Download presentation
Presentation is loading. Please wait.

1
Science and the Web Daniel Swan Bioinformatics Support Unit (http://twitter.com/nclbsu) d.c.swan@ncl.ac.uk (http://twitter.com/d_swan) (yes, even Twitter is a useful scientific tool!)
")
2
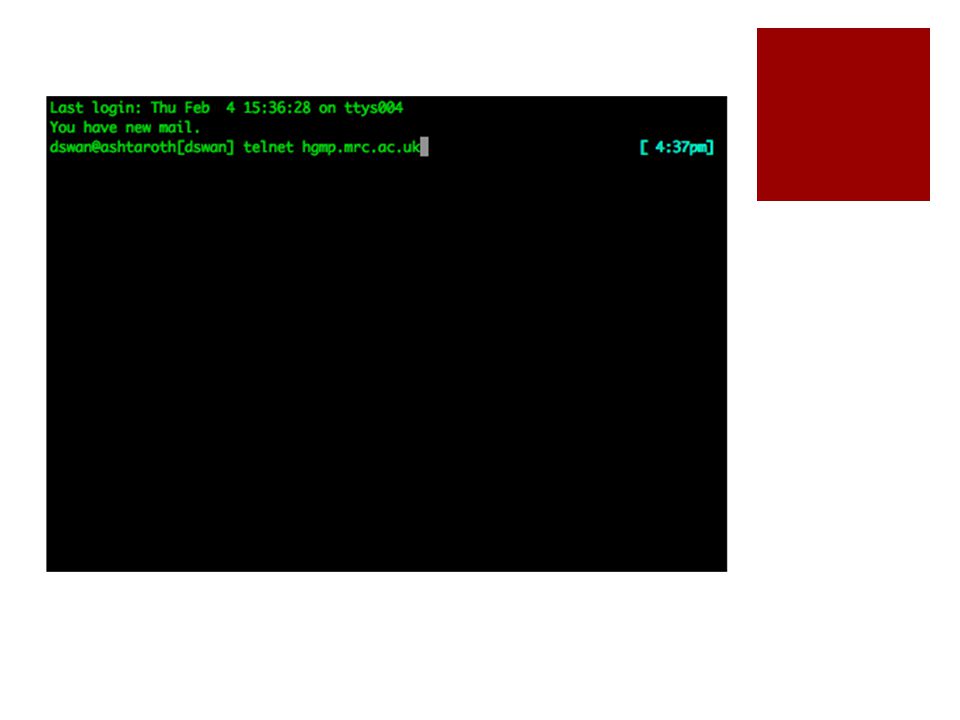
In the bad old days There was the internet But there was no web No Facebook No iPlayer No Spotify No Google But we still managed to use it for awesome science

5
Yes, this really was the view of the worlds sequence databases that we used to have!

7
But we had social resources Email newsgroups MUDs (kind of like a text only Second Life) Usenet Newsgroups A kind of forerunner of today's message boards Often un-moderated Full of spam All the science stuff of interest was under bio.* or sci.*
 Usenet Newsgroups A kind of forerunner of today s message boards Often un-moderated Full of spam All the science stuff of interest was under bio.* or sci.*")
8
How the web was won The internet has been designed by scientists for scientists pretty much since inception The internet ‘as we know it today’ arrived in the 1990s OK that’s just not true, but it’s what most people associate with the internet Aka ‘The Web’

9
And this WAS about science (Sir) Tim Berners-Lee is a scientist The World-Wide Web (W3) was developed to be a pool of human knowledge, which would allow collaborators in remote sites to share their ideas and all aspects of a common project Data, and pages could be linked together for the first time with images, sounds, text As the data grew, it needed to be searched Search engines collated the data
 Tim Berners-Lee is a scientist The World-Wide Web (W3) was developed to be a pool of human knowledge, which would allow collaborators in remote sites to share their ideas and all aspects of a common project Data, and pages could be linked together for the first time with images, sounds, text As the data grew, it needed to be searched Search engines collated the data")
10
And so Web 1.0 begun We got used to: Online shopping Having a homepage Getting our news online Guestbooks on websites Animated GIFs Wonderful colourschemes:

