Download presentation
Presentation is loading. Please wait.

1
Chapter 3 Arithmetic for Computers
陳瑞奇(J.C. Chen) 亞洲大學資訊工程學系 Adapted from class notes by Prof. C.T. King, NTHU, Prof. M.J. Irwin, PSU and Prof. D. Patterson, UCB
 亞洲大學資訊工程學系. Adapted from class notes by. Prof. C.T. King, NTHU, Prof. M.J. Irwin, PSU. and Prof. D. Patterson, UCB.")
2
Review: MIPS Addressing Modes
1. Operand: Register addressing op rs rt rd funct Register word operand op rs rt offset 2. Operand: Base addressing base register Memory word or byte operand 3. Operand: Immediate addressing op rs rt operand 4. Instruction: PC-relative addressing op rs rt offset Memory branch destination instruction Program Counter (PC) 5. Instruction: Pseudo-direct addressing Memory op jump address || jump destination instruction Program Counter (PC)
 5. Instruction: Pseudo-direct addressing. Memory. op jump address. || jump destination instruction. Program Counter (PC)")
3
Fig. 3.1 p.169 (頁165 -166)
")
4
MIPS Arithmetic Logic Unit (ALU)
32 m (operation) result A B ALU 4 zero ovf 1 Must support the Arithmetic/Logic operations of the ISA add, addi, addiu, addu sub, subu, neg mult, multu, div, divu sqrt and, andi, nor, or, ori, xor, xori beq, bne, slt, slti, sltiu, sltu CarryOut With special handling for sign extend – addi, andi, ori, xori, slti zero extend – lbu, addiu, sltiu no overflow detected – addu, addiu, subu, multu, divu, sltiu, sltu
 result. A. B. ALU. 4. zero. ovf. 1. Must support the Arithmetic/Logic operations of the ISA. add, addi, addiu, addu. sub, subu, neg. mult, multu, div, divu. sqrt. and, andi, nor, or, ori, xor, xori. beq, bne, slt, slti, sltiu, sltu. CarryOut. With special handling for. sign extend – addi, andi, ori, xori, slti. zero extend – lbu, addiu, sltiu. no overflow detected – addu, addiu, subu, multu, divu, sltiu, sltu.")
5
MIPS Arithmetic Logic Unit (cont.)
4 32 32 FIGURE C.5.13 The values of the three ALU control lines, Bnegate, and Operation, and the corresponding ALU operations. 32 add, addi, addiu, addu sub, subu, beq, bne Fig. C.5.14

6
Review: ALU Construction
1. AND gate (c=a•b) 2. OR gate (c=a+b) 3. Inverter (c=-a) 4. Multiplexor (if d==0, c=a; Else c=b) 7
 2. OR gate (c=a+b) 3. Inverter (c=-a) 4. Multiplexor (if d==0, c=a; Else c=b) 7.")
7
3.2 Addition & Subtraction
p.225 (頁227) 3.2 Addition & Subtraction Subtraction Addition 3.1 Fig. 3.1
 3.2 Addition & Subtraction. Subtraction. Addition Fig")
8
Addition & Subtraction (cont.)
Just like in grade school (carry/borrow 1s) 0101 Two's complement operations easy subtraction using addition of negative numbers 1010 Overflow (result too large for finite computer word): e.g., adding two n-bit numbers does not yield an n-bit number
 Two s complement operations easy. subtraction using addition of negative numbers Overflow (result too large for finite computer word): e.g., adding two n-bit numbers does not yield an n-bit number")
9
Review: A Full Adder How can we use it to build a 32-bit adder?
carry_in A B carry_in carry_out S 1 A 1-bit Full Adder S B carry_out S = A B carry_in (odd parity function) carry_out = A&B | A&carry_in | B&carry_in How can we use it to build a 32-bit adder? How can we modify it easily to build an adder/subtractor?
 carry_out = A&B | A&carry_in | B&carry_in. How can we use it to build a 32-bit adder How can we modify it easily to build an adder/subtractor")
10
A 32-bit Ripple Carry Adder/Subtractor
add/sub 1-bit FA S0 c0=carry_in c1 S1 c2 S2 c3 c32=carry_out S31 c31 . . . A0 A1 A2 A31 Remember 2’s complement is just complement all the bits add a 1 in the least significant bit 1 B0 control (0=add,1=sub) B0 if control = 0, !B0 if control = 1 A B + 1001 For lecture 1 0001 1 0001 = A - B
 B0 if control = 0, !B0 if control = 1. A 0111 0111 B For lecture = A - B.")
11
Overflow Detection Overflow: the result is too large to represent in 32 bits No overflow when adding a positive and a negative number No overflow when signs are the same for subtraction Overflow occurs when adding two positives yields a negative or, adding two negatives gives a positive or, subtract a negative from a positive gives a negative or, subtract a positive from a negative gives a positive On your own: Prove you can detect overflow by: Carry into MSB xor Carry out of MSB, ex for 4 bit signed numbers For class handout 1 + 7 3 1 + –4 – 5

