Download presentation
Presentation is loading. Please wait.

1
Tim Hulsen 2008-11-20 Literature discussion Defrosting the Digital Library: Bibliographic Tools for the Next Generation Web PLoS Computational Biology 2008 Oct;4(10):e1000204 Duncan Hull, Steve R. Pettifer, Douglas B. Kell

2
22008-11-20Tim Hulsen Introduction Many scientists now organize their knowledge of the literature using some kind of computerized reference management system (BibTeX, EndNote, Reference Manager, RefWorks, etc.), and store their own digital libraries of full publications as PDF files Getting hold of both the data (the actual publication) and the metadata for any given publication can be problematic Each library and publisher has different ways of identifying and describing their metadata With papers in the life sciences alone (at Medline) being published at the rate of approximately two per minute, only computerized analyses can hope to be reasonably comprehensive. This talk: –Digital libraries –Tools to manage libraries

3
32008-11-20Tim Hulsen Digital libraries Digital library = “a database of scientific and technical articles, conference publications, and books that can be searched and browsed using a Web browser” No single database covers all information (in part because of the cost, given that there are some 25,000 peer-reviewed journals publishing some 2.5 million articles per year) Read-only / write-only Abstracts / full-text Web 2.0: digital libraries should be read-write
 Read-only / write-only Abstracts / full-text Web 2.0: digital libraries should be read-write")
4
42008-11-20Tim Hulsen Digital libraries The ACM Digital Library IEEE Xplore The Digital Bibliography and Library Project (DBLP) PubMed (Central) ISI Web of Knowledge Scopus Siteseer Google Scholar arXiv.org … and many more
 PubMed (Central) ISI Web of Knowledge Scopus Siteseer Google Scholar arXiv.org … and many more")
5
52008-11-20Tim Hulsen The ACM Digital Library http://portal.acm.org Association for Computing Machinery (ACM) makes their digital library available on the Web contains more than 54,000 articles from 30 journals and 900 conference proceedings dating back to 1947, focusing primarily on computer science like many other large publishers, the ACM uses Digital Object Identifiers (DOI) to identify publications metadata for publications in the ACM digital library are available from URLs in the style above as EndNote and BibTeX formats; the latter is used in the LaTeX document preparation system
 makes their digital library available on the Web contains more than 54,000 articles from 30 journals and 900 conference proceedings dating back to 1947, focusing primarily on computer science like many other large publishers, the ACM uses Digital Object Identifiers (DOI) to identify publications metadata for publications in the ACM digital library are available from URLs in the style above as EndNote and BibTeX formats; the latter is used in the LaTeX document preparation system")
6
62008-11-20Tim Hulsen PubMed (Central) http://www.pubmed.gov service provided by the National Center for Biotechnology Information (NCBI) includes more than 17 million citations from more than 19,600 life science journals primary mechanism for identifying publications in PubMed is the PubMed identifier (PMID) publication metadata for articles in PubMed are available in a wide variety of formats including MEDLINE flat-file format and XML, conforming to the NCBI Document Type Definition, a template for creating XML documents can be personalized using the MyNCBI application (described later) PubMed Central, a subset of PubMed, provides free full-text of articles Metadata are available from URIs in PubMed Central as either XML, Dublin Core, and/or RDF by using the Open Archives Initiative (OAI) Protocol for Metadata Harvesting (PMH) PubMed papers are tagged or indexed according to their MeSH (Medical Subject Heading) terms, curated manually
 service provided by the National Center for Biotechnology Information (NCBI) includes more than 17 million citations from more than 19,600 life science journals primary mechanism for identifying publications in PubMed is the PubMed identifier (PMID) publication metadata for articles in PubMed are available in a wide variety of formats including MEDLINE flat-file format and XML, conforming to the NCBI Document Type Definition, a template for creating XML documents can be personalized using the MyNCBI application (described later) PubMed Central, a subset of PubMed, provides free full-text of articles Metadata are available from URIs in PubMed Central as either XML, Dublin Core, and/or RDF by using the Open Archives Initiative (OAI) Protocol for Metadata Harvesting (PMH) PubMed papers are tagged or indexed according to their MeSH (Medical Subject Heading) terms, curated manually")
7
72008-11-20Tim Hulsen ISI Web of Knowledge http://www.isiwebofknowledge.com Institute for Scientific Information’s Web of Knowledge, a service provided by The Thomson Reuters Corporation, covering a broad range of scientific disciplines size of the library is somewhere in the region of 15,000,000 does not currently provide short, simple links to its content provides various citation tracking and analytical features such as Journal Citation Reports, which measures the impact factor of individual journals metadata for publications are provided in BibTeX, Procite, Refman, and EndNote provides citation tracking features, particularly calculating the H-index for a given author, as well as "citation alerts" that can automatically send e-mail when a given paper is newly cited

