Download presentation
Presentation is loading. Please wait.

1
CBioC: Massive Collaborative Curation of Biomedical Literature Chitta Baral, Hasan Davulcu, Anthony Gitter, Graciela Gonzalez, Geeta Joshi-Tope, Mutsumi Nakamura, Prabhdeep Singh, Luis Tari, and Lian Yu.

2
Premise – current status of curation from text Our initial focus is on curation of “knowledge” nuggets from Biomedical articles. About 15 million abstracts in Pubmed 3 million published by US and EU researchers during 1994-2004 (800 articles per day) 300 K articles published so far reporting protein-protein interactions in human, yeast and mouse. BIND (in 7 yrs) -- 23K ; DIP – 3K; MINT – 2.4K.
 300 K articles published so far reporting protein-protein interactions in human, yeast and mouse. BIND (in 7 yrs) -- 23K ; DIP – 3K; MINT – 2.4K..")
3
Premise: High cost of human curation Overwhelming cost of large curation efforts may be unsustainable for long periods BIND: Nov 2005 bad news. Operated for 7 years Listed over 100 curators & programmers CND $29 million received in 2003, plus other funding Curation efforts of AFCS has recently stopped. Lack of funding for some genome annotation projects.

4
Premise: summary Human curation of text is expensive. Human curation of text is not scalable. Human curation of text is not sustainable.

5
Why not resort to computers? – do automatic extraction Lessons from DARPA funded MUCs (message understanding conferences) in 90s for a decade and at the cost of tens of millions of dollars. Getting to 60% recall and precision is quick Then every 5% improvement is about a years work. Even when we get to 90% for an individual entity extraction for recognizing 4 related entities: (.9) 4 =.64 Lessons from Biomedical text extraction No proper evaluation. Recognized that recall and precision is not very good even in the “best” systems.
 in 90s for a decade and at the cost of tens of millions of dollars. Getting to 60% recall and precision is quick Then every 5% improvement is about a years work. Even when we get to 90% for an individual entity extraction for recognizing 4 related entities: (.9) 4 =.64 Lessons from Biomedical text extraction No proper evaluation. Recognized that recall and precision is not very good even in the best systems..")
6
What do we do? How do we curate not only the existing articles, but also the future articles? Too important to give up! Need to think of a new way to do it. Faster computers, better sequencing technology and better algorithms came to the rescue of the Human Genome project. Hmm. What resources are we overlooking?

7
Key Idea If lots of articles are being written then lot of people are writing them and lot of people are reading them. If only we could make these people (the authors and the readers) contribute to the curation effort … Especially the readers; the ones who need the curated data!
 contribute to the curation effort … Especially the readers; the ones who need the curated data!.")
8
Mass collaboration has worked in Wikipedia Project Gutenberg Netflix rating Amazon rating Etc.

9
Mass collaborative curation: initial hurdles Russ Altman mentioned the challenges with respect to the authors. Sticking to a format Submitting data An average reader (S)he is not normally interested in filling a blank curation form. We can not make an average reader go though curation training. So it has to be very different from just making the existing curation tools available to the mass and expect them to contribute.
he is not normally interested in filling a blank curation form. We can not make an average reader go though curation training. So it has to be very different from just making the existing curation tools available to the mass and expect them to contribute..")
10
Mass collaborative curation : key initial ideas Make it very easy: user need not remember where (which database, which web page) to put the curated knowledge. Curation opportunity should present itself seamlessly. Curation should not be a burden to an average user Make the curated knowledge “thin”. There should be immediate rewards Do not start with a blank slate.

11
Realization of the key ideas: a biologist with a gene name Goes to Pubmed, types the gene name, clicks on one of the abstracts Curation panel presents itself automatically Our approach calls for researchers to contribute to the curation of facts as they read and research over the web But not with a blank slate No one wants to be the first one! Automatic extraction jump-starts the process, and then researchers improve upon the extracted data, “ironing out” inconsistencies by subsequent edits on a massive scale. Thin Schemas Average users turned off by traditional wide schemas Wide schemas need to be broken down.