12
Overflow Detection (cont.)
Overflow: the result is too large to represent in 32 bits Overflow occurs when adding two positives yields a negative or, adding two negatives gives a positive or, subtract a negative from a positive gives a negative or, subtract a positive from a negative gives a positive On your own: Prove you can detect overflow by: Carry into MSB xor Carry out of MSB, ex for 4 bit signed numbers For lecture Recalled from some earlier slides that the biggest positive number you can represent using 4-bit is 7 and the smallest negative you can represent is negative 8. So any time your addition results in a number bigger than 7 or less than negative 8, you have an overflow. Keep in mind is that whenever you try to add two numbers together that have different signs, that is adding a negative number to a positive number, overflow can NOT occur. Overflow occurs when you to add two positive numbers together and the sum has a negative sign. Or, when you try to add negative numbers together and the sum has a positive sign. If you spend some time, you can convince yourself that If the Carry into the most significant bit is NOT the same as the Carry coming out of the MSB, you have a overflow. 1 1 1 1 1 1 1 + 7 3 1 + –4 – 5 – 6 1 1 7

13
Overflow Detection (cont.)
")
14
p.226 (頁228) Overflow Conditions 3.2
 Overflow Conditions 3.2")
15
p.227 (頁229) Effects of Overflow An exception (interrupt) occurs
Control jumps to predefined address for exception Interrupted address is saved for possible resumption (EPC) Don't always want to detect overflow — new MIPS instructions: addu, addiu, subu
 Don t always want to detect overflow — new MIPS instructions: addu, addiu, subu.")
16
p.227 (頁229) move from coprocessor 0 jr $s1
 move from coprocessor 0 jr $s1")
17
Fig. B.10.1 MIPS R2000 CPU and FPU

18
Arithmetic for Multimedia
Graphics and media processing operates on vectors of 8-bit and 16-bit data Use 64-bit adder, with partitioned carry chain Operate on 8×8-bit, 4×16-bit, or 2×32-bit vectors SIMD (single-instruction, multiple-data) Saturating operations On overflow, result is largest representable value c.f. 2s-complement modulo arithmetic E.g., clipping in audio, saturation in video
 Saturating operations. On overflow, result is largest representable value. c.f. 2s-complement modulo arithmetic. E.g., clipping in audio, saturation in video.")
19
Clipping in Audio Clipping is a form of waveform distortion that occurs when an amplifier is overdriven and attempts to deliver an output voltage or current beyond its maximum capability.

20
p.230 (頁233) 3.3 Multiplication Unsigned multiply example : Example.
1000 x 1011 1000_ 0000__ 1000___ Example. (0010)2 x (0011)2: 0010 x 0011 0010_ 0000__ 0000___ Multiplicand Multiplier 17
2 x (0011)2: x _. 0000__. 0000___ Multiplicand. Multiplier. 17.")
21
Multiplication (cont.)
Binary multiplication is just a bunch of left shifts and adds n multiplicand multiplier partial product array can be formed in parallel and added in parallel for faster multiplication n double precision product 2n

