Download presentation
Presentation is loading. Please wait.

1
Week 2 An overview Exposure and outcome (dependent and independent variables)Exposure and outcome (dependent and independent variables) Reliability and validityReliability and validity What is “statistical significance”?What is “statistical significance”? Relationships between variables -continuous variables (t-tests and z-tests) -continuous variables (correlations)Relationships between variables -continuous variables (t-tests and z-tests) -continuous variables (correlations) -the normal (gaussian) distribution -categorical variables (chi-square tests)-the normal (gaussian) distribution -categorical variables (chi-square tests) Two by two tables and confidence intervalsTwo by two tables and confidence intervals Review of the articlesReview of the articles Example 1: Children crossing streetsExample 1: Children crossing streets Measures of association between variablesMeasures of association between variables For next weekFor next week
 -continuous variables (correlations)Relationships between variables -continuous variables (t-tests and z-tests) -continuous variables (correlations) -the normal (gaussian) distribution -categorical variables (chi-square tests)-the normal (gaussian) distribution -categorical variables (chi-square tests) Two by two tables and confidence intervalsTwo by two tables and confidence intervals Review of the articlesReview of the articles Example 1: Children crossing streetsExample 1: Children crossing streets Measures of association between variablesMeasures of association between variables For next weekFor next week.")
2
A somewhat advanced society has figured how to package basic knowledge in pill form. A student, needing some learning, goes to the pharmacy and asks what kind of knowledge pills are available. The pharmacist says "Here's a pill for English literature." The student takes the pill and swallows it and has new knowledge about English literature! "What else do you have?" asks the student. "Well, I have pills for art history, biology, and world history, "replies the pharmacist. The student asks for these, and swallows them and has new knowledge about those subjects! Then the student asks, "Do you have a pill for statistics? "The pharmacist says "Wait just a moment", and goes back into the storeroom and brings back a whopper of a pill that is about twice the size of a jawbreaker and plunks it on the counter. "I have to take that huge pill for statistics?" inquires the student. The pharmacist understandingly nods his head and replies "Well, you know statistics always was a little hard to swallow."

3
Epidemiologic study designs 1.Randomized controlled trial Considered the ‘gold standard’ Exposure is assigned randomly Participants followed over time to assess outcome Analytic comparison of risk or benefit in exposed vs. not exposed Can be applied to program evaluation

4
Epidemiologic study design 2 2. Cohort study One group exposed Other group unexposed Participants followed over time to assess outcome Analytic comparison of risk in exposed vs. not exposed Can be applied to program evaluation

5
Epidemiologic study designs 3 3.Case-control study Based on outcomeBased on outcome Exposure is compared in those with and without outcomeExposure is compared in those with and without outcome Analytic comparison of risk in exposed vs. not exposedAnalytic comparison of risk in exposed vs. not exposed 4. Descriptive study Provides descriptive statistics of problem under studyProvides descriptive statistics of problem under study No analytic comparison of risk / benefitNo analytic comparison of risk / benefit Often precedes analytic studiesOften precedes analytic studies

6
Dependent vs independent variables Remember the exposure/outcome relationship Another way to describe it is to attribute dependent and independent variables-the outcome depends on the independent exposure variables It is the association between these variables that leads us to statistical tests The test we use depends on the type of variable

7
Statistical significance What is statistical significance? The probability that the observed relationship could have happed by chance The p-value and confidence interval are the usual measures of significance Set by tradition at 0.05 or 95% The higher the p value, the more likely it could have happened by chance The wider the confidence interval, the more likely it could have happened by chance Both driven by variability in the data and sample size

8
Types of variables Continuous variables -variables for which there is a range of responses e.g., age, blood pressure, weight Categorical variables –Variables that fall into categories –e.g, gender, smoking status

9
Hypothesis testing for continuous variables Mean (the average number) -calculated by summing all the numbers and dividing by n -Hypothesis testing usually done using a t-test to compare the 2 means -Significance of t-test based on sample size and variability within the data Median (the number in the middle) -not usually tested Mode (the most frequent response) -not usually tested
 -calculated by summing all the numbers and dividing by n -Hypothesis testing usually done using a t-test to compare the 2 means -Significance of t-test based on sample size and variability within the data Median (the number in the middle) -not usually tested Mode (the most frequent response) -not usually tested")
10
Hypothesis testing for categorical variables Counts (how many fall within each category) Compare using 2X2 table Proportions (what percentage fall within each category) Compare 2 proportions Frequency distributions (comparing counts and percentages between categories) Compare using chi-square test
 Compare using 2X2 table Proportions (what percentage fall within each category) Compare 2 proportions Frequency distributions (comparing counts and percentages between categories) Compare using chi-square test")
11
2X2 tables: the foundation Disease or other outcome No disease or other outcome Exposed ab Not exposed cd

