Download presentation
Presentation is loading. Please wait.

2
The Human Genome, impact in the biomedical domain Sonia ABDELHAK, PhD Molecular Investigation of Genetic Orphan Disorders Institut Pasteur de Tunis

3
Human Genome Project Historical context. Goals of the HGP. Strategy. Results. Impact on Biomedical domain. Discussion.

4
« Finished » sequence April 1953-April 2003 February 2001

6
Brief history of HGP 1984 to 1986 – first proposed at US DOE meetings 1988 – endorsed by US National Research Council (Funded by NIH and US DOE $3 billion set aside) 1990 – Human Genome Project started (NHGRI) Later – UK, France, Japan, Germany, China 1998. Celera announces a 3-year plan to complete the project years early First draft published in Science and Nature in February, 2001 Finished Human Genome sequence published in Nature 2003.

7
Challenges Genome Attributes –Size –Polymorphism –Repeats (Smaller repeats are technically difficult to sequence, some sequences are repeated all over the genome: How can these be placed?). Available Technology –600 bp per read(Sequencing works by extension from a primer/ gel electrophoresis. Limited by resolution of gel). –Error (~1 error per 600. Sequencing multiple times decreases error; same error unlikely in multiple reads. 10x Coverage = error rate ~1/10,000). –Relies on cloning (Some regions are difficult to clone Heterochromatin; some sequences rearrange or are deleted when cloned)
. –Error (~1 error per 600. Sequencing multiple times decreases error; same error unlikely in multiple reads. 10x Coverage = error rate ~1/10,000). –Relies on cloning (Some regions are difficult to clone Heterochromatin; some sequences rearrange or are deleted when cloned).")
8
Goals of HGP Create a genetic and physical map of the 24 human chromosomes (22 autosomes, X & Y) Identify the entire set of genes & map them all to their chromosomes Determine the nucleotide sequence of the estimated 3 billion base pairs Analyze genetic variation among humans Map and sequence the genomes of model organisms
 Identify the entire set of genes & map them all to their chromosomes Determine the nucleotide sequence of the estimated 3 billion base pairs Analyze genetic variation among humans Map and sequence the genomes of model organisms")
9
Model organisms Bacteria (E. coli, influenza, several others) Yeast (Saccharomyces cerevisiae) Plant (Arabidopsis thaliana) Roundworm (Caenorhabditis elegans) Fruit fly (Drosophila melanogaster) Mouse (Mus musculus)
 Yeast (Saccharomyces cerevisiae) Plant (Arabidopsis thaliana) Roundworm (Caenorhabditis elegans) Fruit fly (Drosophila melanogaster) Mouse (Mus musculus).")
10
Goals of HGP (II) Develop new laboratory and computing technologies to make all this possible Disseminate genome information Consider ethical, legal, and social issues associated with this research
 Develop new laboratory and computing technologies to make all this possible Disseminate genome information Consider ethical, legal, and social issues associated with this research")
11
Time-line large scale genomic analysis

12
Identification de Polymorphismes de type microsatellites par analyse de séquence: tggtggcagaaatcattgtctgaaaagtaattgttttacttttattcttttcgtgtgtgtgtgtgt gtgtgtgtgtgtgtgtgtgtgtgtgtgtgtgcatgtgccagatttcttgtttgaaaggcaat gagcttcatccaagtatcaa IL-12p35AC F IL-12p35AC R atttcaggtgtgagccactgtgcctggccagaactttttcaatgaatattcaagataattgtata cacattttatatatatatatatatatacacacacacacacacacacatatgtatacacaca ttatatatataatccatgttatatacatctctacattatatatatccactatatatattttacttataca tatagattttatttttatgaactaggatcaaattgta IL-12p40AC F IL-12p40AC R 78.57% 69.23% 174 170 166 1 2 3 4 5

