Download presentation
Presentation is loading. Please wait.

1
Mathew Alvino, Travis McBee, Heather Nelson, Todd Sullivan GPGPU: GPU Processing of Protein Structure Comparisons

2
Proteins are the essential building blocks of life Fold into complicated 3D structures Structure often determines function Goal of researchers is to determine 3D structure from amino acid sequence Prediction and retrieval algorithms very time consuming The Protein Folding Problem

3
Index-based Protein Substructure Alignments (IPSA) Large index of database proteins Map query into the index using several data structures Pharmaceuticals affected by protein interactions Substructure alignments useful to researchers Time consuming, but still faster than competitors Around 20 minutes per query Over 80,000 protein chains in Protein Data Bank (PDB) Growing dataset Provides real-time search engine
 Large index of database proteins Map query into the index using several data structures Pharmaceuticals affected by protein interactions Substructure alignments useful to researchers Time consuming, but still faster than competitors Around 20 minutes per query Over 80,000 protein chains in Protein Data Bank (PDB) Growing dataset Provides real-time search engine")
4
Response Time of IPSA versus Competitors Speedup DALI37.66 CE2.78

5
Accuracy of IPSA versus Competitors

6
Market Analysis Bioinformatics Research Pharmaceutical Industry Nearly $1 Billion per year (Tufts Center for the Study of Drug Development) General-Purpose computing on the GPU (GPGPU) a fast-growing field 1 of 5 disruptive technologies for 2007 (InformationWeek)
 General-Purpose computing on the GPU (GPGPU) a fast-growing field 1 of 5 disruptive technologies for 2007 (InformationWeek)")
7
Goals and Objectives Gain experience with GPGPU Evaluate feasibility of a GPU-based IPSA algorithm The team's ultimate goal is to port portions of IPSA to run on the GPU Faster (Better average response time) More scalable as the dataset size increases
 More scalable as the dataset size increases")
8
Costs Computer 1 Hardware NVIDIA 8800 GTX costs: $575 Other machine costs: $1,200 Computer 2 Hardware ATI x800 XT PE: $250 Other machine costs: $950 Time Average of eight hours a week per team member. 32 hours a week total. Ten weeks total. 320 hours total. 320 hours @ $50 per hour = $16,000

9
Operating Environment Requirements Computer 1 NVIDIA 8800 GTX video card 128 processing cores 768 MB of memory Intel Pentium 4 2.8 GHz 4 Gigabytes of Ram Linux Operating System Computer 2 ATI x800 XT PE video card 256 MB of memory AMD64 3400 + 3 Gigabytes of Ram Windows XP/Cygwin

10
Environmental Constraints Stand-Alone System User sends data and system handles the rest. Quality Needs to produce responses faster than they can be produced on the CPU. Reliability System needs to be able to handle multiple requests at once. Coding IPSA is in Java GPGPU code needs to be in C

11
Project Schedule

12
GPGPU Technologies Base Technologies: OpenGL Shading Language DirectX Cg Commercial Products: RapidMind Peakstream Other Languages/Extensions: Sh Shallows Accelerator Brook CUDA