22
Multiplication (cont.)
More complicated than addition accomplished via shifting and addition More time and more area Let's look at 3 versions based on a gradeschool algorithm (multiplicand) __x_ (multiplier) Negative numbers: convert and multiply there are better techniques, we won’t look at them
 __x_1011 (multiplier) Negative numbers: convert and multiply. there are better techniques, we won’t look at them.")
23
Multiplication: Implementation
First version Multiplication: Implementation p (頁 ) 1000 x 1011 1000_ 0000__ 1000___ Control (Fig. 3.5) Datapath (Fig. 3.4) 1011 0001 0000 0010 0101 X Done!
 x _. 0000__. 1000___ Control. (Fig. 3.5) Datapath (Fig. 3.4) X. Done!")
24
Multiplication: Refined Version
Multiplier starts in right half of product Fig. 3.6 p.233 (頁236) 把被乘數加到乘積的 左半邊 , 然後把結果放到乘積暫存器的左半邊 What goes here? 1000 Multiplicand Done! 32-bit ALU 0110 0011 0110 1011 1000 0101 0000 0100 1100 1000 0010 1011 0101 0001 Shift right X
 把被乘數加到乘積的 左半邊 , 然後把結果放到乘積暫存器的左半邊. What goes here Multiplicand. Done! 32-bit ALU Shift right. X.")
25
Fig. 3.8 p.236 (頁239) Faster Multiplier Uses multiple adders X1011
Cost/performance tradeoff 33 bits B. 0 33 bits Bit 1 . 1110 X1011 01110 10001 0000 31 … … 1 C 32 1 Bit 0 Bit 1

26
MIPS Multiply Instruction
Multiply produces a double precision product mult $t1, $t2 # hi||lo=$t1 * $t2 move from register Lo

27
MIPS Multiply Instruction (cont.)
Multiply produces a double precision product mult $s0, $s1 # hi||lo = $s0 * $s1 Low-order word of the product is left in processor register lo and the high-order word is left in register hi Instructions mfhi rd and mflo rd are provided to move the product to (user accessible) registers in the register file op rs rt rd shamt funct Multiplies are done by fast, dedicated hardware and are much more complex (and slower) than adders Hardware dividers are even more complex and even slower multu – does multiply unsigned Both multiplies ignore overflow, so its up to the software to check to see if the product is too big to fit into 32 bits. There is no overflow if hi is 0 for multu or the replicated sign of lo for mult.
 registers in the register file. op rs rt rd shamt funct. Multiplies are done by fast, dedicated hardware and are much more complex (and slower) than adders. Hardware dividers are even more complex and even slower. multu – does multiply unsigned. Both multiplies ignore overflow, so its up to the software to check to see if the product is too big to fit into 32 bits. There is no overflow if hi is 0 for multu or the replicated sign of lo for mult.")
28
3.4 Division Division is just a bunch of quotient digit guesses and right shifts and subtracts Dividend = Quotient X Divisor + Remainder (n + 1) n n quotient dividend (2n – 1) divisor (2n) partial remainder array remainder n
 n. n. quotient. dividend (2n – 1) divisor. (2n) partial. remainder. array. remainder. n.")
29
p.237 (頁241) Fig. 3.9 Division: First version 0000 0010 0000 0100
00011 0010 0010 0000 … … p. 186(頁183) 0000 0000 0000 00011 0000 0001 Subtract Subtract Subtract Subtract Subtract Add Add Add 33 repetitions =#dividend - #divisor + 1 =
 Subtract. Subtract. Subtract. Subtract. Subtract. Add. Add. Add repetitions. =#dividend - #divisor + 1. =")
30
Division (cont.) Fig. 3.10 p.238 (頁242)
 Fig p.238 (頁242)")
31
p.240(頁244) Fig. 3.12 Optimized Divider 1000 p. 183 (頁180) Subtract
01001 1000 Divisor … … p. 183 (頁180) 0010 Subtract Subtract Subtract Subtract 32-bit ALU 32-bit ALU Add Add 32 repetitions! Quotient Shift right Shift right Control test Shift left Write Final repetition: Shift Remainder Right: Remainder Quotient
 Subtract. Subtract. Subtract. Subtract. 32-bit ALU. 32-bit ALU. Add. Add. 32 repetitions! Quotient. Shift right. Shift right. Control. test. Shift left. Write. Final repetition: Shift Remainder Right: Remainder. Quotient.")
32
MIPS Divide Instruction
Divide generates the reminder in hi and the quotient in lo div $s0, $s1 # lo = $s0 / $s1 # hi = $s0 mod $s1 Instructions mfhi rd and mflo rd are provided to move the quotient and reminder to (user accessible) registers in the register file Quotient Remainder op rs rt rd shamt funct Seems odd to me that the machine doesn’t support a double precision dividend in hi || lo but it looks like it doesn’t As with multiply, divide ignores overflow so software must determine if the quotient is too large. Software must also check the divisor to avoid division by 0.
 registers in the register file. Quotient. Remainder. op rs rt rd shamt funct. Seems odd to me that the machine doesn’t support a double precision dividend in hi || lo but it looks like it doesn’t. As with multiply, divide ignores overflow so software must determine if the quotient is too large. Software must also check the divisor to avoid division by 0.")
33
MIPS Multiply/Divide Summary
Move To register Lo

