Download presentation
Presentation is loading. Please wait.

1
RISC and Pipelining Prof. Sin-Min Lee Department of Computer Science

2
The Basis for RISC Use of simple instructions One of their key realizations was that a sequence of simple instructions produces the same results as a sequence of complex instructions, but can be implemented with a simpler (and faster) hardware design. Reduced Instruction Set Computers---RISC machines---were the result.

3
RISC characteristics Simple instruction set. In a RISC machine, the instruction set contains simple, basic instructions, from which more complex instructions can be composed. Same length instructions.

8
Each instruction is the same length, so that it may be fetched in a single operation. 1 machine-cycle instructions. Most instructions complete in one machine cycle, which allows the processor to handle several instructions at the same time. This pipelining is a key technique used to speed up RISC machines.

9
Instructions Pipelines It is to prepare the next instruction while the current instruction is still executing. A Three states RISC pipelines is : 1.Fetch instruction 2.Decode and select registers 3.Execute the instruction Clock Stage 1234567 1i1i2i3i4i5i6i7 2-i1i2i3i4i5i6 3--i1i2i3i4i5

10
Instruction Pipelines Conflicts It divided into two categories. –Data Conflicts –Branch Conflicts When the current instruction changes a register that the next one needed, data conflicts happens. When the current instruction make a jump, branch conflicts happens.

11
Data Conflicts To show this conflicts, consider the following code 1.R1 <- R2 + R3 2.R4 <- R1 + R3 3.R5 <- R1 + R3 The first instruction change the register that the second needed. However, the second instruction have already fetch the values in R1 and R3. Therefore, incorrect result will be returned.

12
Solution for the Data Conflicts Compiler Level Solve by No-op –We can add No-op statements between 1 and 2 Instruction reordering –Reordering it so 3 is fetch before 2 Hardware Level Stall insertion –Same as No-op but Stall are inserted by the hardware Data forwarding –Calculated result are forwarded to stage2

13
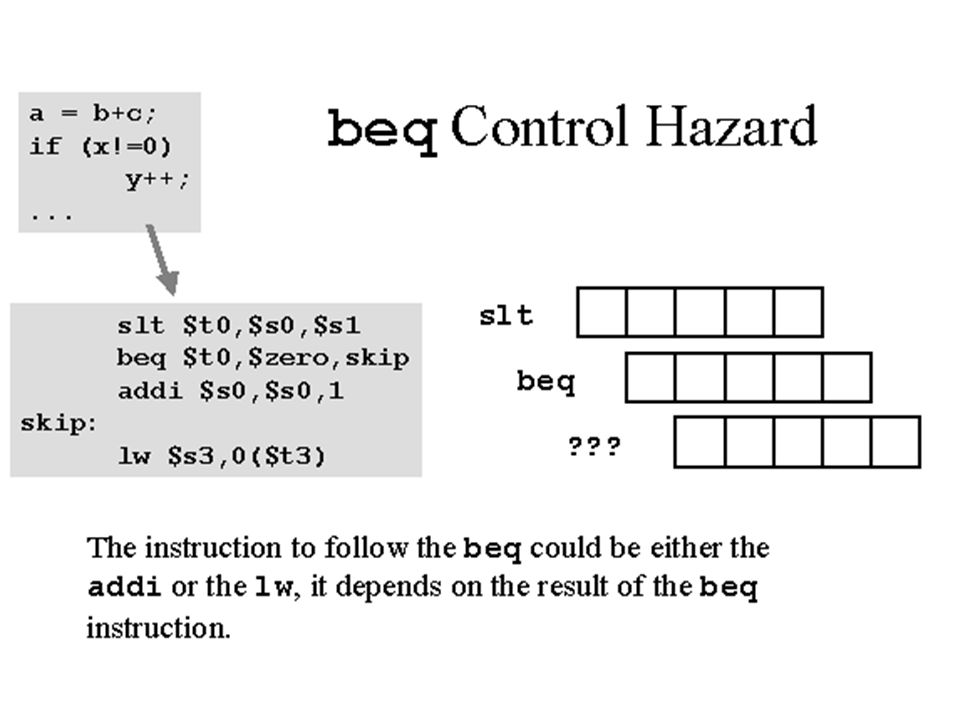
Branch Conflicts Consider the code: 1.R1 <- R2 + R3 2.R4 <- R5 + R6 3.JUMP 10 4.R7 <- R8 +R9. 10.R13 <- R14 + R15 The codes 4 and 5 have been fetched before the jump made so illegal changes may made.