13
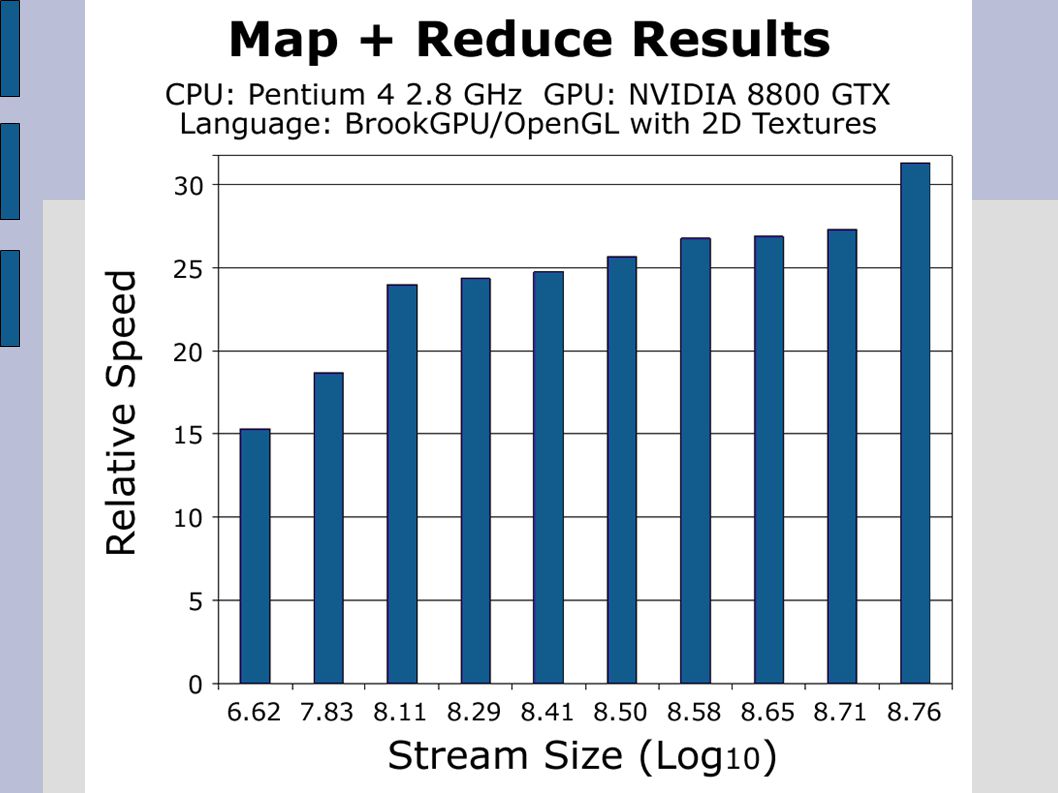
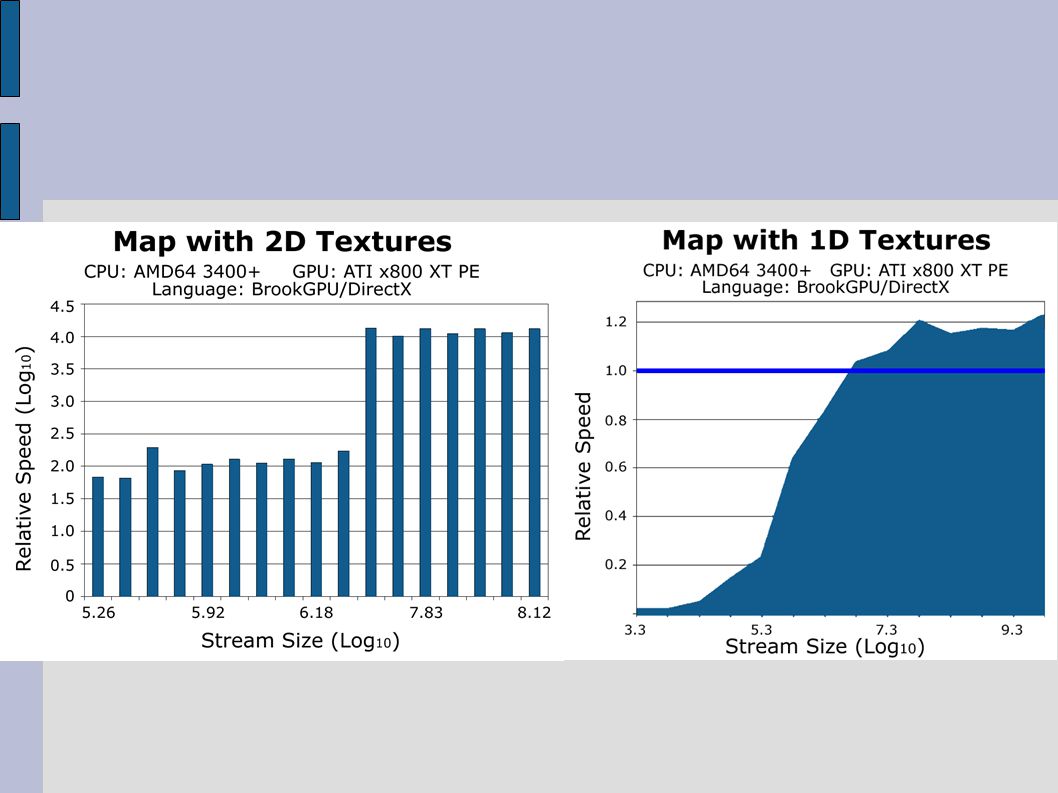
BrookGPU Performance Buck, I.; et al. “Brook for GPUs: stream computing on graphics hardware,” ACM SIGGRAPH 2004 Papers, pp. 777-786, Aug. 2004

