Download presentation
Presentation is loading. Please wait.

1
Applications of one-class classification
-- searching for comparable applications for negative selection algorithms

2
background Purpose: looking for real world applications that demonstrates the usage of V-detector (a negative selection algorithm) One-class classification problem: Different from conventional classification: only information of one of the classes (target class) is available Original application: anomaly (outliner) detection More about the application than whatever classification methods involved
 is available. Original application: anomaly (outliner) detection. More about the application than whatever classification methods involved.")
3
One-class Classification
Basic concept of classification: A classifier is a function which outputs a class label from each input object. It cannot be constructed from known rules. In pattern recognition or machine learning: inferring a classifier (a function) from a set of training examples. Usually, the type of function is chosen beforehand and parameters are to be determined. Line classifier, mixture of Gaussians, neural networks, support vector classifiers
 from a set of training examples. Usually, the type of function is chosen beforehand and parameters are to be determined. Line classifier, mixture of Gaussians, neural networks, support vector classifiers.")
4
One-class Classification
Basic concept of classification: Assumptions: continuity, enough information (amount of samples, limited noise), etc. Multi-class classification can be decomposed into two-class classifications
, etc. Multi-class classification can be decomposed into two-class classifications.")
5
One-class classification
Same problems as conventional classification Definition of errors Atypical training data Measuring the complexity of a solution The curse of dimensionality The generalization of the method

6
A conventional and a one-class classifier applied to an example dataset containing apples and pears, represented by 2 features per object. The solid line is the conventional classifier which distinguishes between the apples and pears, while the dashed line describes the dataset. This description can identify the outlier apple in the lower right corner, while the classifier will just classify it as an pear.

7
One-class classification
Additional problems Most conventional classifier’s assumption that more or less balanced data. Hard to decide on the basis of on class how tightly the boundary should fit in each direction around the data. Hard to find which features should be used to find the best separation. Impossible to estimate false positives. More prominent curse of dimension. Extra constraints: closed boundary etc.

8
Various techniques Generate outliner detection
Some methods requires near-target objects; Density method: directly estimating the density of target objects some works requires density estimate in the complete feature space Typical sample is assumed Reconstruction methods: based on prior knowledge Boundary methods Well defined distance

9
Application 1: texture classification
Problem: classification of texture images polished granite (or ceramic) tiles that are widely used as construction elements The polished granite tiles are usually inspected by a human expert using a chosen master tile as the reference. Such inspection is subjective and qualitative One-class classifier is suitable: Outliners cannot be used to train any methods Recent development quasi-statistical representation of binary images used as a feature space for texture image classification
 tiles that are widely used as construction elements. The polished granite tiles are usually inspected by a human expert using a chosen master tile as the reference. Such inspection is subjective and qualitative. One-class classifier is suitable: Outliners cannot be used to train any methods. Recent development. quasi-statistical representation of binary images used as a feature space for texture image classification.")
10
Based on CCR feature space (coordinated cluster representation)
Outline of the method: Given a master texture image of a class, estimate statistics of CCR histogram Use parameters of the statistics to define a closed decision boundary.