14
Solution for the Branch Conflicts Compiler Level Solve by No-op –We can add No-op statements between 2 and 3 Instruction reordering –Reordering it so 3 is fetch first and then do 1 and 2 Hardware Level Annulling –Do the instruction but don’t save any changes Branch prediction –Predict the result and fetch the assumed code. If the prediction are true, then save changes or annuls it

15
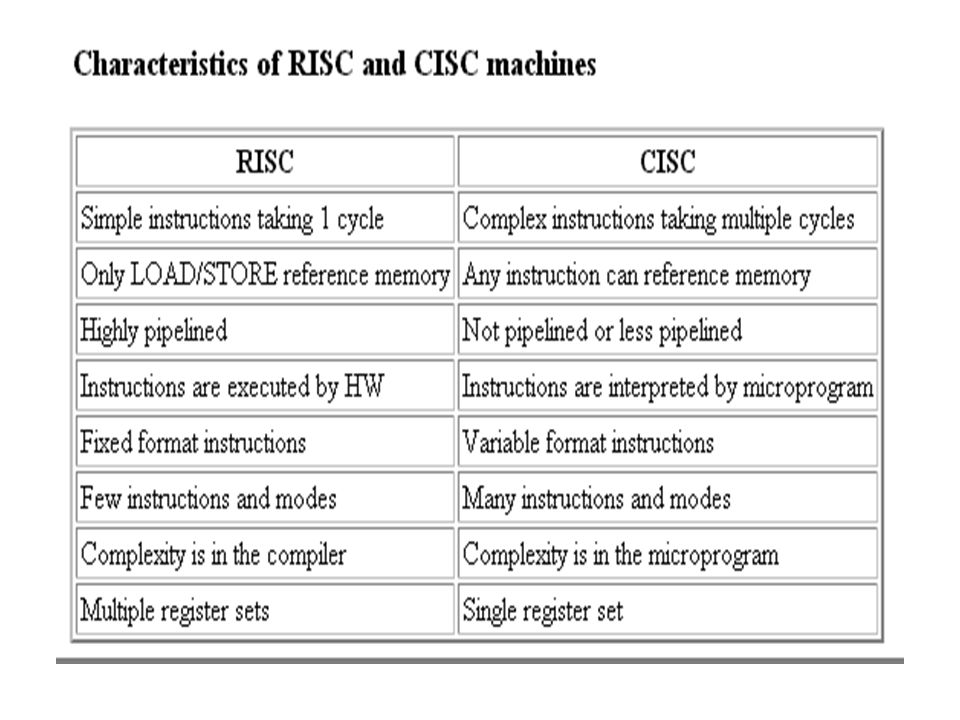
RISC vs. CISC RISC have fewer and simpler instructions, therefore, they are less complex and easier to design. Also, it allow higher clock speed than CISC. However, When we compiled high-level language. RISC CPU need more instructions than CISC CPU. CISC are complex but it doesn’t necessarily increase the cost. CISC processors are backward compactable.

16
Why RISC is better The 80/20 rule: Analysis of the instruction mix generated by CISC compilers, shows that more than 80% of the instructions generated and executed used only 20% of an instruction set. It was an obvious conclusion that if this 20% of instruction was speeded up, the performance benefits would be far greater. Further analysis shows that these instructions tend to perform the simpler operations and use only the simpler addressing modes. For the CISC machine, all the effort invested in processor design to provide complex instructions and thereby reduce the compiler workload was being wasted..

17
Less cost: Since only the simpler instructions are needed, the processor hardware required to implement them could be reduced in complexity. Therefor it should be possible to design a more performance processor with less cost. Good performance: With a simpler instruction set, it should possible for a processor to execute its instruction in a single clock cycle. Higher performance can be achieved.