8
82008-11-20Tim Hulsen Scopus http://www.scopus.com service provided by Reed Elsevier and seems to be the Digital Library with individually the most comprehensive coverage, claiming (June 2008) 33,000,000 records (leaving aside Web pages) allows links to its content using OpenURL, which provides a standard syntax for creating URLs links out to content using OpenURL and provides citation tracking metadata can be exported in RefWorks, RIS format (EndNote, ProCite, RefMan), and plain text, etc. possible to get RSS feed for citations of an article

9
92008-11-20Tim Hulsen Citeseer http://citeseerx.ist.psu.edu Citeseer is a service currently funded by Microsoft Research, NASA, and the National Science Foundation (NSF), covering a broad range of scientific disciplines and more than 760,000 documents Publication metadata are available from Citeseer in BibTeX format, and citation tracking is performed annually in the Most Cited Authors feature
, covering a broad range of scientific disciplines and more than 760,000 documents Publication metadata are available from Citeseer in BibTeX format, and citation tracking is performed annually in the Most Cited Authors feature")
10
102008-11-20Tim Hulsen Google Scholar http://scholar.google.com Indexes traditional scientific literature, as well as preprints and “grey” self-archived publications from selected institutional web sites Size and coverage not published, and exact method for finding and ranking citations has not yet been made completely public Links out to external content using a number of methods incl. OpenURL In contrast to some other digital libraries, it provides simple URLs that link to different resources No specific facilities for creating a personal collection of documents or sharing these collections with other users, other than using simple links Publication metadata can be obtained where OpenURL links are found in the search results; otherwise, metadata can be obtained by clicking through the links to their original sources

11
112008-11-20Tim Hulsen arXiv.org http://www.arxiv.org provides open access to more than 44,000 e-prints in physics, mathematics, computer science, quantitative biology, and statistics presently little used by biologists different publishing model: publications are peer-reviewed after publication in the arXiv, rather than before publication owned, operated, and funded by Cornell University and is also partially funded by the National Science Foundation metadata for publications in arXiv are available in BibTeX format, with various citation- tracking features provided by the experimental citebase project. This alternative approach to manual citation counts works by calculating the number of times an individual paper has been downloaded

12
122008-11-20Tim Hulsen Digital libraries

13
132008-11-20Tim Hulsen Digital libraries The approximate relative coverage and size of the digital libraries. Of all the libraries described, Google Scholar probably has the widest coverage. However, it is currently not clear exactly how much information Google indexes, what the criteria are for inclusion in the index, and whether it subsumes other digital libraries in the way shown in the figure. Note: the size of sets (circles) in this diagram is NOT proportional to their size, and DBLP, Scopus, and arXiv are shown as a single set for clarity rather than correctness.
 in this diagram is NOT proportional to their size, and DBLP, Scopus, and arXiv are shown as a single set for clarity rather than correctness..")
14
142008-11-20Tim Hulsen Tools to manage libraries There is a growing number of web applications that can manage digital libraries Two important aspects of managing libraries: –Personalization: my collection of interesting papers, or my collection of (co-)authorships –Socialization: share my personal collection, see who else is reading the same publications, use keywords to tag the manuscripts, give comments on a certain publication
authorships –Socialization: share my personal collection, see who else is reading the same publications, use keywords to tag the manuscripts, give comments on a certain publication")
15
152008-11-20Tim Hulsen Tools to manage libraries Zotero Mendeley MyNCBI Mekentosj Papers CiteULike.org Connotea.org HubMed.org … and many more

16
162008-11-20Tim Hulsen Zotero http://www.zotero.org Extension for the Firefox browser that enables users to manage references directly from the Web browser Can recognise and extract data and metadata from a range of different digital libraries Users can bookmark publications, and then add their own personal tags and notes. Currently, Zotero does not allow users to share their tags. Zotero bookmarks cannot be identified using URIs, so it is not possible to link in from external sources to these personal collections.