11
Master images

12
CCR feature space A binary image intensity: Sa={sa{l,m}}, where l=1, 2, …L and m=1, 2, …, M A rectangular window W = I X J Scan all over the image with one pixel steps using that window The number of all possible state of the window is 2w Coordinated clusters representation consists of a histogram Ha(I,J)(b) a is the index of the image (I,J) indicated the size of the window b = 1, 2, …, 2w
(b) a is the index of the image. (I,J) indicated the size of the window. b = 1, 2, …, 2w.")
13
When a histogram is normalized, it is considered as a proability distribution function of occurrence
Fa(I,J)(b) = 1/A Ha(I,J)(b) Where A = (L-I+1)X(M-J+1) Histogram H contains all the information about n-point correlation moments of the image if and only if the separation vectors between n pixels fit between the scanning window In general, when the order of statistics is higher, more structural information is available There is a structural correspondence between a gray level image and its thresholded counterpart Provided that the binary image keeps enough structural information about a primary gray level image to be classified, the CCR of a binary image is highly suitable for recognition and classification of gray level texture image
(b) = 1/A Ha(I,J)(b) Where A = (L-I+1)X(M-J+1) Histogram H contains all the information about n-point correlation moments of the image if and only if the separation vectors between n pixels fit between the scanning window. In general, when the order of statistics is higher, more structural information is available. There is a structural correspondence between a gray level image and its thresholded counterpart. Provided that the binary image keeps enough structural information about a primary gray level image to be classified, the CCR of a binary image is highly suitable for recognition and classification of gray level texture image.")
14
Framework of classification
Training phase a set of gray level image from each texture class Each threshold Calculate CCR distribution function Recognition phase Input test image Thresholded CCR distribution Compare with prototypes and assign to the class of best match One-class classification Define the limits of feature variations Establish the criterion

15
Thresholding (binarization)
Because CCR is defined for binary image Fuzzy C-Means clustering method

16
Training phase assuming Q images of a class are available, a random set of P subimages is sampled If only one image is available, Q independent random sets are sampled Five measurements are calculated from distribution function Fa F: mass center of subimages (not a value, still a function or histogram) D: mean of distance (“distance” refers to the mean distance within a set) s: mean of standard deviation (“standard deviation” refers to the standard deviation of a set) D: mean of q-th sample center to the center of all samples s2: variance of each sets with regard to center of samples
 D: mean of distance ( distance refers to the mean distance within a set) s: mean of standard deviation ( standard deviation refers to the standard deviation of a set) D: mean of q-th sample center to the center of all samples. s2: variance of each sets with regard to center of samples.")
17
C is the emprical adjustment parameter
Criterion d(Ftest, F) < D+Cs D-2s<Dtest<D+2s C is the emprical adjustment parameter Ftest and Dtest are the mean of K ransom subimage of the texture image to be classified L1 distance is used as the measures of distinction d(Fa,Fb) = Sb|Fa(b)-Fb(b)|
 < D+Cs. D-2s<Dtest<D+2s. C is the emprical adjustment parameter. Ftest and Dtest are the mean of K ransom subimage of the texture image to be classified. L1 distance is used as the measures of distinction. d(Fa,Fb) = Sb|Fa(b)-Fb(b)|")
18
Results C should be in the range of 1, 2, …, 20
Based on observation that s is approximately ten times less than D 8 master images (training data) plus 16 testing images are used (128X128). For C=1 or 2, only the master images are recognized More images are recognized for larger C For C<19, no mis-classification Proper C depends on the size of subimage (32, 24, 64 are discussed)
 plus 16 testing images are used (128X128). For C=1 or 2, only the master images are recognized. More images are recognized for larger C. For C<19, no mis-classification. Proper C depends on the size of subimage (32, 24, 64 are discussed)")
19
Application 2: authorship
Problem: authorship verification Different from standard text categorization problem No realistic to train with negative samples Difference from other one-class classification Negative samples are not lacked – hard to choose to represent the entire class The object texts are long We can chunk to multiple samples – a set instead of single instance

20
New idea: Depth of difference between two sets
Test the rate of degradation of accuracy as the best features are iteratively dropped

21
Standard method Choose a feature set: frequencies of function words, syntactic structures, parts-of-speech n-grams, complexity and richness measure, syntactic and orthographic idiosyncrasies Note: very different from text categorization by topic Having constructed feature vectors, use learning algorithm to construct distinguishing model Similar to categorization by topic Liner separators are believed to work well Assessment: k-fold cross-validation or bootstrapping