18
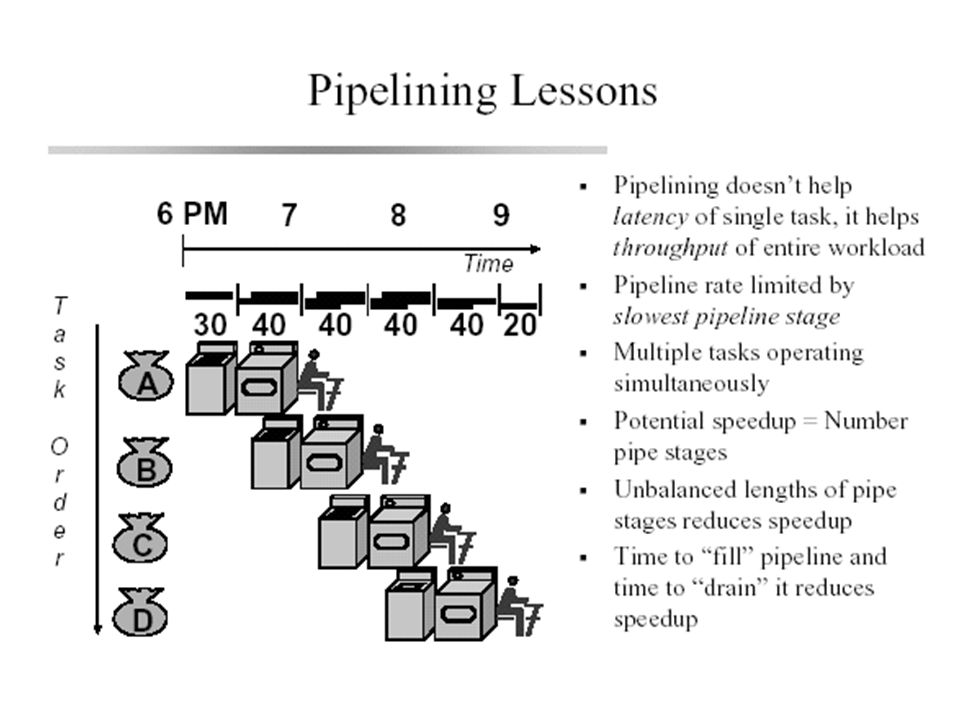
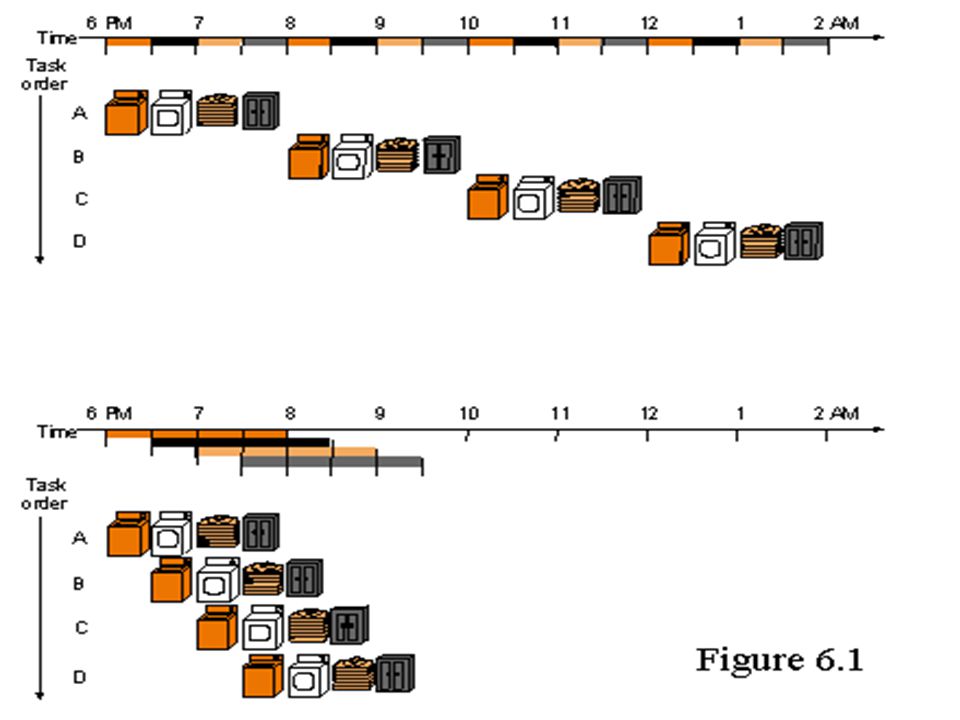
Pipelining: A key RISC technique RISC designers are concerned primarily with creating the fastest chip possible, and so they use a number of techniques, including pipelining. Pipelining is a design technique where the computer's hardware processes more than one instruction at a time, and doesn't wait for one instruction to complete before starting the next.