12
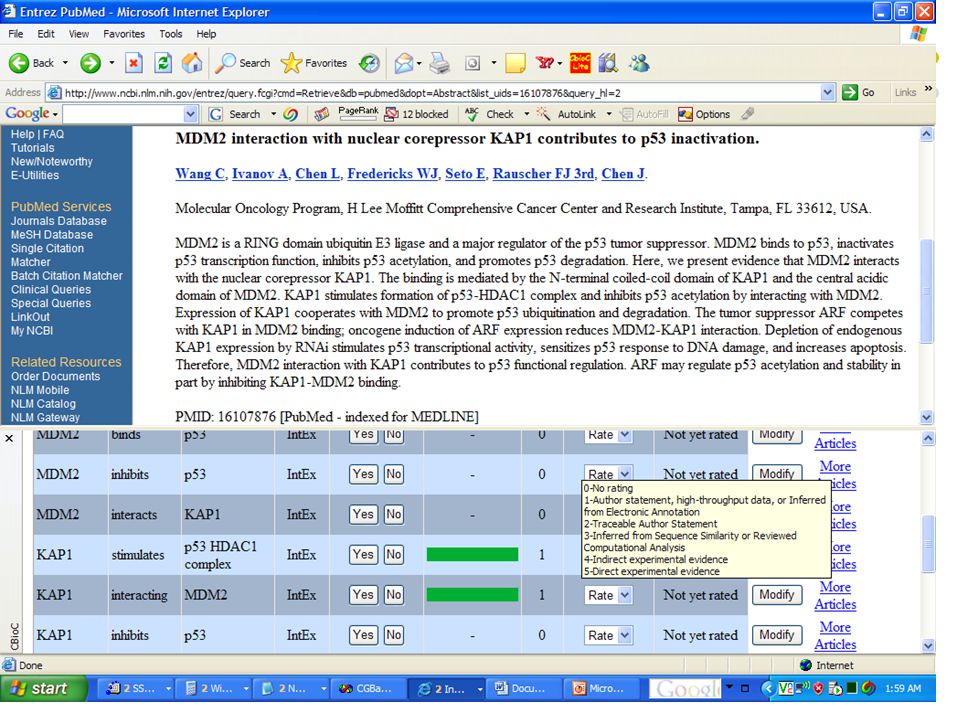
Case Study with CBioC When the abstract is displayed, all of the interactions reported in the abstract are shown. The interactions are either automatically extracted in advance by our system or for brand new abstracts the extraction process is done at display time. Thus, data becomes immediately available. Researchers then edit the extracted data, add new interactions, vote on the accuracy of the extraction, assign a confidence rating, and read comments from other researchers. If one or more of them goes deep into obtaining related info, the effort is not wasted and the rest of the community benefits.

14
Basic curation with CBioC Interactions are corrected, incorrect extractions are “voted down”, and rated on reliability based on the experimental evidence presented by the author. It takes a few seconds to vote on the correctness of the extractions With little effort by each researcher, information is made available immediately to the whole community.

17
with more effort… Any researcher that wishes to do a bit more can: add interactions missed by the extraction system add interactions reported within the full article fill up more fields in the database (such as organism, experimental method, location of the interaction, or supporting evidence). Added interactions are subject to the community vote, just as the automatically extracted interactions.

20
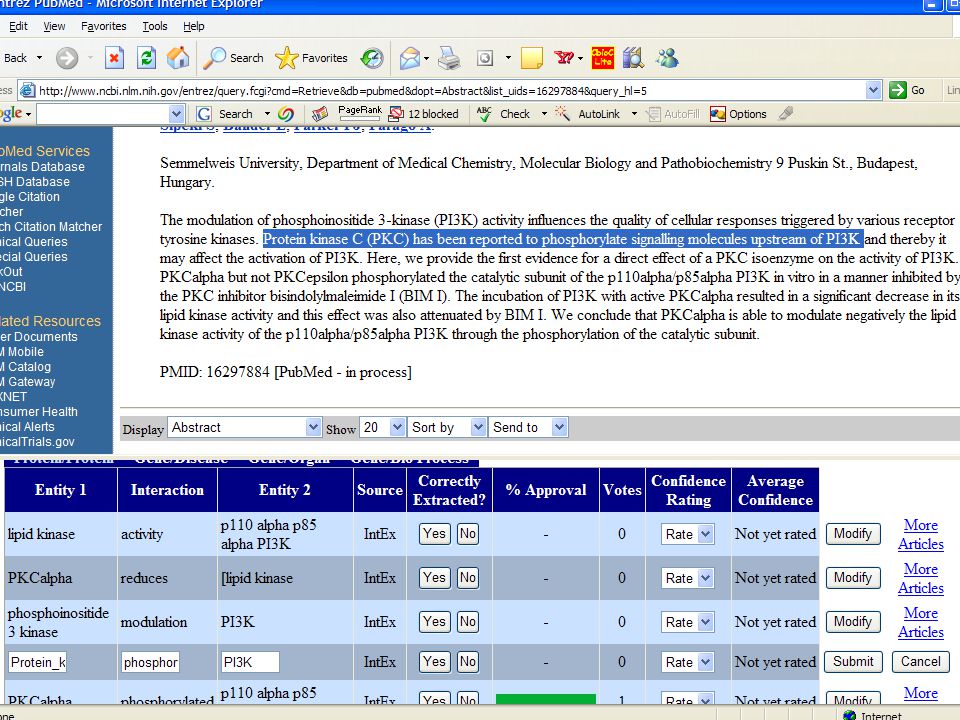
Case Study 2: Modifying A researcher could also modify the reported interactions For example, consider the following statement in PMID 16297884 : PKCalpha but not PKCepsilon phosphorylated the catalytic subunit of the p110alpha/p85alpha PI3K