22
One-class scenario Naïve approach New approach: unmasking
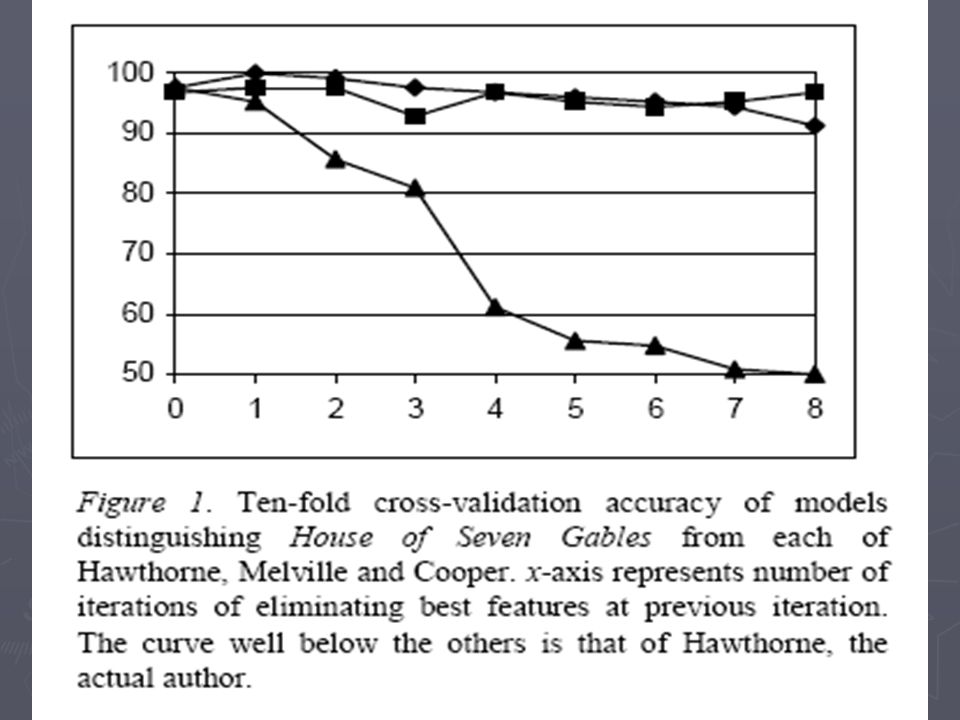
Chunk two works to generate two sufficient large sets Test if we can distinguish using cross-validation with high accuracy Failed in experiment (different works are just different enough to tell) New approach: unmasking In the above approach, a small number of features are doing all the work. They are likely to be from thematic differences, difference in genre or purpose, chronological shift of style, deliberate attempt to mask identity Unmasking: removing features that are most useful to distinguish Hypothesis: if they are by the same author, difference will be refelected in only a relative small number of features Sudden degradation shows the same author
 New approach: unmasking. In the above approach, a small number of features are doing all the work. They are likely to be from thematic differences, difference in genre or purpose, chronological shift of style, deliberate attempt to mask identity. Unmasking: removing features that are most useful to distinguish. Hypothesis: if they are by the same author, difference will be refelected in only a relative small number of features. Sudden degradation shows the same author.")
24
Results: Corpus: 21 19th century English iterature
Baseline: one-class SVM Extension: using negative samples to eliminate false positive Solution to a literary mystery: the case of the bashful rabbi

25
bibliography D. M. J. Tax, “One-class classification”, PhD thesis, 2001 D. M. J. Tax, “Data description toolbox: A Matlab toolbox for data description, outlier and novelty detection”. 2005 M. Koppel and J. Schler, Authorship verification as a one-class classification problem, in Proceedings of 21st International Conference on Machine Learning, 2004. R.E.Sanchez-Yanez et al, One-class texture classifier in the CCRfeature space, Pattern Recognition Letter, 24, 2003. R.E.Sanchez-Yanez et al, A framework for texture classification using the coordinated clusters representation, Pattern Recognition Letter, 24, 2003.

Similar presentations


 Johannes Gehrke>")

:747-757, Aug 2000.>")