17
172008-11-20Tim Hulsen Mendeley http://www.mendeley.com application similar to Zotero that helps to manage and share research papers as well as having a web-based browser version it is possible to store bibliographies using a more powerful desktop-based client that automatically extracts metadata from PDF files, but it can only do this where metadata is available in an amenable format

18
182008-11-20Tim Hulsen MyNCBI http://www.ncbi.nlm.nih.gov/sites/myncbi allows users to save PubMed searches and to customize search results features an option to update and e-mail search results automatically from saved searches includes extra features for highlighting search terms, filtering search results, and setting LinkOut, document delivery, and external tool preferences like Zotero, MyNCBI currently allows personalization only, with no socialization features limited to publications in PubMed like Zotero, it is currently not possible to link to personal collections created in MyNCBI

19
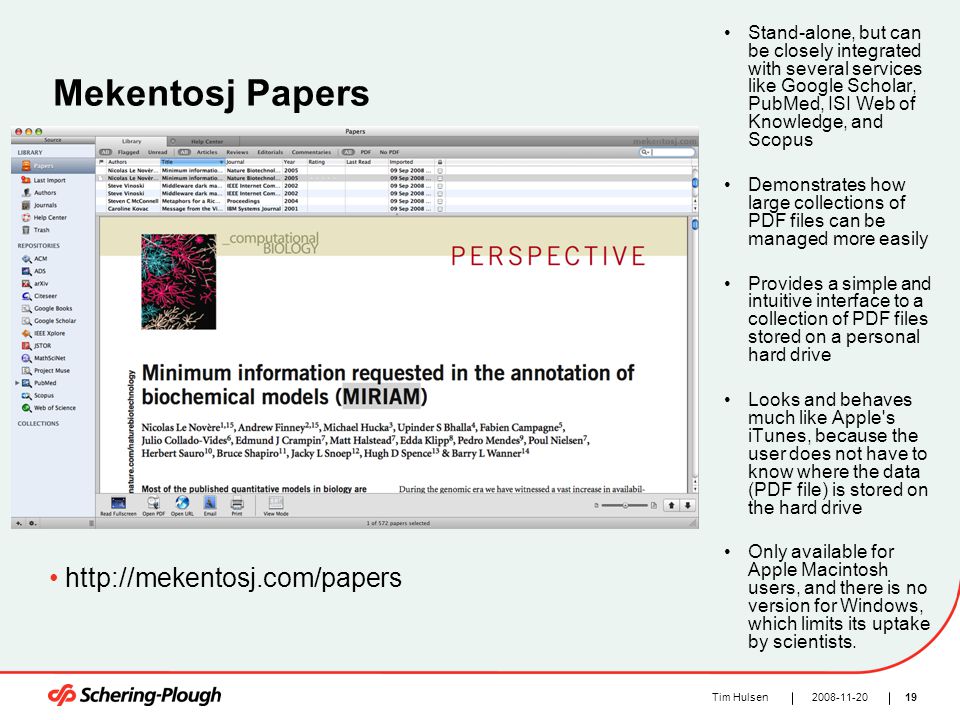
192008-11-20Tim Hulsen Mekentosj Papers Stand-alone, but can be closely integrated with several services like Google Scholar, PubMed, ISI Web of Knowledge, and Scopus Demonstrates how large collections of PDF files can be managed more easily Provides a simple and intuitive interface to a collection of PDF files stored on a personal hard drive Looks and behaves much like Apple's iTunes, because the user does not have to know where the data (PDF file) is stored on the hard drive Only available for Apple Macintosh users, and there is no version for Windows, which limits its uptake by scientists. http://mekentosj.com/papers
20
202008-11-20Tim Hulsen CiteULike.org http://www.citeulike.org free online service to organize academic publications first Web-based social bookmarking tool designed specifically for the needs of scientists allows users to bookmark or ‘‘tag’’ URLs with personal metadata using a web browser; these bookmarks can then be shared using simple links ~ 2 million manuscripts bookmarked software is not open source, part of the dataset it collects is currently in the public domain normalizes bookmarks before adding them to its database, which means it calculates whether each URL bookmarked identifies an identical publication added by another user, with an equivalent URL. This is important for social tagging applications, because part of their value is the ability to see how many people (and who) have bookmarked a given publication also captures another important bibliometric: how many users have potentially read a publication, not just cited it provides metadata for all publications in RIS (EndNote) and BibTeX
 have bookmarked a given publication also captures another important bibliometric: how many users have potentially read a publication, not just cited it provides metadata for all publications in RIS (EndNote) and BibTeX.")
21
212008-11-20Tim Hulsen Connotea.org http://www.connotea.org run by Nature Publishing Group provides a similar set of features to CiteULike with some differences uses MD5 hashes to store URLs that users bookmark, and normalizes them after adding them to its database, rather than before. This post- normalization means Connotea does not always currently recognize when different URLs identify the same publication, a bug known as "buggotea", which also affects CiteULike to a lesser extent metadata are available from Connotea in a wider variety of formats than from CiteULike, including RIS, BibTeX, MODS, Word 2007 bibliography, and RDF source code for Connotea is available, and there is an API that allows software engineers to build extra functionality around Connotea