13
EST Division: Expressed Sequence Tags 80-100,000 RNA gene products nucleus 80-100,000 genes 80-100,000 unique cDNA clones in library - isolate unique clones - sequence once from each end TAGTCA CGTACT sequence1 sequence2 clone xyz make cDNA library ESTs dbEST http://www.ncbi.nlm.nih.gov/dbEST/ >IMAGE:275615 3', mRNA sequence NNTCAAGTTTTATGATTTATTTAACTTGTGGAACAAAAATAAACCAGATTAACCACAACCATGCCTTACT TTATCAAATGTATAAGANGTAAATATGAATCTTATATGACAAAATGTTTCATTCATTATAACAAATTTCC AATAATCCTGTCAATNATATTTCTAAATTTTCCCCCAAATTCTAAGCAGAGTATGTAAATTGGAAGTTAA CTTATGCACGCTTAACTATCTTAACAAGCTTTGAGTGCAAGAGATTGANGAGTTCAAATCTGACCAAGAT GTTGATGTTGGATAAGAGAATTCTCTGCTCCCCACCTCTANGTTGCCAGCCCTC >IMAGE:275615 5' mRNA sequence GACAGCATTCGGGCCGAGATGTCTCGCTCCGTGGCCTTAGCTGTGCTCGCGCTACTCTCTCTTTCTGGCC TGGAGGTATCCAGCGTACTCCAAAGATTCAGGTTTACTCACGTCATCCAGCAGAGAATGGAAAGTCAAAT TTCCTGAATTGCTATGTGTCTGGGTTTCATCCATCCGACATTGAAGTTGACTTACTGAAGAATGGAGAGA GAATTGAAAAAGTGGAGCATTCAGACTTGTCTTTCAGCAAGGACTGGTCTTTCTATCTCTTGTACTACAC TGAATTCACCCCCACTGAAAAAGATGAGTATGCCTGCCGTGTTGAACCATGTNGACTTTGTCACAGNCCC AAGTTNAGTTTAAGTGGGNATCGAGACATGTAAGGCAGGCATCATGGGAGGTTTTGAAGNATGCCGCNTT TTGGATTGGGATGAATTCCAAATTTCTGGTTTGCTTGNTTTTTTAATATTGGATATGCTTTTG

14
A A G C T AT A G C TA A G CT A GC AG Electrophorèse Gel plat / capillaire A G CT AT Analyse automatique dépot détection Chimie de séquençage Dye Terminator (6) amorce T C G A T A ADN Taq A G C T A T... réaction de séquence

15
Two Competing Strategies for Human Genome (Hierarchical shotgun) [Public human genome project] Whole-genome Shotgun [Celera project]
![Two Competing Strategies for Human Genome (Hierarchical shotgun) [Public human genome project] Whole-genome Shotgun [Celera project]](http://images.slideplayer.com/1/463866/slides/slide_15.jpg "Two Competing Strategies for Human Genome (Hierarchical shotgun) [Public human genome project] Whole-genome Shotgun [Celera project]")
16
Sequencing BAC: Bacterial Artificial Chromosome clone Contig: joined overlapping collection of sequences or clones.

17
Whole-genome shotgun sequencing Private company Celera used to sequence whole human genome Whole genome randomly sheared three times –Plasmid library constructed with ~ 2kb inserts –Plasmid library with ~10 kb inserts –BAC library with ~ 200 kb inserts Computer program assembles sequences into chromosomes No physical map construction Only one BAC library Reduces problems of repeat sequences

18
Vérification de la qualité de séquence Elimination des séquences contaminantes Blastn contre des banques de vecteurs, de bactéries, levures,… Assemblage, Phred, Phrap, Consed Identification des séquences potentiellement codantes Comparaison avec les banques de données, Logiciels de prédictions dexons. Différentes étapes danalyse de séquence A G CT AT

20
GenBan k DDBJ EMBL EMBL Entrez SRS getentry NIG CIB EBI NCBI NIH Submissions Updates Submissions Updates Submissions Updates

21
HTG Division: High Throughput Genome Records 40,000 to > 350,000 bp phase 1 phase 2 phase 3 HTG PRI Acc = AC008701 gi = 6601005 Acc = AC008701 gi = 6671909 Acc = AC008701 gi = 7328720

22
2.88 Gbp 2,851,330,913

26
Gene prediction Easy for procaryotes (single cell) – one gene, one protein More difficult for eukaryotes (multicell) – one gene, many proteins Very difficult for Human – short exons separated by non-coding long introns
 – one gene, one protein More difficult for eukaryotes (multicell) – one gene, many proteins Very difficult for Human – short exons separated by non-coding long introns")
27
Gene recognition Coding region and non-coding region have different sequence profiles –coding region is protected from mutation and is less random Gene recognition by sequence alignment Gene prediction by Hidden Markov Model trained by set of known genes Many genes are homologs – similar in vastly different organisms

28
Two predictions disagree John B. Hogenesch, et al Cell, Vol. 106, 413–415 August 24, 2001 …predicted transcripts collectively contain partial matches to nearly all known genes, but the novel genes predicted by both groups are largely non-overlapping.

29
Human genome content The Human Genome Total length 3000 Mb ~ 40,000 genes (coding seq) Gene sequences < 5% Exons ~ 1.5% (coding) Introns ~ 3.5% (noncoding) Intergenic regions (junk) > 95% Repeats > 50%
 Gene sequences < 5% Exons ~ 1.5% (coding) Introns ~ 3.5% (noncoding) Intergenic regions (junk) > 95% Repeats > 50%")
30
Global properties Pericentromeric and subtelomeric regions of chromosomes filled with large recent transposable elements Marked decline in the overall activity of transposable elements or transposons Male mutation rate about twice female –most mutation occurs in males Recombination rates much higher in distal regions of chromosomes and on shorter chromosome arms –> one crossover per chromosome arm in each meiosis

32
Fig 17 transposables Classes of transposable elements. LINE, long interspersed element. SINE short interspersed element. Total 45% Interspersed repeats: fixed transposable elements copied to non-homologous regions.