34
MIPS Multiply/Divide Summary (cont.)
p.243 (頁246) Fig. 3.13
 Fig")
35
3.5 Floating Point (a brief look)
We need a way to represent numbers with fractions, e.g., very small numbers, e.g., very large numbers, e.g., 109 Representation: sign, exponent, significand: (–1)sign significand 2exponent more bits for significand gives more accuracy more bits for exponent increases range IEEE 754 floating point standard: single precision: 8 bit exponent, 23 bit significand double precision: 11 bit exponent, 52 bit significand
sign significand 2exponent. more bits for significand gives more accuracy. more bits for exponent increases range. IEEE 754 floating point standard: single precision: 8 bit exponent, 23 bit significand. double precision: 11 bit exponent, 52 bit significand.")
36
Representing Big (and Small) Numbers
What if we want to encode the approx. age of the earth? 4,600,000, or x 109 or the weight in kg of one a.m.u. (atomic mass unit) or x 10-27 There is no way we can encode either of the above in a 32-bit integer. p.245 (頁249) Floating point representation (-1)sign x F x 2E Still have to fit everything in 32 bits (single precision) Notice that in scientific notation the mantissa is represented in normalized form (no leading zeros) s E (exponent) F (fraction) 1 bit bits bits The base (2, not 10) is hardwired in the design of the FPALU More bits in the fraction (F) or the exponent (E) is a trade-off between precision (accuracy of the number) and range (size of the number)
 or 1.6 x There is no way we can encode either of the above in a 32-bit integer. p.245. (頁249) Floating point representation (-1)sign x F x 2E. Still have to fit everything in 32 bits (single precision) Notice that in scientific notation the mantissa is represented in normalized form (no leading zeros) s E (exponent) F (fraction) 1 bit 8 bits 23 bits. The base (2, not 10) is hardwired in the design of the FPALU. More bits in the fraction (F) or the exponent (E) is a trade-off between precision (accuracy of the number) and range (size of the number)")
37
IEEE 754 FP Standard Sign and magnitude representation
(-1) * (1+Significand) * 2 Single precision Double precision Overflow(溢位)/Underflow(短值)是由於指數太大/太小 而無法在指數欄位上表示出來 eg., =0.110x2-1 =1.100x2-2 hidden bit s E Exponent Significand S 1-bit 8-bit 23-bit 32 bits S Exponent Significand 1-bit 11-bit 52-bit 64 bits 23
 * (1+Significand) * 2. Single precision. Double precision. Overflow(溢位)/Underflow(短值)是由於指數太大/太小 而無法在指數欄位上表示出來. eg., =0.110x2-1. =1.100x2-2. hidden bit. s. E. Exponent. Significand. S. 1-bit. 8-bit. 23-bit. 32 bits. S. Exponent. Significand. 1-bit. 11-bit. 52-bit. 64 bits. 23.")
38
IEEE 754 FP Standard (cont.)
IEEE 754 的偏差值(Bias)在單精度方面為127, 在倍精度方面為1023 (-1) * (1+Significand) * 2 Exponent = E + bias E = Exponent - bias S E E 128 127 … -1 -127 Exponent 255 254 126 Bias
在單精度方面為127, 在倍精度方面為1023. (-1) * (1+Significand) * 2. Exponent = E + bias. E = Exponent - bias. S. E. E … Exponent Bias.")
39
IEEE 754 FP Standard (cont.)
範例 以 IEEE 754 二進位表示法,說明十進位 -0.75的單精度及倍精度的格式 。 解答. -0.75 = -(0.11)2 = -(1.1)2 * 2-1 單精度: …0 (126)10 倍精度: … 00000 (1022)10 hidden bit ( ) – 127 = -1 ( ) – 1023 = -1 25
2. = -(1.1)2 * 2-1. 單精度: …0. (126)10. 倍精度: … (1022)10. hidden bit. ( ) – 127 = -1. ( ) – 1023 =")
40
IEEE 754 FP Standard (cont.)
Most computers these days conform to the IEEE 754 floating point standard (-1)sign x (1+F) x 2E-bias Formats for both single and double precision F is stored in normalized form where the msb in the fraction is 1 (so there is no need to store it!) – called the hidden bit To simplify sorting FP numbers, E comes before F in the word and E is represented in excess (biased) notation p.246(頁251) Fig. 3.14 Single Precision Double Precision Object Represented E (8) F (23) E (11) F (52) true zero (0) nonzero ± denormalized number 1-254 anything 1-2046 ± floating point number 255 2047 ± infinity not a number (NaN) S Book distinguishes between the representation with the hidden bit there – significand (the 24 bit version) , and the one with the hidden bit removed – fraction (the 23 bit version)