14
GPU Pipeline

15
Mapping CPU Algorithms to the GPU Arrays = Textures Memory Read = Sample Texture Loop = Fragment Program (Kernel) Array Write = Render to Texture
 Array Write = Render to Texture")
16
Basic GPGPU Operations Map Applying a function to a given set of data elements Reduce Reducing the size of a data stream, usually until only one element remains. Example: Given an array A of data in range [0.0, 1.0) Map the data to the range [0, 255] by the function f(x) = Floor( x * 256 ) Reduce the array to one element by the summation ∑ f(X i ) for all X i in A
 Map the data to the range [0, 255] by the function f(x) = Floor( x * 256 ) Reduce the array to one element by the summation ∑ f(X i ) for all X i in A.")
18
Issues and Limitations Generally impossible to directly translate CPU algorithms to GPU 2D textures (arrays) most efficient Translate 1D/3D into 2D Branching very costly No random access memory – avoid lookups Often must divide code into multiple shaders for even the most simple computations Data transfer from CPU to GPU very costly
 most efficient Translate 1D/3D into 2D Branching very costly No random access memory – avoid lookups Often must divide code into multiple shaders for even the most simple computations Data transfer from CPU to GPU very costly")
19
Issues and Limitations cont. Highly computational and parallelizable code has most potential Even parallel algorithms can be inefficient if they overuse branching and memory lookups Limit number of passes over textures Do as much as possible at one time GPUs use single-precision floating point numbers. IPSA uses double-precision floating point numbers.

21
Implementing GPGPU using Cg Initialize data and libraries Create frame buffer object for off-screen rendering Create textures Generate, setup, and transfer data from CPU Initialize Cg Create fragment profile, bind fragment program to shader, load program Perform computation Enable profile, bind program, draw buffer and enable textures as necessary Transfer texture from GPU

