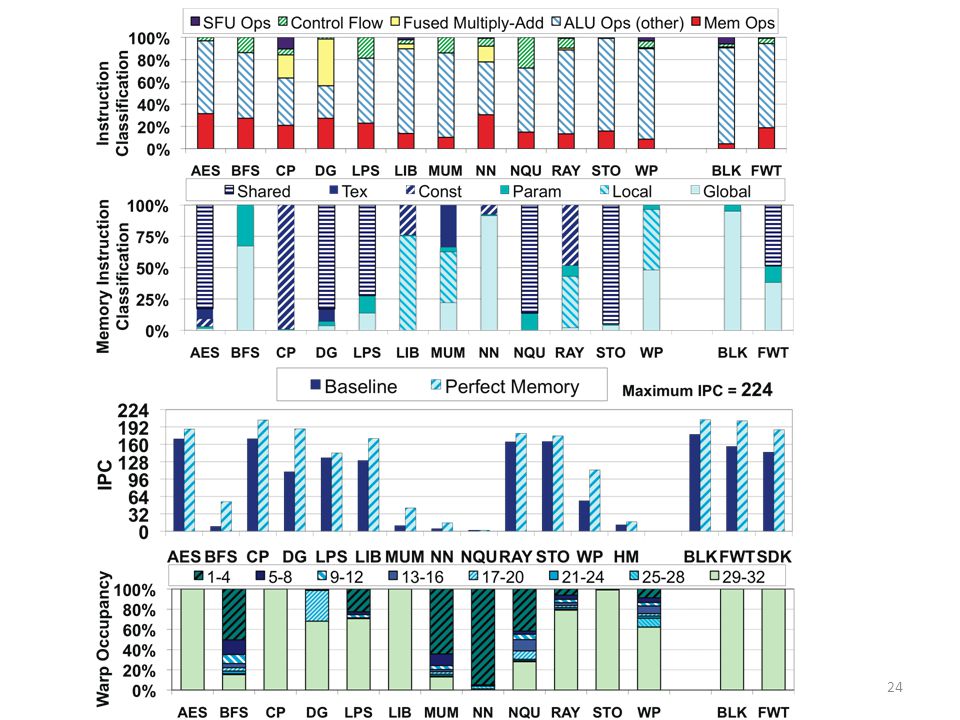
Memory Access Coalescing
Grouping accesses from multiple, concurrently issued, scalar threads into a single access to a contiguous memory region Is always done for a single warp Coalescing among multiple warps We explore its performance benefits Is more expensive to implement

15
Simulation setup Number of shader cores 28 Warp Size 32
SIMD pipeline width 8 # of Threads/CTAs/Registers per Core 1024 / 8 /16384 Shared Memory / Core 16KB (16 banks) Constant Cache / Core 8KB (2-way set assoc. 64B lines LRU) Texture Cache / Core 64KB (2-way set assoc. 64B lines LRU) Memory Channels BW / Memory Module 8 Byte/Cycle DRAM request queue size Memory Controller Out of order (FR-FCFS) Branch Divergence handling method Immediate Post Dominator Warp Scheduling Policy Round Robin among ready Warps
 Constant Cache / Core. 8KB (2-way set assoc. 64B lines LRU) Texture Cache / Core. 64KB (2-way set assoc. 64B lines LRU) Memory Channels. BW / Memory Module. 8 Byte/Cycle. DRAM request queue size. Memory Controller. Out of order (FR-FCFS) Branch Divergence handling method. Immediate Post Dominator. Warp Scheduling Policy. Round Robin among ready Warps.")
16
Benchmark Selection Applications developed by 3rd party researchers
Less than 50x reported speedups + some applications from CUDA SDK