11
So wtf is Web 2.0? 30% marketing nonsense to attract investors 20% buzzwords designed to annoy old people ‘mashup’ etc. 50% useful Specifically refers to ‘user generated content’ High availability and access to data Networks of people and network effects Openness Tapping into the ‘wisdom of the crowds’

12
Concepts One of the social concepts most people are familiar with now is tagging: And the ubiquitous upvote:

13
How can we take this out of Facebook and into science?

14
We have a data overload How can you define what is important? And how can you deal with it subsequently?

15
Tagging is very useful Search and retrieval tool Can be applied to just about anything Browser bookmarks Uploaded YouTube videos Academic Papers Uploaded Powerpoint presentations And most importantly they can be SHARED with other users We call these tags ‘folksonomies’ “a system of classification derived from the practice and method of collaboratively creating and managing tags to annotate and categorize content”collaboratively tagscategorizecontent

16
Social bookmarking If you’re going to share your folksonomies, why not share your bookmarks too? Maybe you don’t want to share everything you have bookmarked in your browser… But what about the stuff that’s related to work? Many services exist for this, but the one that most people know about is http://delicious.com/http://delicious.com/

17
Why share? Well you might as well ask Why go to a conference? “At a conference the most important things happen in the coffee break” – Hans Ulrich Obrist Why talk to colleagues? The internet doesn’t have to be a distraction, it can be an extension of your peer group. A place to find and exchange relevant information, build your profile and do your job more efficiently

18
Case study 1: Publications Most people’s workflow for papers consists of Download Print Stick in directory called ‘Papers’ Forget Maybe it might make it into Endnote! However online… you can do so much more Connotea Cite-U-Like Mendeley Zotero

19
Connotea

20
Cite-U-Like

21
Mendeley

22
Zotero

23
Case study 2 – finding things No, not via Google One of the issues of information overload is having to go to multiple sites in order to collate the day to day information you might want to read This is already a solved problem RSS ‘Really Simple Syndication’

25
Who has RSS? You can have RSS feeds from Journal publishers Search results Blogs Connotea, Cite-u-like, etc. Actually just about any dynamically updated web resource. RSS is everywhere Pervasive, Useful, Centralised, Shareable

26
Case study 3 - presentations Even the humble Powerpoint slide has gone all Web 2.0 Scientists give talks, upload their slides Feedback given Even if you don’t share, it can be good to consume Get ideas for presentations, formats etc.

29
Case study 4 – your work Yes, you can even share some of your work Protocols, early results, triumphs and tribulations Some scientists, keen to move from Web 2.0 to Science 2.0 are using blogs, wikis and the internet to publish their information outside of the limited sphere of journals One of the largest sites for this in the world is OpenWetWare

32
Science – being Open Already noted that biologists are good at openly sharing primary data, in increasingly standardised databases DNA sequence, protein sequence, microarray experiments Increasingly happening with publications too PLoS (Public Library of Science) and BioMedCentral (BMC) are two big players Rather than charging users for subscriptions, the authors 'pay to publish'
 and BioMedCentral (BMC) are two big players Rather than charging users for subscriptions, the authors pay to publish")
33
Why is Open good? Your work is not behind a 'paywall' It can be very frustrating trying to get hold of papers from journals or publishers that the University does not have a site licence for Your work can be more widely read Hard to argue that this is not desirable! The full text of your article is preserved and can even be analysed computationally to derive even more knowledge