22
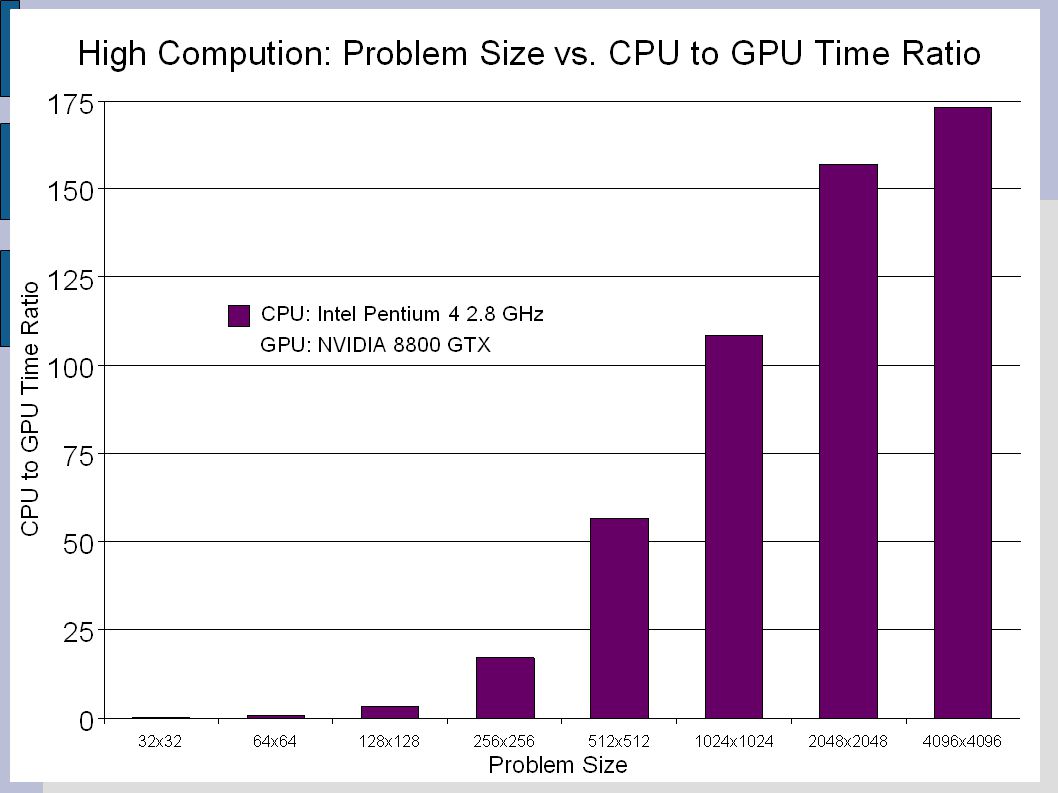
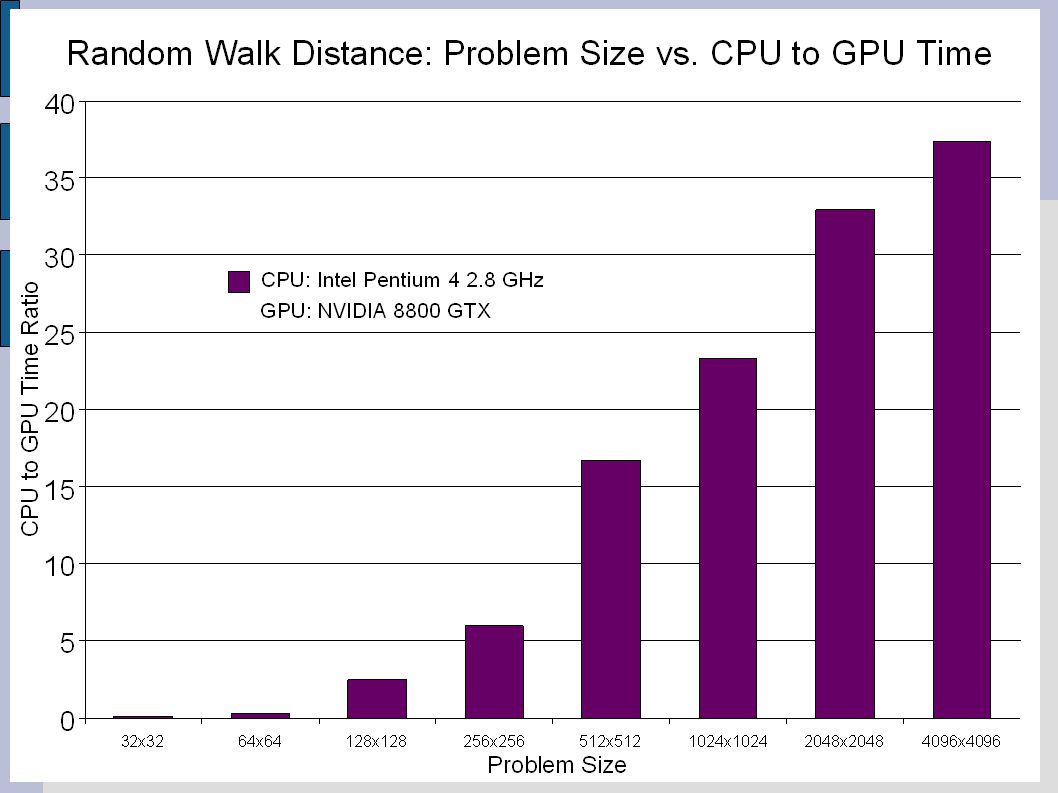
Cg Implementations Mathematical computation over each element y = alpha*y+ (alpha+y)/(alpha*y)*alpha 175 times faster than CPU on 4096x4096 dataset Average Random Walk Distance Useful in protein folding problems 40 times faster on GPU for 4096x4096 dataset Multiple shaders necessary Summation of each element diminishes performance
/(alpha*y)*alpha 175 times faster than CPU on 4096x4096 dataset Average Random Walk Distance Useful in protein folding problems 40 times faster on GPU for 4096x4096 dataset Multiple shaders necessary Summation of each element diminishes performance")
25
IPSA Profile Layer 1