33
Fig 21 Two regions of about 1 Mb on chromosomes 2 and 22. Red bars, interspersed repeats; blue bars, exons of known genes. Note the deficit of repeats in the HoxD cluster, which contains a collection of genes with complex, interrelated regulation. Genes are sometimes protected from repeats

34
Important features of Human proteome 30,000–40,000 protein-coding genes Proteome (full set of proteins) more complex than those of invertebrates. –pre-existing components arranged into a richer architectures. Hundreds of genes seem to come from horizontal transfer from bacteria questionable Dozens of genes seem to come from transposable elements.

35
Noncoding RNA genes Transfer RNAs (tRNAs) – adaptors that translate triplet code of RNA into amino acid sequence of proteins Ribosomal RNAs (rRNAs) – components of ribosome Small nucleolar RNAs (snoRNAs) – RNA processing and base modification in nucleolus Small nuclear RNAs (sncRNAs) - spliceosomes
 – adaptors that translate triplet code of RNA into amino acid sequence of proteins Ribosomal RNAs (rRNAs) – components of ribosome Small nucleolar RNAs (snoRNAs) – RNA processing and base modification in nucleolus Small nuclear RNAs (sncRNAs) - spliceosomes")
36
Human races have similar genes Genome sequence centers have sequenced significant portions of at least three races Range of polymorphisms within a race can be much greater than the range of differences between any two individuals of different race Very few genes are race specific

37
Genome Sizes (MegaBases)
")
38
Fig 35a Size distributions of exons in Human, Worm and Fly. Human have shorter exons.

39
Fig 35c Size distributions of intons in Human, Worm and Fly. Human have longer introns.

40
Complexity of proteome increase from yeast to humans –More genes –Shuffling, increase, or decrease of functional modules –Alternative RNA splicing – humans exhibit significantly more –Chemical modification of proteins is higher in humans

42
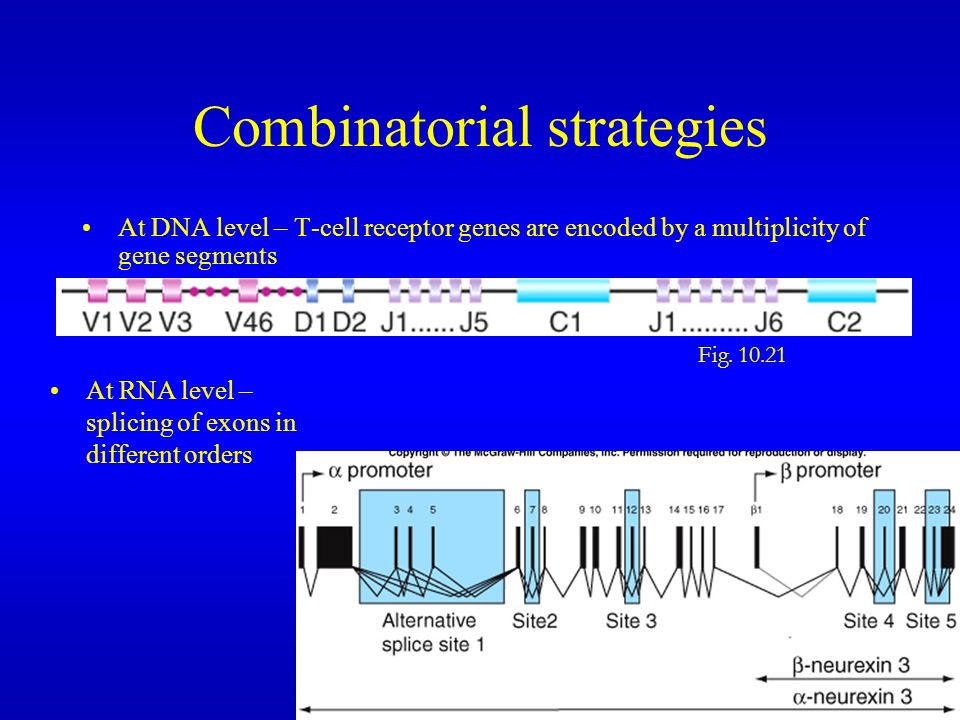
Combinatorial strategies At DNA level – T-cell receptor genes are encoded by a multiplicity of gene segments At RNA level – splicing of exons in different orders Fig. 10.21