12
2X2 tables: estimating associations Disease or other outcome No disease or other outcome Exposed aba+b Not exposed cdc+d a+cb+da+b+c+d

13
Odds ratios and relative risks Odds ratios (ad/bc) calculate the odds of an outcome given an exposure Relative risk (a/a+b)/c/c+d) calculates the relative risk of an outcome in exposed compared to non-exposed group Statistical packages calculate confidence intervals
 calculate the odds of an outcome given an exposure Relative risk (a/a+b)/c/c+d) calculates the relative risk of an outcome in exposed compared to non-exposed group Statistical packages calculate confidence intervals")
14
Confidence intervals Confidence intervals are used for hypothesis testing in 2X2 tables (and others) The width of a confidence interval is based on the variablility within the data and the sample size An OR or RR of 1 = no association A confidence interval that crosses 1 is NOT statistically significant
 The width of a confidence interval is based on the variablility within the data and the sample size An OR or RR of 1 = no association A confidence interval that crosses 1 is NOT statistically significant")
15
Regression lines and correlation Correlation is the measure of the way one variable is associated with another Can be done with 2 continuous variables The regression line is the best fit between 2 variables Ranges from -1 to 1

16
Article review Questions to consider: What is the research question? What is their study design? What is the exposure variable(s)? What is the outcome variable? What are the strengths and limitations? Who funded the study? How compelling are the findings?
. What is the outcome variable. What are the strengths and limitations. Who funded the study. How compelling are the findings .")
17
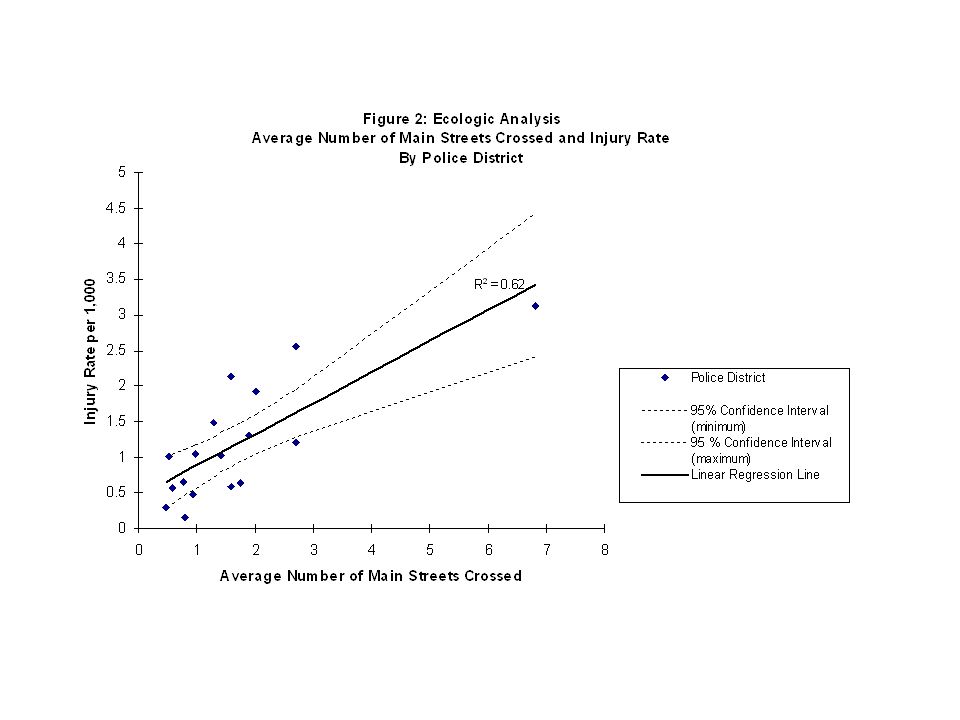
Example # 1 Statistical associations of the number of streets crossed by children and: -socio-economic indicators -child pedestrian injury rate

18
Background Child pedestrian injury rate has been declining in many countries, including Canada Concern has been expressed that the decline is due to a reduction in exposure to traffic (i.e., children are driven or bussed rather than walking)
")
19
Objective The objective of this study was to measure the number of streets children cross on one day To see if the number of streets crossed varies by socio-economic status To see if the child pedestrian injury rate is associated with the number of streets crossed