26
IPSA Profile Layer 2

27
IPSA: High Level Process Diagram

28
GPU Modified IPSA: High Level Process Diagram Compute D1

29
Array Translation Each pixel on a texture contains four floats – Red, Green, Blue, and Alpha Need to convert all arrays of floats to array of float4’s IPSA calculates most values in groups of three – Leave the alpha float empty (unused) Array of 3x3 Matrices CPU Memory: 1D Array of float4’s. Each square contains the three values of the same color from the array of 3x3 matrices.

30
Chain Translation Need to compute many chain comparisons at once. – Solution: Pack chains into a giant texture. Chains are either 30 or 45 floats long Each chain fits into a 4x4 of float4’s Each block contains three floats in the pixel’s RGB values Alpha values are set to zero White blocks contain zeroes on RGBA

31
Code Translation: Floats to Float4’s Calculation of tR in Compute D1: for( i = 0; i < AA_size; i++ ){ a1 = i * 3; a2 = a1 + 1; a3 = a2 + 1; tR[0][0] += chain1[a1] * chain2[a1]; tR[0][1] += chain1[a1] * chain2[a2]; tR[0][2] += chain1[a1] * chain2[a3]; tR[1][0] += chain1[a2] * chain2[a1]; tR[1][1] += chain1[a2] * chain2[a2]; tR[1][2] += chain1[a2] * chain2[a3]; tR[2][0] += chain1[a3] * chain2[a1]; tR[2][1] += chain1[a3] * chain2[a2]; tR[2][2] += chain1[a3] * chain2[a3]; } Translation to array of float4’s: for( i = 0; i < AA_size; i++ ){ tR[0].r += chain1[i].r * chain2[i].r; tR[0].g += chain1[i].r * chain2[i].g; tR[0].b += chain1[i].r * chain2[i].b; tR[1].r += chain1[i].g * chain2[i].r; tR[1].g += chain1[i].g * chain2[i].g; tR[1].b += chain1[i].g * chain2[i].b; tR[2].r += chain1[i].b * chain2[i].r; tR[2].g += chain1[i].b * chain2[i].g; tR[2].b += chain1[i].b * chain2[i].b; }
![Code Translation: Floats to Float4’s Calculation of tR in Compute D1: for( i = 0; i < AA_size; i++ ){ a1 = i * 3; a2 = a1 + 1; a3 = a2 + 1; tR[0][0] += chain1[a1] * chain2[a1]; tR[0][1] += chain1[a1] * chain2[a2]; tR[0][2] += chain1[a1] * chain2[a3]; tR[1][0] += chain1[a2] * chain2[a1]; tR[1][1] += chain1[a2] * chain2[a2]; tR[1][2] += chain1[a2] * chain2[a3]; tR[2][0] += chain1[a3] * chain2[a1]; tR[2][1] += chain1[a3] * chain2[a2]; tR[2][2] += chain1[a3] * chain2[a3]; } Translation