43
Yeast 70 human genes are known to repair mutations in yeast Nearly all we know about cell cycle and cancer comes from studies of yeast Advantages: fewer genes (6000) few introns 31% of yeast genes give same products as human homologues
 few introns 31% of yeast genes give same products as human homologues")
44
Drosophila nearly all we know of how mutations affect gene function come from Drosophila studies We share 50% of their genes 61% of genes mutated in 289 human diseases are found in fruit flies 68% of genes associated with cancers are found in fruit flies Knockout mutants Homeobox genes

45
C. elegans 959 cells in the nervous system 131 of those programmed for apoptosis apoptosis involved in several human genetic neurological disorders Alzheimers Huntingtons Parkinsons

46
Mouse known as mini humans Very similar physiological systems Share 90% of their genes

47
Questions Remain about the Human Genome –Difficult to precisely estimate number of genes at this time Small genes are hard to identify Some genes are rarely expressed and do not have normal codon usage patterns – thus hard to detect

48
Impact of HG on Biomedical domain

49
Applications to medicine and biology Disease genes –human genomic sequence in public databases allows rapid identification of disease genes in silico Drug targets –pharmaceutical industry has depended upon a limited set of drug targets to develop new therapies –now can find new target in silico Basic biology –basic physiology, cell biology…

50
Hérédité liée au chromosome X

51
Hérédité autosomique dominante

52
Hérédité autosomique récessive A1A1A1A2 A1A1 A2A2 A1A2 Mm MMmm

53
Les mutations ponctuelles Création de codon stop CAGGln TAG

54
Disease Function/ Protein Gene Chromosomal localisation Disease Function/ Protein Gene Chromosomal localisation Positional cloning of genes

55
1 to 10 years!

56
123456789-11'1011 12 13 14 1516 IIIIIIVVVIVIIVIIIIXXXIXIV XIII XVXII a) b) 110839480440510910 c) -III' EYA1 gene structure Bronchio-Oto-Renal Syndrome
 b) c) -III EYA1 gene structure Bronchio-Oto-Renal Syndrome")
57
... CCT GAG GAG...... CCT GTG GAG...... Pro Glu Glu...... Pro Val Glu... normalmuté anomalie cytogénétique Cartographie génétique -localisation chromosomique -localisation fine Cartographie physique et Isolement de clones spécifiques Isolement de gène (s) Recherche de mutations Etude fonctionnelle Recherche de familles -détermination du phénotype -collecte d'ADN
 Recherche de mutations Etude fonctionnelle Recherche de familles -détermination du phénotype -collecte d ADN.")
59
.... From in vivo to in vitro to in silico

62
Problème de pénétrance

63
Famille EBDD-I IV V III I II 2 7 4 4 3 33m733m7 3 M 10 33m733m7 3 M 10 33m633m6 3 M 10 33m633m6 33M833M8 33m733m7 33M833M8 Sous le mode dominant 33M733M7 33M833M8 33M833M8 33M733M7 2 M 11 33M833M8 3 M 10 33M833M8 33M733M7 3 M 10 2 M 11 44M544M5 52M952M9 33M33M 33m733m7

64
Maladie à pénétrance incomplète et expressivité variable Individu 1 G1 Malade Individu 2 G1 Sain ?? Environnement?

65
G1/ 1 G1/ 2 Epissage alternatif Non Sens mRNA decay Mécanisme de régulation post-transcriptionnelle G2 G3 Gènes modificateurs

66
Environemental factorsGenetic factors Complex /common disorders: multifactoriel

67
Hemophilia Familial Colon or Breast Cancer Alzheimers Asthma Skin Cancer Motor Vehicle Accident Cardiovascular Disease Complex Diseases : Genes & Environment Environmental Effect Genetic Component Schizophrenia Cystic Fibrosis Stroke Type 2 Diabetes Lung Cancer Bipolar Disorder

68
2Improve the understanding of disease etiology and mechanism 2Early disease risk assessment 2Discover new drug targets 2Disease prevention 2population or ethnic group variability The potential benefits of identifying genes/variations involved in disease Predisposition Targeted screening Prevention Diagnosis Therapy Predictive medicine

69
Pharmacogenomics: The Promise of Personalized Medicine

71
CREDIT: JOE SUTLIFF. SCIENCE, 2001 O GOD!

74
Acknowledgement: the following presentation has been prepared on the basis of Internet resources. International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860–921 (2001). Venter, J. C. et al. The sequence of the human genome. Science 291, 1304–1351 (2001). International Human Genome Sequencing Consortium. Finishing the euchromatic sequence of the human genome., Nature 431: 931-945 (2004).
. Venter, J. C. et al. The sequence of the human genome. Science 291, 1304–1351 (2001). International Human Genome Sequencing Consortium. Finishing the euchromatic sequence of the human genome., Nature 431: (2004)..")
75
Thank you

Similar presentations
















 409, 860-921>")










>")



>")
