Download presentation
Presentation is loading. Please wait.

1
GPU Programming and CUDA Sathish Vadhiyar Parallel Programming

2
GPU Graphical Processing Unit A single GPU consists of large number of cores – hundreds of cores. Whereas a single CPU can consist of 2, 4, 8 or 12 cores Cores? – Processing units in a chip sharing at least the memory and L1 cache

3
GPU and CPU Typically GPU and CPU coexist in a heterogeneous setting “Less” computationally intensive part runs on CPU (coarse- grained parallelism), and more intensive parts run on GPU (fine-grained parallelism) NVIDIA’s GPU architecture is called CUDA (Compute Unified Device Architecture) architecture, accompanied by CUDA programming model, and CUDA C language
, and more intensive parts run on GPU (fine-grained parallelism) NVIDIA’s GPU architecture is called CUDA (Compute Unified Device Architecture) architecture, accompanied by CUDA programming model, and CUDA C language")
4
Example: SERC system SERC system had 4 nodes Each node has 16 CPU cores arranges as four quad cores Each node connected to a Tesla S1070 GPU system

5
Tesla S1070 Each Tesla S1070 system has 4 Tesla GPUs (T10 processors) in the system The system connected to one or two host systems via high speed interconnects Each GPU has 240 GPU cores. Hence a total of about 960 cores Frequency of processor cores – 1.296 to 1.44 GHz Memory – 16 GB total, 4 GB per GPU

6
Tesla S1070 Architecture

7
Tesla T10 240 streaming processors/cores (SPs) organized as 30 streaming multiprocessors (SMs) in 10 independent processing units called Texture Processors/Clusters (TPCs) A TPC consists of 3 SMs; A SM consists of 8 SPs 30 DP processors 128 threads per processor; 30,720 threads total Collection of TPCs is called Streaming Processor Arrays (SPAs)
 organized as 30 streaming multiprocessors (SMs) in 10 independent processing units called Texture Processors/Clusters (TPCs) A TPC consists of 3 SMs; A SM consists of 8 SPs 30 DP processors 128 threads per processor; 30,720 threads total Collection of TPCs is called Streaming Processor Arrays (SPAs)")
8
Tesla S1070 Architecture Details

9
T 10 Host

10
TPCs, SMs, SPs

11
Connection to Host, Interconnection Network

12
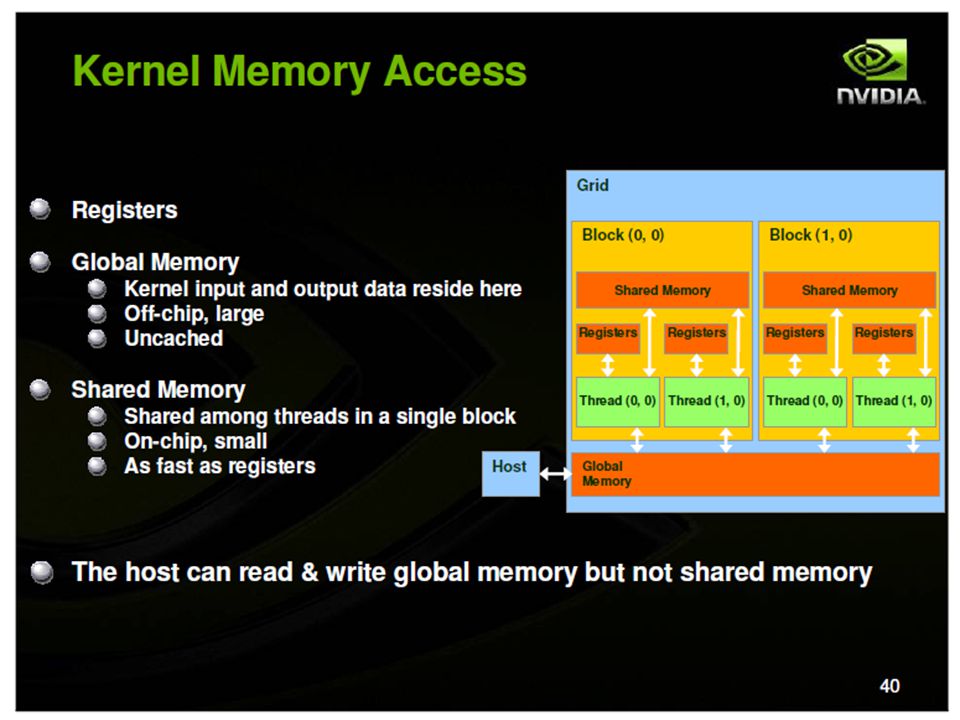
Details of SM Each SM has a shared memory

