Download presentation
Presentation is loading. Please wait.

1
Herv´ eJ´ egouMatthijsDouzeCordeliaSchmid INRIA INRIA INRIA herve.jegou@inria.frherve.jegou@inria.fr matthijs.douze@inria.fr cordelia.schmid@inria.frmatthijs.douze@inria.frcordelia.schmid@inria.fr LEAR (Learning and Recognition in Vision)
")
2
Introduction Background Structure & Approach Experiments Conclusion

3
One of the main limitations of image search based on bag-of-feature is the memory usage per image Provide a method which Reduce the memory usage and faster than standard bag-of -feature

5
1. Extract local image descriptors (features) (Hessian-Affine detector [8] & SIFT descriptor [6]) 2. Learn “visual vocabulary” (Clustering of the descriptor) 3.Quantize features using visual vocabulary (K-means quantizer) 4. Represent images by frequencies of “visual words” histogram of visual word occurrence is weighted using the tf-idf. normalized with the L2 norm Producing a frequency vector f i of length k
 (Hessian-Affine detector [8] & SIFT descriptor [6]) 2. Learn visual vocabulary (Clustering of the descriptor) 3.Quantize features using visual vocabulary (K-means quantizer) 4. Represent images by frequencies of visual words histogram of visual word occurrence is weighted using the tf-idf. normalized with the L2 norm Producing a frequency vector f i of length k.")
6
tf = 0.030 ( 3/100 ) 100 vocabularies in a document, ‘a’ 3 times idf = 13.287 ( log (10,000,000/1,000) ) 1,000 documents have ‘a’, total number of documents 10,000,000 if-idf = 0.398 ( 0.03 * 13.287 ) Visual word (feature)image
 100 vocabularies in a document, ‘a’ 3 times idf = ( log (10,000,000/1,000) ) 1,000 documents have ‘a’, total number of documents 10,000,000 if-idf = ( 0.03 * ) Visual word (feature)image")
7
INRIA Holidays dataset [4] University of Kentucky recognition benchmark [9] Flickr1M & Flickr1M*
![INRIA Holidays dataset [4] University of Kentucky recognition benchmark [9] Flickr1M & Flickr1M*](http://images.slideplayer.com/14/4463909/slides/slide_7.jpg "INRIA Holidays dataset [4] University of Kentucky recognition benchmark [9] Flickr1M & Flickr1M*")
8
Discard the information about the exact number of occurrences of a given visual word in the image Binary BOF components only indicates the presence or absence of a particular visual word in the image A sequential coding using 1 bit per component. The memory usage is, then, ┌ k/8 ┐ byte per image. The memory usage per image would be typically 10kB per image [12] J.SivicandA.Zisserman. Video Google: A text retrieval Approach to object matching in videos.In ICCV,pages1470–1477,2003.

10
[16]J.ZobelandA.Moffat. Inverted files for text search engines. ACM Computing Surveys,38(2):6,2006. Compared with a standard inverted file, about 4 times more image scan be indexed using the same amount of memory. The amount of memory to be read is proportionally reduced at query time. This may compensate the decoding cost of the decompression algorithm.
![[16]J.ZobelandA.Moffat. Inverted files for text search engines.](http://images.slideplayer.com/14/4463909/slides/slide_10.jpg "ACM Computing Surveys,38(2):6,2006. Compared with a standard inverted file, about 4 times more image scan be indexed using the same amount of memory. The amount of memory to be read is proportionally reduced at query time. This may compensate the decoding cost of the decompression algorithm..")
12
1) Producing 2) Indexing 3) Fusing Performed a query image
 Producing 2) Indexing 3) Fusing Performed a query image")
13
Sparse projection matrices A = {A1,...,Am} of sizes d × k d = dimension of the output descriptor k = dimension of the initial BOF For each projection vector (a matrix row ), the number of non-zero components is nz = k/d. Typically set nz = 8 for k=1000,resulting d = 125

14
The other aggregators are defined by shuffling the input BOF vector components using random permutation. For k =12, d=3 the random permutation (11,2,12,8,9,4,10,1,7,5,6,3 Image i, m miniBOFs ωi,j, 1 ≤ j ≤ m fi = BOF frequency vector

15
Quantization k’ = number of codebook entries of the indexing structure The set of k-means codebooks qj(.), 1<= j <= m, is learned off-line using a large number of miniBOF vectors, here extracted from the Flickr1M* dataset. The miniBOFs is not related to the one associated with the initial SIFT descriptors, hence we may choose k ≠ k’. Typically set k’ = 20000