34
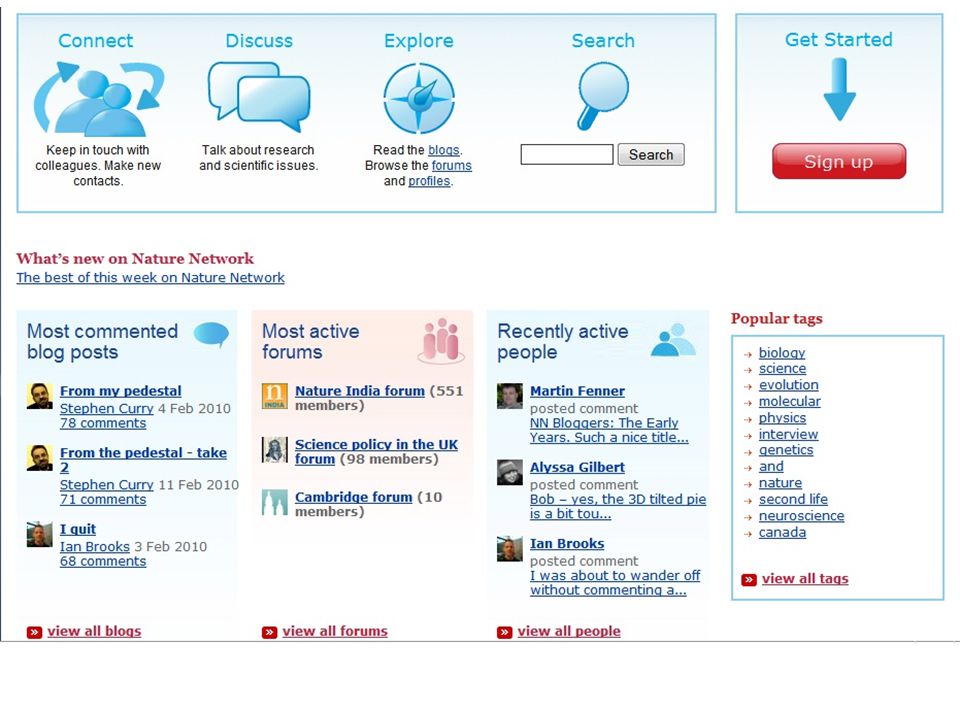
Publishing and Web 2.0 Many publishers now offer the ability to comment and ask for clarification on papers, especially in the Open Access journals Authors can respond to comments and issue rebuttals at the site the paper is downloaded Increases discourse on published papers, which is very hard to do in a paper journal Certain publishers are building up quite significant social networks around their published content. Nature Group in particular with their 'Nature Network'

36
I can't keep track of it all! As we have alluded to already it's hard to keep track of all the data that is out there and available Whilst we can have email alerts and RSS feeds, the issue is often one of separating out the signal from the noise Whilst a regular review of the sources you take in is a good way to do this there are other ways to try and filter out what is coming to you

37
FOAF approaches FOAF is 'friend of a friend' – the online equivalent of having someone come up and tell you about a cool paper they have just read – or someone has just told them about that might interest you. The success to FOAF approaches is being in the right setting so that you are interacting with the right set of people There have been many MANY attempts to build 'social networking for scientists' I'm only going to present one, and that's the one that currently works for me

38
FriendFeed Friendfeed is like Google Reader, it sucks in RSS you generate or pull in This display is updated in real time For instance I import - Cite-U-Like, Google Reader 'shared items‘, activity on software development sites, Flickr photos They appear in everyone who has subscribed to me – a la Twitter, only with threaded discussions where things percolate up to the top the more they are 'liked' or discussed There 'rooms' that you can subscribe to where you will also get content from on specific topics This is a GREAT way of seeing what other people are reading, watching, viewing, talking about – and in a way that you can leap right in and start discussing it with them.

40
Crowdsourcing & collaboration One of the coolest things I have seen FriendFeed used for is 'crowdsourcing' This is where someone posts up a request for help, and the community jumps in to help out Virtual collaborations spring up around the community, from people who have never met each other, and yet result in real scientific publications Don't be afraid to ask for help online, and don't be afraid to offer it either

41
Postgenomic – blog filter

42
From consumer to publisher The essence of Web 2.0 is that you provide the content Whether you're uploading a video of an experimental technique Whether you're releasing your slides onto Slideshare Whether you're sharing what you're reading on Connotea YOU are generating the content

43
Why should I produce content? It's a valid question Why should I blog? My blog is a mix of the personal and of work – that is my decision Many people just blog about their work, on the assumption your work life and your private life should be kept very separate I think this is increasingly hard to do As soon as you have work colleagues and friends mixed up on Facebook or Twitter, or whatever other social networks you used the streams are polluted