22
222008-11-20Tim Hulsen HubMed.org http://www.hubmed.org a "rewired" version of PubMed, and provides an alternative interface with extra features, such as standard metadata and Web feeds, which can be subscribed to using a feed reader allows users to subscribe to a particular journal and receive updates when new content (e.g., a new issue) becomes available like CiteULike, HubMed also solves the "Get Metadata" problem because metadata are available from each HubMed URL in a wide variety of formats not offered by NCBI provides metadata in RIS (for EndNote), BibTeX, RDF, and MODS style XML users can also log in to HubMed to use various personalized features such as tagging
 becomes available like CiteULike, HubMed also solves the Get Metadata problem because metadata are available from each HubMed URL in a wide variety of formats not offered by NCBI provides metadata in RIS (for EndNote), BibTeX, RDF, and MODS style XML users can also log in to HubMed to use various personalized features such as tagging")
23
232008-11-20Tim Hulsen Advantages CiteULike and Connotea Advantages over storing PDFs on a PC: –Searching: easier and more sophisticated –Managing: Metadata (authors, title, etc.) are retrieved automatically –Tagging: for personalisation and socialisation –Server-based: bibliography will still be available when moving to a different PC –Serendipity: discovery through co-occurrence, browse through articles with same tags
 are retrieved automatically –Tagging: for personalisation and socialisation –Server-based: bibliography will still be available when moving to a different PC –Serendipity: discovery through co-occurrence, browse through articles with same tags")
24
242008-11-20Tim Hulsen Conclusion (1) Numerous libraries and applications available, each with their own advantages and disadvantages The Future: –Personalization and socialization of information will increasingly blur the distinction between databases and journals –Digital information sources are often too “small” or too “big” for journals –NAR database issue not enough to fill this gap –Biology moves from a hypothesis-driven science to a data-driven science, so databases are more and more the scientific output, instead of papers –Future tools integrate everything: papers, databases, reviews, comments, bookmarks, blogs, Facebook entries, etc.
 Numerous libraries and applications available, each with their own advantages and disadvantages The Future: –Personalization and socialization of information will increasingly blur the distinction between databases and journals –Digital information sources are often too small or too big for journals –NAR database issue not enough to fill this gap –Biology moves from a hypothesis-driven science to a data-driven science, so databases are more and more the scientific output, instead of papers –Future tools integrate everything: papers, databases, reviews, comments, bookmarks, blogs, Facebook entries, etc.")
25
252008-11-20Tim Hulsen Conclusion (2) Obstacles to ‘warmer’ (more integrated, personal, social) digital libraries: –Identity problem (some authors have the same name, one author can have different ‘names’) –Scientists need to trust publishers and vice-versa –What do scientists want to share? Only peer-reviewed data? Scoop danger? Recommendations: –Simple, persistent URLs –Exposing metadata (EndNote, BibTeX, XML, RDF) –Identifying publications (use DOIs) –Identifying people (unique author identification)
 –Identifying publications (use DOIs) –Identifying people (unique author identification).")
Similar presentations



>")

 References.>")