19
The advantages of RISC Implementing a processor with a simplified instruction set design provides several advantages over implementing a comparable CISC design: (1) Speed. Since a simplified instruction set allows for a pipelined, superscalar design RISC processors often achieve 2 to 4 times the performance of CISC processors using comparable semiconductor technology and the same clock rates. (2) Simpler hardware. Because the instruction set of a RISC processor is so simple, it uses up much less chip space; extra functions, such as memory management units or floating point arithmetic units, can also be placed on the same chip. Smaller chips allow a semconductor manufacturer to place more parts on a single silicon wafer, which can lower the per-chip cost dramatically. (3) Shorter design cycle. Since RISC processors are simpler than corresponding CISC processors, they can be designed more quickly, and can take advantage of other technological developments sooner than corresponding CISC designs, leading to greater leaps in performance between generations.
 Simpler hardware. Because the instruction set of a RISC processor is so simple, it uses up much less chip space; extra functions, such as memory management units or floating point arithmetic units, can also be placed on the same chip. Smaller chips allow a semconductor manufacturer to place more parts on a single silicon wafer, which can lower the per-chip cost dramatically. (3) Shorter design cycle. Since RISC processors are simpler than corresponding CISC processors, they can be designed more quickly, and can take advantage of other technological developments sooner than corresponding CISC designs, leading to greater leaps in performance between generations..")
20
Early RISC Machines IBM 801 1980 120 instructions No microcode 32 bit instructions MSI technology Berkeley RISC Coined RISC and CISC Promoted architecture and implementation innovations as RISC Single VLSI chip implementation Stanford MIPS Concentrated on compiler technology to improve system performance

21
IBM 801 Put in hardware what Could not be moved to compile time Could not be efficiently implemented in executable code by a compiler Could be implemented as random logic Architecture 32 32 bit registers Separate data and instruction caches Two stage pipeline, decode-operand fetch-execute, shift-set conditions-write Delayed branches, Branch with execute Compilers No intent on letting end users program in assembly

22
Berkeley RISC Unlike IBM 801 No heavy reliance on compiler technology Single chip implementation Argues that RISC is the best way to use scarce silicon area Influential because Introduced RISC and CISC terms First single chip RISC processor Introduced several innovations at once Great marketing job

23
Current RISC RISC -> SPARC MIPS -> MIPS R[2-4]000 IBM 801 -> IBM RT -> IBM RS/6000 HP-PA RISC ARM M88000 PowerPC i860 I960
![Current RISC RISC -> SPARC MIPS -> MIPS R[2-4]000 IBM 801 -> IBM RT -> IBM RS/6000 HP-PA RISC ARM M88000 PowerPC i860 I960](http://images.slideplayer.com/11/3334348/slides/slide_23.jpg "Current RISC RISC -> SPARC MIPS -> MIPS R[2-4]000 IBM 801 -> IBM RT -> IBM RS/6000 HP-PA RISC ARM M88000 PowerPC i860 I960")
34
11.3.1 Instruction Pipeline An instruction pipeline is very similar to a manufacturing assembly line. Imagine an assembly line partitioned into four stages: 1st stage receives some parts, performs its assembly task, and passes the results to the second stage; 2nd stage takes the partially assembled product from the first stage, performs its task, and passes its work to the third stage; 3rd stage does its work, passing the results to the last stage, which completes the task and outputs its results.

35
As the first piece moves from the first stage to the second stage, a new set of parts for a new piece enters the first stage. Ultimately, every stage processes a piece simultaneously. This is how time is saved. Each product requires the same amount of time to be processed (actually slightly more, to account for the transfers between stages), but products are manufactured more quickly because several are being created at the same time.
, but products are manufactured more quickly because several are being created at the same time..")
36
An instruction pipeline processes an instruction the way the assembly line processes a product. 1st stage: fetches the instruction from memory. 2nd stage: decodes the instruction and fetches any required operands. 3rd stage: executes the instruction, 4th stage: stores the result.