17
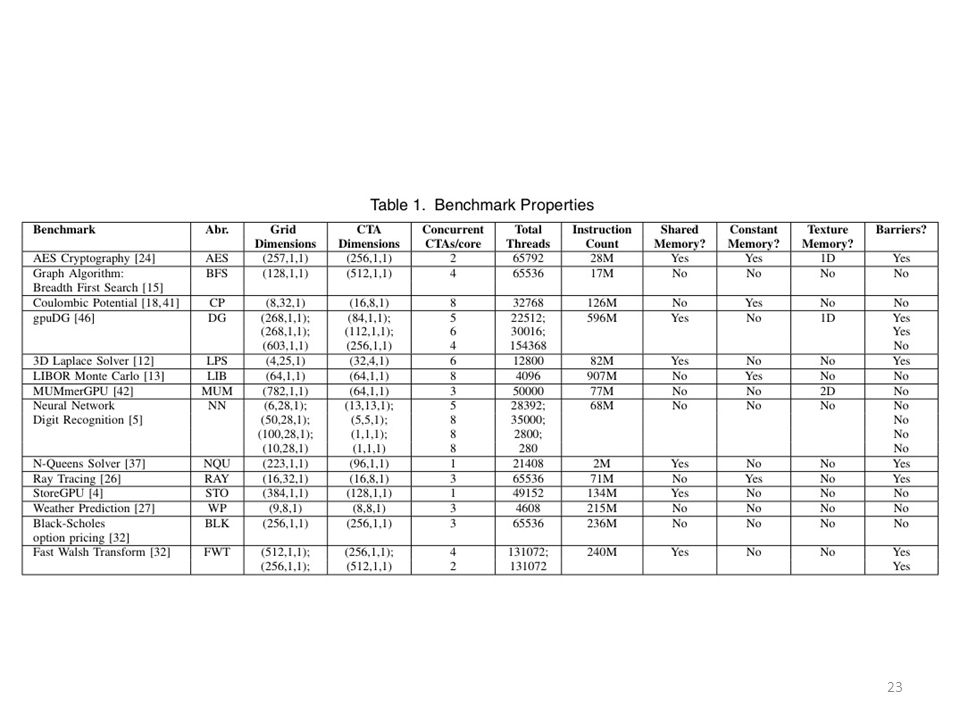
Benchmarks (more info in paper)
Abbr. Claimed Speedup AES Cryptography AES 12x Breadth First Search BFS 2x-3x Coulombic Potential CP 647x gpuDG DG 50x 3D Laplace Solver LPS LIBOR Monte Carlo LIB MUMmerGPU MUM 3.5x-10x Neural Network NN 10x N-Queens Solver NQU 2.5x Ray Tracing RAY 16x StoreGPU STO 9x Weather Prediction WP 20x

18
Interconnection Network Latency Sensitivity
Slight increase in interconnection latency has no severe effect of overall performance No need to overdesign interconnection to decrease latency

19
Interconnection Network Bandwidth Sensitivity
Low Bandwidth decreases performance a lot (8B) Very high bandwidth moves the bottleneck
 Very high bandwidth moves the bottleneck.")
20
Effects of varying number of CTAs
Most benchmarks do not benefit substantially Some benchmarks even perform better with fewer concurrent threads (e.g. AES) Less contention in DRAM
 Less contention in DRAM.")
21
More insights and data in the paper…

22
Summary GPGPU-Sim: a novel GPU simulator
Capable of simulating CUDA applications Performance of simulated applications More sensitive to bisection BW Less sensitive to (zero load) Latency Sometimes running fewer CTAs can improve performance (less DRAM contention)
 Latency. Sometimes running fewer CTAs can improve performance (less DRAM contention)")
25
Interconnect Topology (Fig 9)
")
26
ICNT Latency and BW sensitivity (Fig 10-11)
")
27
Mem Controller Optimization Effects (Fig 12)
")
28
DRAM Utilization and Efficiency (Fig 13 -14)
")
29
L1 / L2 Cache (Fig 15)
")
30
Varying CTAs (Fig 16)
")
31
Inter-Warp Coalescing (Fig 17)
")
Similar presentations









 Aware Scheduling Techniques for Improving GPGPU Performance Adwait Jog, Onur Kayiran, Nachiappan CN, Asit Mishra, Mahmut.>")





 – handin cs6963 prop March 31, MIDTERM in class L15: Review.>")

 Supercomputing for the Masses by Peter Zalutski.>")

 GPU is the chip in computer video cards, PS3, Xbox, etc – Designed to realize the 3D graphics pipeline.>")