20
Variables Number of streets crossed as reported by parents from a random sample of schools in Montreal Socio-economic status measured by: -car ownership -parental education -home ownership Injury rate in police district as reported by the police

21
Methods Frequency distribution of average # of streets crossed presented by age and SES Statistical testing for the differences between means for categorical variables Scatterplot generated and regression line calculated

22
Table 1 Number of Streets Crossed by Age and Socio-economic Indicators* AgeNMeanSD 5 & 64873.84.2 77304.25.0 8 &95194.85.3 106575.55.8 11 & 121086.66.3 Number of cars 04675.95.8 111914.85.3 2 +8153.84.8 Home Ownership Rent home12135.55.6 Own home12103.84.7

23
No car1 car Average streets crossed (Mean) 5.94.8 Standard deviation 5.85.3 Sample size4671171 Z Test for difference between means 13.8, p<0.001 Comparing average streets crossed by car ownership
 Standard deviation Sample size Z Test for difference between means 13.8, p<0.001 Comparing average streets crossed by car ownership")
25
Measures of association between variables Tied in to the concept of reliability and validity Sometimes we need to test a new variable in relation to an old one For example, a new questionnaire, faster blood test, etc. Several ways to measure association: Cronbach’s alpha, kappa, sensitivity, specificity, positive predictive value, negative predictive value

26
Cronbach’s alpha Measures the reliability of a psychometric instrument Assesses the extent to which a set of test items can be treated as measuring a single latent variable Mean correlation between a set of items with the mean of all the other items Looks at variation between individuals compared to variation due to items Can be between – infinity and 1 (although usually only between 0 and 1) Usually considered ‘good’ if > 0.8
 Usually considered ‘good’ if > 0.8")
27
Kappa Measures the extent to which ratings given by 2 raters agree Often used when experts are assigning scores based on opinions (e.g., medication errors) Gives credit when scores match exactly, takes away agreement when they don’t Can be between 0 and 1 Usually considered ‘good’ if > 0.7
 Gives credit when scores match exactly, takes away agreement when they don’t Can be between 0 and 1 Usually considered ‘good’ if > 0.7")
28
Sensitivity and specificity Sensitivity Measures the extent to which a test agrees with a ‘gold standard’ Often used when trying out a new diagnostic test Reports how often the new test agrees with the old when positive Captures the false negatives Calculated using a 2 X 2 table Acceptability of score depends on test qualities

29
Sensitivity and specificity Specificity Measures the extent to which a test agrees with a ‘gold standard’ Often used when trying out a new diagnostic test Captures the ‘false positives’ Reports how often the new test agrees with the old when negative (eg accurately reports the absence of the condition) Calculated using a 2 X 2 table Acceptability of score depends on test qualities
 Calculated using a 2 X 2 table Acceptability of score depends on test qualities")
30
2X2 tables revisited Gold standard + (has condition) Gold standard – (does not have condition) New test + ab New test - cd
 Gold standard – (does not have condition) New test + ab New test - cd")
31
Calculating sensitivity and specificity Sensitivity= number who are both disease positive and test positive/number who are disease positive a/a+c Specificity = number who are both disease negative and test negative/number who are disease negative d/d+b

32
Understanding sensitivity and specificity Sensitivity is high when the test picks up a lot of the true disease (has few false negatives) High sensitivity is important for infectious diseases (e.g., HIV) Specificity is high when the test does not have false positives. This is important when the consequences of treating the disease are significant (e.g., cancer)
.")
33
Positive and negative predictive value Tells you how good a test is at predicting whether a patient actually has the disease Positive predictive value is the probability that the patient has the disease given a positive test Depends on sensitivity, specificity and the prevalence of the disease

34
Overview Different types of variables are measured and presented differently P values and confidence intervals are the measure of statistical significance Tell us the probability that these results could have happened by chance Cronbach’s alpha, kappa, sensitivity and specificity tell us about relationships between measurements

35
For next week 1 Read Chapter 3 in the text Read the ICES privacy document (www.ices.on.ca) Think about privacy and confidentiality What issues are relevant to you in your current research?

37
For next week 2 Identify your data set Where did it come from? How was it collected? What type of variables does it include? What is your research question? What are your exposure variables? What is your outcome variable? If you are not familiar with SPSS it is STRONGLY recommended that you complete the tutorial

Similar presentations

 Oklahoma.>")





, and the other of people with the same general characteristics.>")





: Analysing data.>")