sign x (1+F) x 2E-bias. Formats for both single and double precision. F is stored in normalized form where the msb in the fraction is 1 (so there is no need to store it!) – called the hidden bit. To simplify sorting FP numbers, E comes before F in the word and E is represented in excess (biased) notation. p.246(頁251) Fig Single Precision. Double Precision. Object Represented. E (8) F (23) E (11) F (52) true zero (0) nonzero. ± denormalized number anything ± floating point number ± infinity. not a number (NaN) S. Book distinguishes between the representation with the hidden bit there – significand (the 24 bit version) , and the one with the hidden bit removed – fraction (the 23 bit version)")
41
Floating Point Complexities
Operations are somewhat more complicated (see text) In addition to overflow we can have “underflow” Accuracy can be a big problem IEEE 754 keeps two extra bits, guard and round four rounding modes positive divided by zero yields “infinity” zero divide by zero yields “not a number” other complexities Implementing the standard can be tricky
 In addition to overflow we can have underflow Accuracy can be a big problem. IEEE 754 keeps two extra bits, guard and round. four rounding modes. positive divided by zero yields infinity zero divide by zero yields not a number other complexities. Implementing the standard can be tricky.")
42
Floating Point Addition
Addition (and subtraction) (F1 2E1) + (F2 2E2) = F3 2E3 Step 1: Restore the hidden bit in F1 and in F2 Step 1: Align fractions by right shifting F2 by E1 - E2 positions (assuming E1 E2) keeping track of (three of) the bits shifted out in a guard bit, a round bit, and a sticky bit Step 2: Add the resulting F2 to F1 to form F3 Step 3: Normalize F3 (so it is in the form 1.XXXXX …) If F1 and F2 have the same sign F3 [1,4) 1 bit right shift F3 and increment E3 If F1 and F2 have different signs F3 may require many left shifts each time decrementing E3 Step 4: Round F3 and possibly normalize F3 again x 24 vs x22= x 24 , … … Note that smaller significand is the one shifted (while increasing its exponent until its equal to the larger exponent) overflow/underflow can occur during addition and during normalization rounding may lead to overflow/underflow as well =
 (F1 2E1) + (F2 2E2) = F3 2E3. Step 1: Restore the hidden bit in F1 and in F2. Step 1: Align fractions by right shifting F2 by E1 - E2 positions (assuming E1 E2) keeping track of (three of) the bits shifted out in a guard bit, a round bit, and a sticky bit. Step 2: Add the resulting F2 to F1 to form F3. Step 3: Normalize F3 (so it is in the form 1.XXXXX …) If F1 and F2 have the same sign F3 [1,4) 1 bit right shift F3 and increment E3. If F1 and F2 have different signs F3 may require many left shifts each time decrementing E3. Step 4: Round F3 and possibly normalize F3 again x 24 vs x22= x , … … Note that smaller significand is the one shifted (while increasing its exponent until its equal to the larger exponent) overflow/underflow can occur during addition and during normalization. rounding may lead to overflow/underflow as well =")
43
Floating point addition
p.252 (頁257) Fig. 3.15 Still normalized? eg., Step 5: Rehide the most significant bit of F3 before storing the result
 Fig Still normalized eg., Step 5: Rehide the most significant bit of F3 before storing the result.")
44
大小比較 p.254 (頁259) Fig. 3.16 小 大 大 加減運算 正規化 指數遞增減
 Fig 小 大 大 加減運算 正規化 指數遞增減")
45
Fig. B.10.1 $f0 $f1 $f31 MIPS R2000 CPU and FPU