to array of float4’s: for( i = 0; i < AA_size; i++ ){ tR[0].r += chain1[i].r * chain2[i].r; tR[0].g += chain1[i].r * chain2[i].g; tR[0].b += chain1[i].r * chain2[i].b; tR[1].r += chain1[i].g * chain2[i].r; tR[1].g += chain1[i].g * chain2[i].g; tR[1].b += chain1[i].g * chain2[i].b; tR[2].r += chain1[i].b * chain2[i].r; tR[2].g += chain1[i].b * chain2[i].g; tR[2].b += chain1[i].b * chain2[i].b; }](http://images.slideplayer.com/15/4825619/slides/slide_31.jpg "Code Translation: Floats to Float4’s Calculation of tR in Compute D1: for( i = 0; i < AA_size; i++ ){ a1 = i * 3; a2 = a1 + 1; a3 = a2 + 1; tR[0][0] += chain1[a1] * chain2[a1]; tR[0][1] += chain1[a1] * chain2[a2]; tR[0][2] += chain1[a1] * chain2[a3]; tR[1][0] += chain1[a2] * chain2[a1]; tR[1][1] += chain1[a2] * chain2[a2]; tR[1][2] += chain1[a2] * chain2[a3]; tR[2][0] += chain1[a3] * chain2[a1]; tR[2][1] += chain1[a3] * chain2[a2]; tR[2][2] += chain1[a3] * chain2[a3]; } Translation to array of float4’s: for( i = 0; i < AA_size; i++ ){ tR[0].r += chain1[i].r * chain2[i].r; tR[0].g += chain1[i].r * chain2[i].g; tR[0].b += chain1[i].r * chain2[i].b; tR[1].r += chain1[i].g * chain2[i].r; tR[1].g += chain1[i].g * chain2[i].g; tR[1].b += chain1[i].g * chain2[i].b; tR[2].r += chain1[i].b * chain2[i].r; tR[2].g += chain1[i].b * chain2[i].g; tR[2].b += chain1[i].b * chain2[i].b; }")
32
Code Translation: For Loop to Fragment Program For loop in float4 format: for (i = 0; i < AA_size; i++) { chain1[i].r = chain8[i].r – mean.r; chain1[i].g = chain8[i].g – mean.g; chain1[i].b = chain8[i].b – mean.b; } Pseudocode fragment program: kernel subtract( float4 c8pixel, float4 mean, out float4 c1pixel ){ c1pixel.r = c8pixel.r – mean.r; c1pixel.g = c8pixel.g – mean.g; c1pixel.b = c8pixel.b – mean.b; c1pixel.a = 0.0; } Operation: chain1 = chain8 – mean;