16
Binary signature generation b i,j Length of d, refine the localization of the miniBOF within the cell Using the method of [4] The miniBOF is projected using a random rotation matrix R, producing d components Each bit of the vector bi,j is obtained by comparing the value projected by R to the median value of the elements having the same quantized index. The median values for all quantizing cells and all projection directions are learned off-line on our independent dataset.
![Binary signature generation b i,j Length of d, refine the localization of the miniBOF within the cell Using the method of [4] The miniBOF is projected using a random rotation matrix R, producing d components Each bit of the vector bi,j is obtained by comparing the value projected by R to the median value of the elements having the same quantized index.](http://images.slideplayer.com/14/4463909/slides/slide_16.jpg "The median values for all quantizing cells and all projection directions are learned off-line on our independent dataset..")
18
j th miniBOF associated with image i is represented by the tuple 4 bytes to store the image identifier i ┌ d/8 ┐ byte to store the binary vector b i,j Total memory usage pre image is C i = m*( 4 + ┌ d/8 ┐ )
")
19
Multi-probe strategy [7] Retrieving not only the inverted list associated with the quantized index c i,j, but the set of inverted lists associated with the closest t centroids of the quantizer codebook It increases the number of image hits because t times more inverted lists are visited
![Multi-probe strategy [7] Retrieving not only the inverted list associated with the quantized index c i,j, but the set of inverted lists associated with the closest t centroids of the quantizer codebook It increases the number of image hits because t times more inverted lists are visited](http://images.slideplayer.com/14/4463909/slides/slide_19.jpg "Multi-probe strategy [7] Retrieving not only the inverted list associated with the quantized index c i,j, but the set of inverted lists associated with the closest t centroids of the quantizer codebook It increases the number of image hits because t times more inverted lists are visited")
20
b i,j The signature associated with the query image q b q,j The signature of the database image I b q = [ b q,1,...,b q,m ] b i = [ b i,1,...,b i,m ] h(x,y) represents the Hamming distance
![b i,j The signature associated with the query image q b q,j The signature of the database image I b q = [ b q,1,...,b q,m ] b i = [ b i,1,...,b i,m ] h(x,y) represents the Hamming distance](http://images.slideplayer.com/14/4463909/slides/slide_20.jpg "b i,j The signature associated with the query image q b q,j The signature of the database image I b q = [ b q,1,...,b q,m ] b i = [ b i,1,...,b i,m ] h(x,y) represents the Hamming distance")
21
equal to 0 for images having no observed binary signature equal to d * m/2 if the database image I is the query image itself The query speed improved by a threshold on the Hamming distance, we use τ = d/2

23
Used the following parameters in all the miniBOF experiments On University of Kentucky object recognition benchmark On Holidays + Flickr1M

24
On Holiday + Flickr1M

26
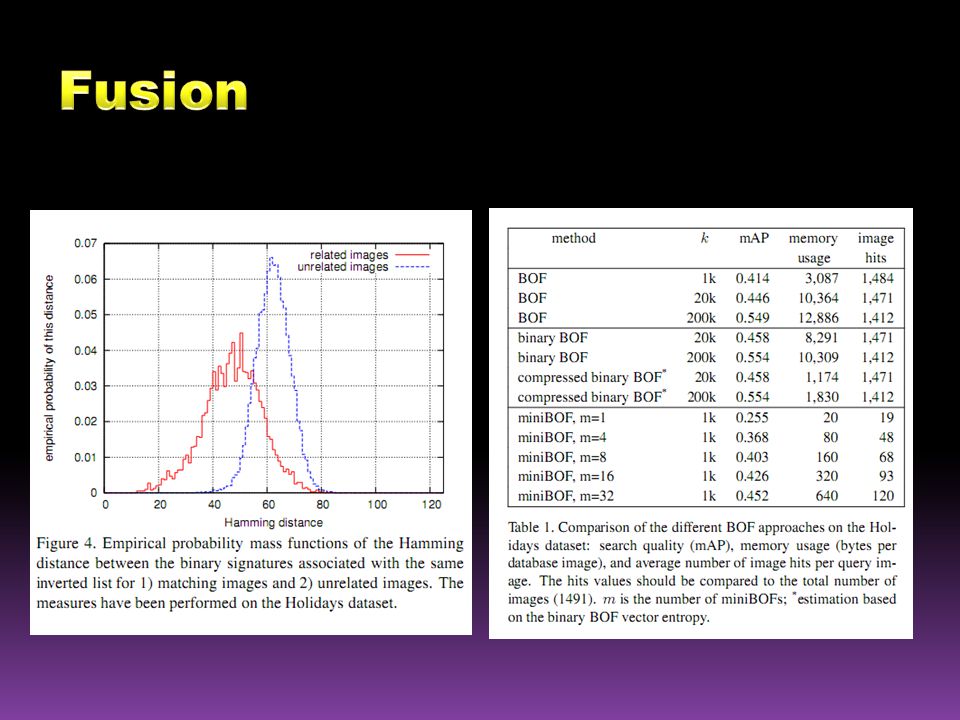
This paper we have introduced a way of packing BOFs : miniBOFs An efficient indexing structure based on Hamming Embedding allows for rapid access and an expected distance criterion for the fusion of the scores. It Reduces Memory usage the quantity of memory scanned (hits) query time
 query time.")
Similar presentations







 Masatoshi Yoshikawa.>")
