21
Case Study 2: Modifying The automatic extraction system extracted (PKCepsilon, phosphorylates, p110alpha/ p85alpha PI3K), an error caused by the grammatical construction of the statement. In this case, the researcher should vote “No” on the accuracy of the extraction. This one cannot really be modified, it will eventually be “voted down” by enough “No” votes. and/or click “Modify” and edit the interaction and then rate its reliability based on the evidence presented by the author.

27
Addressing challenges Use ontologies and some automated tools to ensure consistency issues. To enter data user must register. Does each voter has equal weight? Trust management

28
Summary so far Information/curation window pops up automatically. Automatic extraction is used as a boot strap so that no user is working on a blank slate. Users vote on correctness, make corrections, add fact. Suppose 60% precision and recall of automatic extraction system A person will have an easier time discarding 40% of wrongly extracted text than identifying 60% of correct entries and entering them!

29
Very useful byproducts Avoids some problems with existing human curation approach Curators’ bias Curators miss things Curators have disagreements Slow access to newest findings Researchers at large have little or no control over what gets curated and when A large curated corpus of text gets created Very useful to evaluate and improve automated extraction systems.

30
Other features Other abstracts related to the specific interaction are accessible through the “More Articles” link. We are in the process of integrating data from publicly available databases. All data (raw and processed) will be publicly available Working on independent data access and querying engine.
 will be publicly available Working on independent data access and querying engine..")
31
Issues and further challenges Works well for certain kind of knowledge curation (interactions, …), but what about others (genome annotation ?) Null values Full papers versus abstracts Are thin schemas enough? Curating new kind of knowledge

32
Current status, current funding, call for collaboration Funded by Arizona State University Second (basic) beta version released. Proposals sent for a fully functional implementation. Some collaboration with outside groups are in works.

33
Current publications Collaborative Curation of Data from Bio-medical Texts and Abstracts and its integration. Chitta Baral, Hasan Davulcu, Mutsumi Nakamura, Prabhdeep Singh, Lian Yu and Luis Tari. Proceedings of the 2nd International Workshop on Data Integration in the Life Sciences (DILS'05), San Diego, July 20–22, 2005. In Lecture notes of computer science. Springer. An initial report. Ready to be submitted to a journal.
, San Diego, July 20–22, In Lecture notes of computer science. Springer. An initial report. Ready to be submitted to a journal..")
34
Group members and advisory board Post docs: Lian Yu and Graciela Gonzalez Biomedical expertise: Geeta Joshi-Tope (curation), Mike Berens (signal transduction in oncology) Students: Luis Tari, Prabhdeep Singh, Anthony Gitter, Amanda Ziegler Advisory board: Gary Bader, Ken Fukuda, Shankar Subramanian.
, Mike Berens (signal transduction in oncology) Students: Luis Tari, Prabhdeep Singh, Anthony Gitter, Amanda Ziegler Advisory board: Gary Bader, Ken Fukuda, Shankar Subramanian.")
35
Thanks Questions!

Similar presentations










>")

![NoodleBib Create a [bibliography, source list…] * [Your name/title/contact info] *Note: For the brackets, fill in your specific information.](/6/1607775/big_thumb.jpg "NoodleBib Create a [bibliography, source list…] * [Your name/title/contact info] *Note: For the brackets, fill in your specific information.>")







 Etsuko Moriyama, Ken Nickerson, Audrey Atkin (Biological Sciences) Steve Harris.>")