37
Consider a nonpipelined machine with 6 execution stages of lengths 50 ns, 50 ns, 60 ns, 60 ns, 50 ns, and 50 ns. - Find the instruction latency on this machine. - How much time does it take to execute 100 instructions? Instruction latency = 50+50+60+60+50+50= 320 ns Time to execute 100 instructions = 100*320 = 32000 ns

38
Suppose we introduce pipelining on this machine. Assume that when introducing pipelining, the clock skew adds 5ns of overhead to each execution stage. - What is the instruction latency on the pipelined machine? - How much time does it take to execute 100 instructions? Solution: Remember that in the pipelined implementation, the length of the pipe stages must all be the same, i.e., the speed of the slowest stage plus overhead. With 5ns overhead it comes to:

39
The length of pipelined stage = MAX(lengths of unpipelined stages) + overhead = 60 + 5 = 65 ns Instruction latency = 6x65 ns =390ns Time to execute 100 instructions = 65*6*1 + 65*1*99 = 390 + 6435 = 6825 ns
 + overhead = = 65 ns Instruction latency = 6x65 ns =390ns Time to execute 100 instructions = 65*6*1 + 65*1*99 = = 6825 ns")
40
Instructions Pipelines It is to prepare the next instruction while the current instruction is still executing. A Three states RISC pipelines is : 1.Fetch instruction 2.Decode and select registers 3.Execute the instruction Clock Stage 1234567 1i1i2i3i4i5i6i7 2-i1i2i3i4i5i6 3--i1i2i3i4i5

41
What is the speedup obtained from pipelining? Solution: Speedup is the ratio of the average instruction time without pipelining to the average instruction time with pipelining. Average instruction time not pipelined = 320 ns Average instruction time pipelined = 65 ns Speedup = 320 / 65 = 4.92

42
Each instruction is the same length, so that it may be fetched in a single operation. 1 machine-cycle instructions. Most instructions complete in one machine cycle, which allows the processor to handle several instructions at the same time. This pipelining is a key technique used to speed up RISC machines.

58
Instruction Pipelines Conflicts It divided into two categories. –Data Conflicts –Branch Conflicts When the current instruction changes a register that the next one needed, data conflicts happens. When the current instruction make a jump, branch conflicts happens.

59
Data Conflicts To show this conflicts, consider the following code 1.R1 <- R2 + R3 2.R4 <- R1 + R3 3.R5 <- R1 + R3 The first instruction change the register that the second needed. However, the second instruction have already fetch the values in R1 and R3. Therefore, incorrect result will be returned.

60
Solution for the Data Conflicts Compiler Level Solve by No-op –We can add No-op statements between 1 and 2 Instruction reordering –Reordering it so 3 is fetch before 2 Hardware Level Stall insertion –Same as No-op but Stall are inserted by the hardware Data forwarding –Calculated result are forwarded to stage2

61
Branch Conflicts Consider the code: 1.R1 <- R2 + R3 2.R4 <- R5 + R6 3.JUMP 10 4.R7 <- R8 +R9. 10.R13 <- R14 + R15 The codes 4 and 5 have been fetched before the jump made so illegal changes may made.

62
Solution for the Branch Conflicts Compiler Level Solve by No-op –We can add No-op statements between 2 and 3 Instruction reordering –Reordering it so 3 is fetch first and then do 1 and 2 Hardware Level Annulling –Do the instruction but don’t save any changes Branch prediction –Predict the result and fetch the assumed code. If the prediction are true, then save changes or annuls it

76
This is one possible configuration of an RISC pipeline, the pipeline implemented in the SPARC MB86900 CPU. The IBM 801, the first RISC computer, also uses a four- stage instruction pipeline. Other processors, such as the RISC II, use only three stages; they combine the execute and store result operations in to a single stage.

77
The MIPS processor uses a five-stage pipeline; it decodes the instruction and selects the operand registers in separate stages. These three configurations are shown in the following figure.

78
Note that each stage has a register that latches its data at the end of the stage to synchronize data flow between stages. The flow of instructions through each pipeline is shown in the following Figure.

80
A Single Pipelined Control Unit Offers Several Advantage: The primary advantage is the reduced hardware requirements of the pipeline. A second advantage of instruction pipelines is the reduced complexity of the memory interface.

Similar presentations



















































 Colin Stevens.>")
 CS 147 Li-Chuan Fang.>")