13
Multithreading SM manages and executes up to 768 concurrent threads in hardware with zero scheduling overhead Concurrent threads synchronize using barrier using a single SM instruction These support efficient very fine-grained parallelism Group of threads executes the same program and different groups executes different programs

14
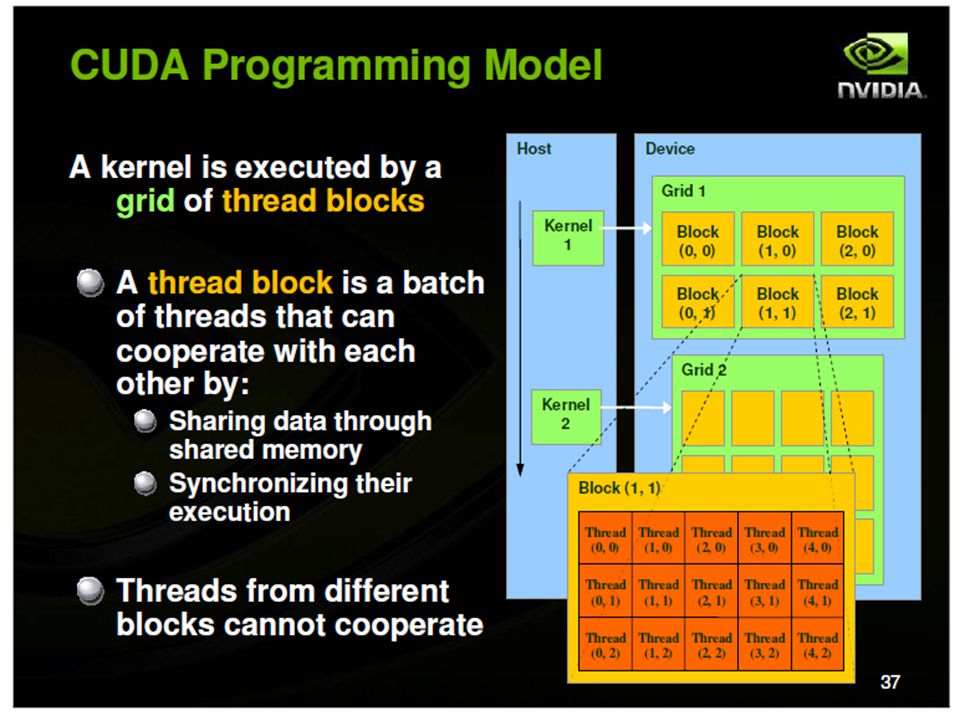
Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single block assigned to a single SM. Multiple blocks can be assigned to a SM. Block consists of elements Elements computed by threads

15
Hierarchical Parallelism

16
Thread Blocks Thread block – an array of concurrent threads that execute the same program and can cooperate to compute the result Consists of 1 to 512 threads Has shape and dimensions (1d, 2d or 3d) for threads A thread ID has corresponding 1,2 or 3d indices Each SM executes up to eight thread blocks concurrently Threads of a thread block share memory
 for threads A thread ID has corresponding 1,2 or 3d indices Each SM executes up to eight thread blocks concurrently Threads of a thread block share memory")
21
CUDA Programming Language Programming language for threaded parallelism for GPUs Minimal extension of C A serial program that calls parallel kernels Serial code executes on CPU Parallel kernels executed across a set of parallel threads on the GPU Programmer organizes threads into a hierarchy of thread blocks and grids