46
MIPS Floating Point Instructions
MIPS has a separate Floating Point Register File ($f0, $f1, …, $f31) (whose registers are used in pairs for double precision values) with special instructions to load to and store from them lwcl $f0,54($s2) #$f0 = Memory[$s2+54] swcl $f0,58($s4) #Memory[$s4+58] = $f0 And supports IEEE 754 single add.s $f2,$f4,$f6 #$f2 = $f4 + $f6 and double precision operations add.d $f2,$f4,$f6 #$f2||$f3 = $f4||$f5 + $f6||$f7 similarly for sub.s, sub.d, mul.s, mul.d, div.s, div.d From/To coprocessor 1
 (whose registers are used in pairs for double precision values) with special instructions to load to and store from them. lwcl $f0,54($s2) #$f0 = Memory[$s2+54] swcl $f0,58($s4) #Memory[$s4+58] = $f0. And supports IEEE 754 single. add.s $f2,$f4,$f6 #$f2 = $f4 + $f6. and double precision operations. add.d $f2,$f4,$f6 #$f2||$f3 = $f4||$f5 + $f6||$f7. similarly for sub.s, sub.d, mul.s, mul.d, div.s, div.d. From/To coprocessor 1.")
47
MIPS Floating Point Instructions, Con’t
And floating point single precision comparison operations c.lt.s $f2,$f4 #if($f2 < $f4) cond=1; else cond=0 where lt may be replaced with eq, neq, le, gt, ge and branch operations bclt #if(cond==1) go to PC+4+100 bclf #if(cond==0) go to PC+4+100 And double precision comparison operations c.lt.d $f2,$f #$f2||$f3 < $f4||$f cond=1; else cond=0
 cond=1; else cond=0. where lt may be replaced with eq, neq, le, gt, ge. and branch operations. bclt 25 #if(cond==1) go to PC bclf 25 #if(cond==0) go to PC And double precision comparison operations. c.lt.d $f2,$f4 #$f2||$f3 < $f4||$f5 cond=1; else cond=0.")
48
MIPS FP Multiplication
(頁203) Fig. 3.18
 Fig")
49
p.260(頁265) Fig. 3.18 #$f2||$f3 =$f4||$f5 + $f6||$f7
 Fig #$f2||$f3 =$f4||$f5 + $f6||$f7")
50
p. 260(頁265) Fig. 3.18
 Fig. 3.18")
51
FlPt p. 260(頁265) Fig. 3.18
 Fig. 3.18")
52
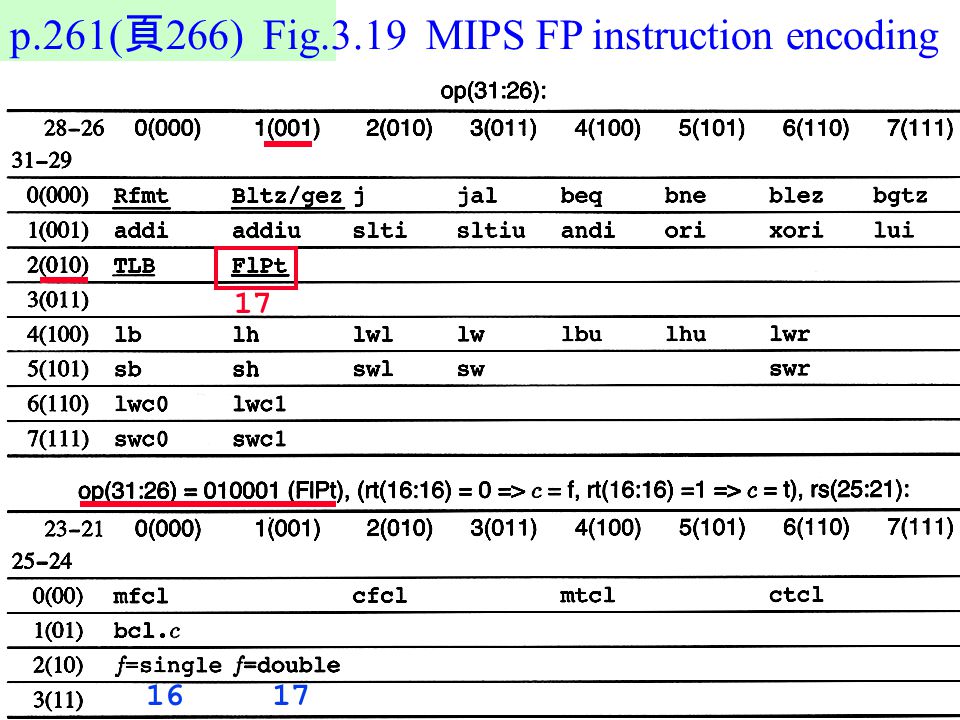
p.261(頁266) Fig.3.19 MIPS FP instruction encoding
17 16 17
53
p.261(頁266) Fig.3.19 MIPS FP instruction encoding
16 17