44
Blogging work Blogging provides an opportunity to hone your writing skills, rarely troubled outside of writing papers, end of year reports and a thesis Sharpen your analytical skills by posting about the papers your presenting at your lab meetings, and use http://ResearchBlogging.org to reach an audience http://ResearchBlogging.org Part of your network building activities It's a continually updating, evolving CV – marketing YOU It helps you build a brand It gets your name up there in Google All of these are 'informal esteem factors'

45
Case study 5: Allyson Allyson adopted the following technologies as part of her social workflow – blog, twitter, FriendFeed She started to attend conferences and blogged the talks, which fed into FriendFeed People on FriendFeed appreciated being kept up to date, and she became well known for it She has published 3 papers on using Web 2.0 to cover conferences She has been paid for to fly to the USA and attend conferences EVERYONE in her field, and some beyond – knows who she is and this is PRICELESS

46
Why should I care? I heard a question on a podcast recently, that someone who had published some stuff online in earlier, more headstrong times that were now at the top of Google wanted to know what the best way was to push this out of Googles memory (off the front page effectively!) The suggestion was to generate content – good content with your name attached, content that people want to read, and enough of it to ensure that you come up top every time on searching for your name What happens if someone decides to bad mouth you online in the future? Just make sure they don’t have enough Google traction to care
 The suggestion was to generate content – good content with your name attached, content that people want to read, and enough of it to ensure that you come up top every time on searching for your name What happens if someone decides to bad mouth you online in the future. Just make sure they don’t have enough Google traction to care.")
47
My experience Two years ago the first thing you got when googling my name was an entertaining set of news stories about a racist, redneck called Daniel Swan who had, in a drunken state one evening, decided to plant a giant burning cross in the front garden of a black family in his neighbourhood For various litigious reasons, his conviction was overturned and his stupid grinning face was on every page you hit, baseball cap on and leaning on his pickup 2 years later, and the only person you will hit on the front page is me and my grinning face instead – just regular online interaction and content production means that I get found first when my name is Googled

48
Your online brand As I alluded to earlier if you're going to publish content, in this day and age a future employer is going to Google you What you say and do in public forums is a matter of public record, it’s ok to engage and discuss, but be wary of getting mad You might want to have a look at what your Facebook profile exposes to the world. It may be more than you think. Whilst FB has many scientific groups, I don't think it's a great platform for scientific discussion. Best to keep your most personal life there, and your professional life elsewhere. LinkedIn is a great place for an online CV and networking

49
LinkedIn

50
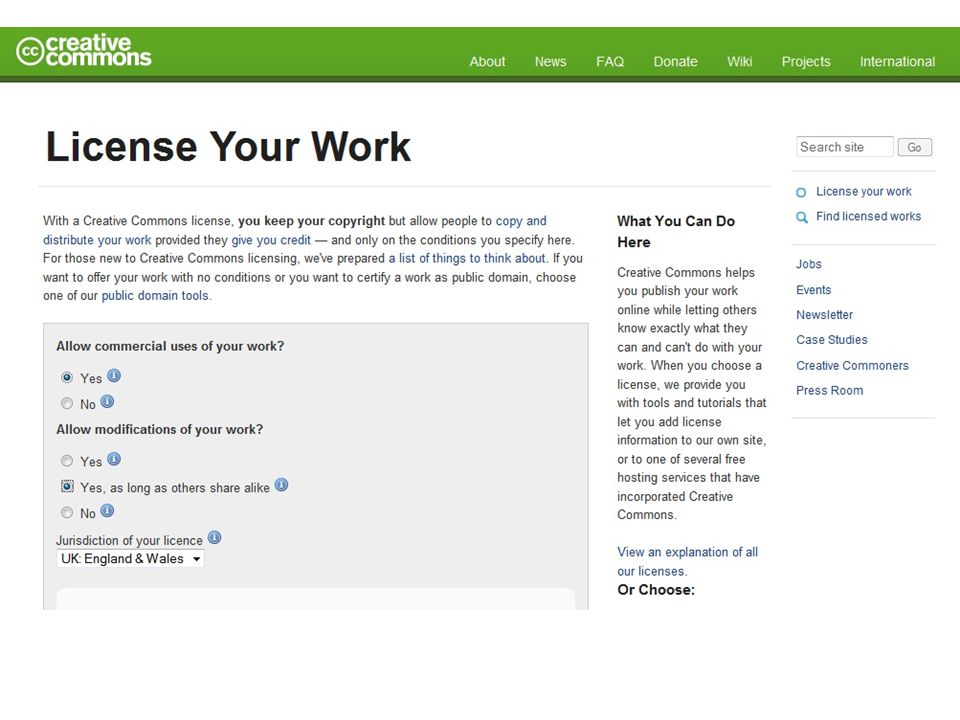
Licensing your content OK this is a dry topic and I won't go into it in too much detail Make sure that when you produce content online you state which licence it is under I would advise people to look into Creative Commons licencing for blog posts or anything extensive that you have written and posted online Clear guidelines on what to use so that you can control downstream what people do with your work Otherwise people may not have the right to reuse, redistribute your work, or at the worst, will have the right to do so, but won't have the requirement to credit you for it And you do want to be credited for your work!