23
CUDA language A kernel corresponds to a grid. __global__ - denotes kernel entry functions __device__ - global variables __shared__ - shared memory variables A kernel text is a C function for one sequential thread

24
CUDA C Built-in variables: – threadIdx.{x,y,z} – thread ID within a block – blockIDx.{x,y,z} – block ID within a grid – blockDim.{x,y,z} – number of threads within a block – gridDim.{x,y,z} – number of blocks within a grid kernel >>(args) – Invokes a parallel kernel function on a grid of nBlocks where each block instantiates nThreads concurrent threads
 – Invokes a parallel kernel function on a grid of nBlocks where each block instantiates nThreads concurrent threads")
25
Example: Summing Up kernel function grid of kernels

27
General CUDA Steps 1.Copy data from CPU to GPU 2.Compute on GPU 3.Copy data back from GPU to CPU By default, execution on host doesn’t wait for kernel to finish General rules: – Minimize data transfer between CPU & GPU – Maximize number of threads on GPU

28
CUDA Elements cudaMalloc – for allocating memory in device cudaMemCopy – for copying data to allocated memory from host to device, and from device to host cudaFree – freeing allocated memory void syncthreads__() – synchronizing all threads in a block like barrier CUDA has atomic in-built functions (add, sub etc.), error reporting Event management:
 – synchronizing all threads in a block like barrier CUDA has atomic in-built functions (add, sub etc.), error reporting Event management:")
31
EXAMPLE 2: REDUCTION

32
Example: Reduction Tree based approach used within each thread block In this case, partial results need to be communicated across thread blocks Hence, global synchronization needed across thread blocks

33
Reduction But CUDA does not have global synchronization – – expensive to build in hardware for large number of GPU cores Solution Decompose into multiple kernels Kernel launch serves as a global synchronization point

34
Illustration

35
Host Code int main(){ int* h_idata, h_odata; /* host data*/ Int *d_idata, d_odata; /* device data*/ /* copying inputs to device memory */ cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice) ; cudaMemcpy(d_odata, h_idata, numBlocks*sizeof(int), cudaMemcpyHostToDevice) ; int numThreads = (n < maxThreads) ? n : maxThreads; int numBlocks = n / numThreads; dim3 dimBlock(numThreads, 1, 1); dim3 dimGrid(numBlocks, 1, 1); reduce >>(d_idata, d_odata);
; dim3 dimGrid(numBlocks, 1, 1); reduce >>(d_idata, d_odata);.")
36
Host Code int s=numBlocks; while(s > 1) { numThreads = (s< maxThreads) ? s : maxThreads; numBlocks = s / numThreads; dimBlock(numThreads, 1, 1); dimGrid(numBlocks, 1, 1); reduce >>(d_idata, d_odata); s = s / threads; }
; dimGrid(numBlocks, 1, 1); reduce >>(d_idata, d_odata); s = s / threads; }.")
37
Device Code __global__ void reduce(int *g_idata, int *g_odata) { extern __shared__ int sdata[]; // load shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }
![Device Code __global__ void reduce(int *g_idata, int *g_odata) { extern __shared__ int sdata[]; // load shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }](http://images.slideplayer.com/14/4487248/slides/slide_37.jpg "Device Code __global__ void reduce(int *g_idata, int *g_odata) { extern __shared__ int sdata[]; // load shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }")
38
EXAMPLE 3: SCAN

39
Example: Scan or Parallel-prefix sum Using binary tree An upward reduction phase (reduce phase or up- sweep phase) – Traversing tree from leaves to root forming partial sums at internal nodes Down-sweep phase – Traversing from root to leaves using partial sums computed in reduction phase
 – Traversing tree from leaves to root forming partial sums at internal nodes Down-sweep phase – Traversing from root to leaves using partial sums computed in reduction phase")
40
Up Sweep