54
p. 221(頁219) 3.6 Fallacies
 3.6 Fallacies")
55
3.6 FP add, subtract associative?
Parallel programs may interleave operations in unexpected orders Assumptions of associativity may fail Need to validate parallel programs under varying degrees of parallelism

56
x86 FP Architecture Originally based on 8087 FP coprocessor 8 × 80-bit extended-precision registers Used as a push-down stack Registers indexed from TOS: ST(0), ST(1), … FP values are 32-bit or 64 in memory Converted on load/store of memory operand Integer operands can also be converted on load/store Very difficult to generate and optimize code Result: poor FP performance
, ST(1), … FP values are 32-bit or 64 in memory. Converted on load/store of memory operand. Integer operands can also be converted on load/store. Very difficult to generate and optimize code. Result: poor FP performance.")
57
Streaming SIMD Extension 2 (SSE2)
Adds 4 × 128-bit registers Extended to 8 registers in AMD64/EM64T Can be used for multiple FP operands 2 × 64-bit double precision 4 × 32-bit double precision Instructions operate on them simultaneously Single-Instruction Multiple-Data

58
Streaming SIMD Extensions
In computing, Streaming SIMD Extensions (SSE) is a SIMD instruction set extension to the x86 architecture, designed by Intel and introduced in 1999 in their Pentium III series processors as a reply to AMD's 3DNow! (which had debuted a year earlier). SSE contains 70 new instructions. SSE originally added eight new 128-bit registers known as XMM0 through XMM7. The AMD64 extensions from AMD (originally called x86-64 and later duplicated by Intel) add a further eight registers XMM8 through XMM15. SSE2, introduced with the Pentium 4, is a major enhancement to SSE. SSE2 adds new math instructions for double-precision (64-bit) floating point and also extends MMX instructions to operate on 128- bit XMM registers. SSE3, is an incremental upgrade to SSE2, adding a handful of DSP- oriented mathematics instructions and some process (thread) management instructions. SSE4 is another major enhancement, adding a dot product instruction, additional integer instructions, a popcnt instruction, and more.