![Code Translation: For Loop to Fragment Program For loop in float4 format: for (i = 0; i < AA_size; i++) { chain1[i].r = chain8[i].r – mean.r; chain1[i].g = chain8[i].g – mean.g; chain1[i].b = chain8[i].b – mean.b; } Pseudocode fragment program: kernel subtract( float4 c8pixel, float4 mean, out float4 c1pixel ){ c1pixel.r = c8pixel.r – mean.r; c1pixel.g = c8pixel.g – mean.g; c1pixel.b = c8pixel.b – mean.b; c1pixel.a = 0.0; } Operation: chain1 = chain8 – mean;](http://images.slideplayer.com/15/4825619/slides/slide_32.jpg "Code Translation: For Loop to Fragment Program For loop in float4 format: for (i = 0; i < AA_size; i++) { chain1[i].r = chain8[i].r – mean.r; chain1[i].g = chain8[i].g – mean.g; chain1[i].b = chain8[i].b – mean.b; } Pseudocode fragment program: kernel subtract( float4 c8pixel, float4 mean, out float4 c1pixel ){ c1pixel.r = c8pixel.r – mean.r; c1pixel.g = c8pixel.g – mean.g; c1pixel.b = c8pixel.b – mean.b; c1pixel.a = 0.0; } Operation: chain1 = chain8 – mean;")
33
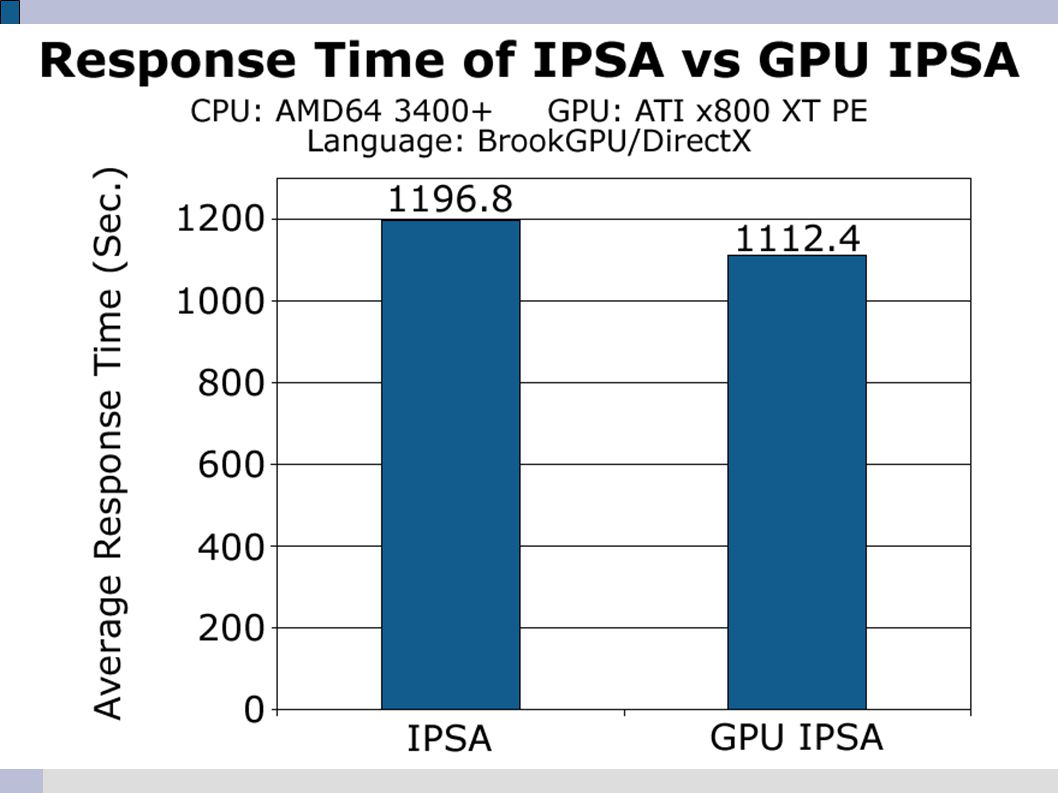
Results GPU version of Compute D1 calculates 102,400 chain comparisons simultaneously. GPU-based Compute D1 9.828 times faster than Java-based Compute D1. GPU IPSA is 1.076 times faster than IPSA Results in average response time of 1112.4 seconds. Cut 84 seconds off the total processing time.

35
Improvements/Future Work GPU performance gain is limited by: Small percentage of total processing time from the functions with GPU potential Compute D2 (2%) and Matrix Multiply (0.3%) Using only three of four floats in each pixel Unused float4’s from texture packing strategy Additional work: Compute D1 calculates eigenvalues and eigenvectors Extremely complicated task that was removed from the prototype and performance testing Modify IPSA to use GPU-calculated values GPU’s single-precision floats may affect IPSA accuracy
 and Matrix Multiply (0.3%) Using only three of four floats in each pixel Unused float4’s from texture packing strategy Additional work: Compute D1 calculates eigenvalues and eigenvectors Extremely complicated task that was removed from the prototype and performance testing Modify IPSA to use GPU-calculated values GPU’s single-precision floats may affect IPSA accuracy")
36
Questions?

Similar presentations









 Andrew Graff.>")