41
Down Sweep

42
Host Code int main(){ const unsigned int num_threads = num_elements / 2; /* cudaMalloc d_idata and d_odata */ cudaMemcpy( d_idata, h_data, mem_size, cudaMemcpyHostToDevice) ); dim3 grid(256, 1, 1); dim3 threads(num_threads, 1, 1); scan >> (d_odata, d_idata); cudaMemcpy( h_data, d_odata[i], sizeof(float) * num_elements, cudaMemcpyDeviceToHost /* cudaFree d_idata and d_odata */ }
![Host Code int main(){ const unsigned int num_threads = num_elements / 2; /* cudaMalloc d_idata and d_odata */ cudaMemcpy( d_idata, h_data, mem_size, cudaMemcpyHostToDevice) ); dim3 grid(256, 1, 1); dim3 threads(num_threads, 1, 1); scan >> (d_odata, d_idata); cudaMemcpy( h_data, d_odata[i], sizeof(float) * num_elements, cudaMemcpyDeviceToHost /* cudaFree d_idata and d_odata */ }](http://images.slideplayer.com/14/4487248/slides/slide_42.jpg "Host Code int main(){ const unsigned int num_threads = num_elements / 2; /* cudaMalloc d_idata and d_odata */ cudaMemcpy( d_idata, h_data, mem_size, cudaMemcpyHostToDevice) ); dim3 grid(256, 1, 1); dim3 threads(num_threads, 1, 1); scan >> (d_odata, d_idata); cudaMemcpy( h_data, d_odata[i], sizeof(float) * num_elements, cudaMemcpyDeviceToHost /* cudaFree d_idata and d_odata */ }")
43
Device Code __global__ void scan_workefficient(float *g_odata, float *g_idata, int n) { // Dynamically allocated shared memory for scan kernels extern __shared__ float temp[]; int thid = threadIdx.x; int offset = 1; // Cache the computational window in shared memory temp[2*thid] = g_idata[2*thid]; temp[2*thid+1] = g_idata[2*thid+1]; // build the sum in place up the tree for (int d = n>>1; d > 0; d >>= 1) { __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; temp[bi] += temp[ai]; } offset *= 2; }
![Device Code __global__ void scan_workefficient(float *g_odata, float *g_idata, int n) { // Dynamically allocated shared memory for scan kernels extern __shared__ float temp[]; int thid = threadIdx.x; int offset = 1; // Cache the computational window in shared memory temp[2*thid] = g_idata[2*thid]; temp[2*thid+1] = g_idata[2*thid+1]; // build the sum in place up the tree for (int d = n>>1; d > 0; d >>= 1) { __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; temp[bi] += temp[ai]; } offset *= 2; }](http://images.slideplayer.com/14/4487248/slides/slide_43.jpg "Device Code __global__ void scan_workefficient(float *g_odata, float *g_idata, int n) { // Dynamically allocated shared memory for scan kernels extern __shared__ float temp[]; int thid = threadIdx.x; int offset = 1; // Cache the computational window in shared memory temp[2*thid] = g_idata[2*thid]; temp[2*thid+1] = g_idata[2*thid+1]; // build the sum in place up the tree for (int d = n>>1; d > 0; d >>= 1) { __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; temp[bi] += temp[ai]; } offset *= 2; }")
44
Device Code // scan back down the tree // clear the last element if (thid == 0) temp[n - 1] = 0; // traverse down the tree building the scan in place for (int d = 1; d < n; d *= 2) { offset >>= 1; __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; float t = temp[ai]; temp[ai] = temp[bi]; temp[bi] += t; } __syncthreads(); // write results to global memory g_odata[2*thid] = temp[2*thid]; g_odata[2*thid+1] = temp[2*thid+1]; }
![Device Code // scan back down the tree // clear the last element if (thid == 0) temp[n - 1] = 0; // traverse down the tree building the scan in place for (int d = 1; d < n; d *= 2) { offset >>= 1; __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; float t = temp[ai]; temp[ai] = temp[bi]; temp[bi] += t; } __syncthreads(); // write results to global memory g_odata[2*thid] = temp[2*thid]; g_odata[2*thid+1] = temp[2*thid+1]; }](http://images.slideplayer.com/14/4487248/slides/slide_44.jpg "Device Code // scan back down the tree // clear the last element if (thid == 0) temp[n - 1] = 0; // traverse down the tree building the scan in place for (int d = 1; d < n; d *= 2) { offset >>= 1; __syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; float t = temp[ai]; temp[ai] = temp[bi]; temp[bi] += t; } __syncthreads(); // write results to global memory g_odata[2*thid] = temp[2*thid]; g_odata[2*thid+1] = temp[2*thid+1]; }")
45
Arrays of Arbitrary Size The previous code works for only arrays that can fit inside a single thread block For large arrays: – Divide arrays into blocks – Perform scan using previous algorithm for each thread block – And then scan the block sums – Illustrated by a diagram