 is a SIMD instruction set extension to the x86 architecture, designed by Intel and introduced in 1999 in their Pentium III series processors as a reply to AMD s 3DNow! (which had debuted a year earlier). SSE contains 70 new instructions. SSE originally added eight new 128-bit registers known as XMM0 through XMM7. The AMD64 extensions from AMD (originally called x86-64 and later duplicated by Intel) add a further eight registers XMM8 through XMM15. SSE2, introduced with the Pentium 4, is a major enhancement to SSE. SSE2 adds new math instructions for double-precision (64-bit) floating point and also extends MMX instructions to operate on 128- bit XMM registers. SSE3, is an incremental upgrade to SSE2, adding a handful of DSP- oriented mathematics instructions and some process (thread) management instructions. SSE4 is another major enhancement, adding a dot product instruction, additional integer instructions, a popcnt instruction, and more.")
59
Right Shift and Division
Left shift by i places multiplies an integer by 2i Right shift divides by 2i? Only for unsigned integers For signed integers Arithmetic right shift: replicate the sign bit e.g., –5 / 4 >> 2 = = –2 Rounds toward –∞ c.f >>> 2 = = +62 §3.8 Fallacies and Pitfalls

60
Who Cares About FP Accuracy?
Important for scientific code But for everyday consumer use? “My bank balance is out by ¢!” The Intel Pentium FDIV bug The market expects accuracy See Colwell, The Pentium Chronicles

61
Concluding Remarks ISAs support arithmetic Bounded range and precision
Signed and unsigned integers Floating-point approximation to reals Bounded range and precision Operations can overflow and underflow MIPS ISA Core instructions: 54 most frequently used 100% of SPECINT, 97% of SPECFP Other instructions: less frequent §3.9 Concluding Remarks

62
Summary Questions? Exercises: 3.2.1, 3.2.2, 3.3.1 , 3.3.2 , 3.3.3
3.2.1, , , , 3.10.1, , , Midterm Exam. 2012/04/18 (Wed.) 15:30-16:50 管理大樓地下一樓舊國際會議廳M001 (對號入座) Chapter 1 ~ Chapter 3 閉書考 分題目卷與答案卷(寫入答案卷才計分, 題號請標明) Thank you!
 15:30-16:50. 管理大樓地下一樓舊國際會議廳M001 (對號入座) Chapter 1 ~ Chapter 3. 閉書考. 分題目卷與答案卷(寫入答案卷才計分, 題號請標明) Thank you!")
63
Summary Questions? Exercises: 3.2.1, , , , 3.10.1, , ,

64
期中考(Midterm Exam) 2014/11/24 週一(Mon.) 早上上課時間 資訊大樓三樓上課教室I311 (對號入座)
Chapter 1 ~ Chapter 3 (closed book) 分題目卷與答案卷 (寫入答案卷才計分, 題號請標明) 考試時間: 80分鐘 64
 分題目卷與答案卷 (寫入答案卷才計分, 題號請標明) 考試時間: 80分鐘. 64.")
65
Midterm Exam 2013/11/06 (Wed.) 15:30-16:50訓輔時間 管理大樓地下一樓舊會議廳M001 (對號入座)
Chapter 1 ~ Chapter 3 (closed book) 分題目卷與答案卷 (寫入答案卷才計分, 題號請標明) 65
 分題目卷與答案卷 (寫入答案卷才計分, 題號請標明) 65.")
Similar presentations

Project 1 Discussion? 1)HW 2 Discussion? 2)We want to get some feel for programming in an assembly language - MIPS 32 We want to fully understand.>")
www.cse.psu.edu/~mji.>")





 –Abstractions: Instruction Set Architecture.>")









 –Abstractions: Instruction Set Architecture Assembly Language and.>")