52
In summary Please do share and tag your content with the world Think about how you can use the tools that are out there to support your scientific workflow, so that the data is there for YOU when YOU need it most Try to seek out like minded people in your field online and interact with them, the University isn't your scientific world – the world is your scientific world! Consider publishing your work in open access journals to widen its readership Build a recognisable, trusted and centralised online identity so when a potential employer starts to search for information about you what comes back is positive, intelligent and encouraging!

53
URLs Delicious (social bookmarking) http://delicious.com/http://delicious.com/ Connotea (social reference manager) http://connotea.org/ http://connotea.org/ Cite-U-Like (social reference manager) http://www.citeulike.org/ http://www.citeulike.org/ Mendeley (social reference manager) http://www.mendeley.com/ http://www.mendeley.com/ Zotero (research tool, reference manager) http://www.zotero.org/ http://www.zotero.org/ Google Reader (RSS reader) http://reader.google.com/http://reader.google.com/ SlideShare (share Powerpoint slides) http://www.slideshare.net/ http://www.slideshare.net/ BioScreenCast (share videos on scientific software) http://bioscreencast.com/ http://bioscreencast.com/ OpenWetWare (protocols, lab wikis and more) http://openwetware.org/wiki/Main_Page http://openwetware.org/wiki/Main_Page JoVE (Journal of Visualised Experiments) http://www.jove.com/ http://www.jove.com/ PLoS (Open Access journal) http://www.plos.org/http://www.plos.org/ BioMedCentral (Open Access journal) http://www.biomedcentral.com/ http://www.biomedcentral.com/ Nature Network (aggregation, scientific social networking) http://network.nature.com/http://network.nature.com/ FriendFeed (aggregation, scientific social networking) http://friendfeed.com/ http://friendfeed.com/ Postgenomic (scientific blog aggregation) http://www.postgenomic.com/ http://www.postgenomic.com/ ResearchBlogging (scientific blog aggregation) http://www.researchblogging.org/ http://www.researchblogging.org/ LinkedIn (your online CV) http://www.linkedin.com/http://www.linkedin.com/ CreativeCommons (licensing online content) http://creativecommons.org/ http://creativecommons.org/
 Connotea (social reference manager) Cite-U-Like (social reference manager) Mendeley (social reference manager) Zotero (research tool, reference manager) Google Reader (RSS reader) SlideShare (share Powerpoint slides) BioScreenCast (share videos on scientific software) OpenWetWare (protocols, lab wikis and more) JoVE (Journal of Visualised Experiments) PLoS (Open Access journal) BioMedCentral (Open Access journal) Nature Network (aggregation, scientific social networking) FriendFeed (aggregation, scientific social networking) Postgenomic (scientific blog aggregation) ResearchBlogging (scientific blog aggregation) LinkedIn (your online CV) CreativeCommons (licensing online content)")
Similar presentations