46
Illustration

47
EXAMPLE 4: MATRIX MULTIPLICATION

49
Example 4: Matrix Multiplication

50
Example 4

54
Others CUDA has built-in libraries including cuBLAS, cuFFT, and SDKs (software development kit) for financial, image processing, etc.
 for financial, image processing, etc.")
55
For more information… CUDA SDK code samples – NVIDIA - http://www.nvidia.com/object/cuda_get_sam ples.html http://www.nvidia.com/object/cuda_get_sam ples.html

56
Backup

57
Host Code int main(){ prescanArrayRecursive(); } void prescanArray(float *outArray, float *inArray, int numElements) { prescanArrayRecursive(outArray, inArray, numElements, 0); } void prescanArrayRecursive(float *outArray, const float *inArray, int numElements, int level) { unsigned int blockSize = BLOCK_SIZE; // max size of the thread blocks unsigned int numBlocks = max(1, (int)ceil((float)numElements / (2.f * blockSize))); unsigned int numThreads; if (numBlocks > 1) numThreads = blockSize; else numThreads = numElements / 2; dim3 grid(max(1, numBlocks - np2LastBlock), 1, 1); dim3 threads(numThreads, 1, 1);
{ prescanArrayRecursive(); } void prescanArray(float *outArray, float *inArray, int numElements) { prescanArrayRecursive(outArray, inArray, numElements, 0); } void prescanArrayRecursive(float *outArray, const float *inArray, int numElements, int level) { unsigned int blockSize = BLOCK_SIZE; // max size of the thread blocks unsigned int numBlocks = max(1, (int)ceil((float)numElements / (2.f * blockSize))); unsigned int numThreads; if (numBlocks > 1) numThreads = blockSize; else numThreads = numElements / 2; dim3 grid(max(1, numBlocks - np2LastBlock), 1, 1); dim3 threads(numThreads, 1, 1);")
58
Host Code // execute the scan if (numBlocks > 1) { prescan >>(outArray, inArray, g_scanBlockSums[level], numThreads * 2, 0, 0); // After scanning all the sub-blocks, we are mostly done. But now we need to take all of the last values of the sub-blocks and scan those. // This will give us a new value that must be sdded to each block to get the final results. // recursive (CPU) call prescanArrayRecursive(g_scanBlockSums[level], g_scanBlockSums[level], numBlocks, level+1); uniformAdd >>(outArray, g_scanBlockSums[level], numElements, 0, 0); } else prescan >>(outArray, inArray, 0, numThreads * 2, 0, 0); }
![Host Code // execute the scan if (numBlocks > 1) { prescan >>(outArray, inArray, g_scanBlockSums[level], numThreads * 2, 0, 0); // After scanning all the sub-blocks, we are mostly done.](http://images.slideplayer.com/14/4487248/slides/slide_58.jpg "But now we need to take all of the last values of the sub-blocks and scan those. // This will give us a new value that must be sdded to each block to get the final results. // recursive (CPU) call prescanArrayRecursive(g_scanBlockSums[level], g_scanBlockSums[level], numBlocks, level+1); uniformAdd >>(outArray, g_scanBlockSums[level], numElements, 0, 0); } else prescan >>(outArray, inArray, 0, numThreads * 2, 0, 0); }.")
Similar presentations