Download presentation
Presentation is loading. Please wait.

1
Why are phoneme frequency distributions skewed? Andy Martin Laboratoire de Sciences Cognitives et Psycholinguistique (EHESS, DEC-ENS, CNRS), Paris
, Paris.")
2
Phoneme frequencies within a language are power- law distributed (Tambovtsev and Martindale 2007) Data: Baayen et al. 1995
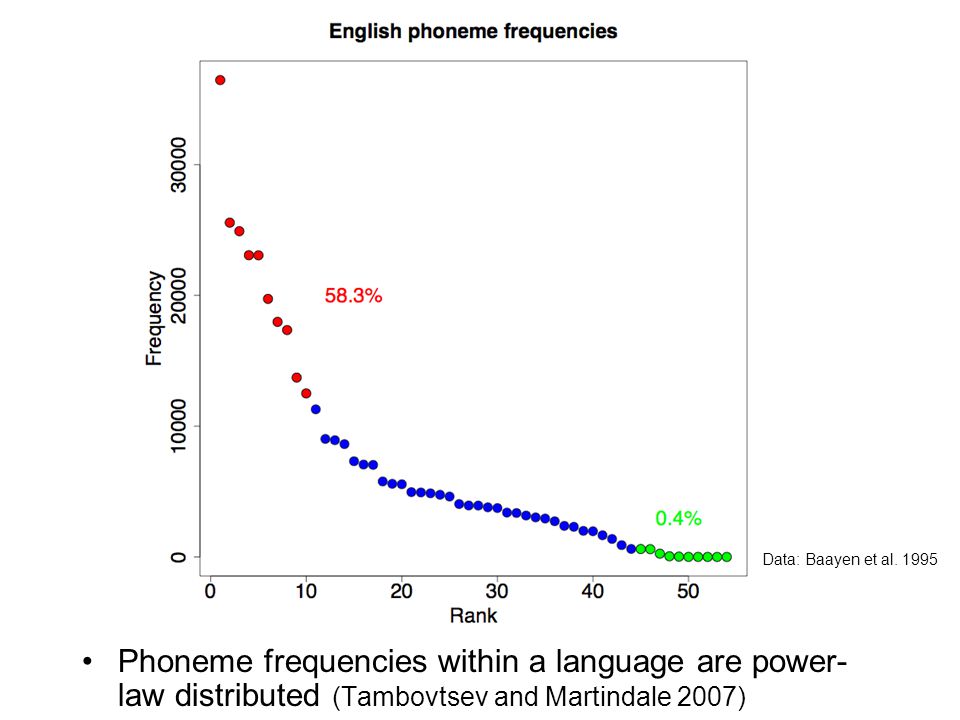
3
Power laws Definition: A phoneme’s frequency is proportional to Movie actor collaborations (Barabási and Albert 1999) Income distribution (Lorenz 1905) City sizes (Zipf 1949) Word frequencies (Zipf 1935)
 Income distribution (Lorenz 1905) City sizes (Zipf 1949) Word frequencies (Zipf 1935)")
4
Preferential attachment Where do power law distributions come from? Simon (1955), Barabási and Albert (1999) Emerge in networks with two ingredients: –Growth –Preferential attachment “Rich-get-richer” systems
, Barabási and Albert (1999) Emerge in networks with two ingredients: –Growth –Preferential attachment Rich-get-richer systems.")
5
NetLogo demonstration (Wilensky 2005)
")
6
The proposal New words tend to contain frequent phonemes, making them even more frequent Goal of this talk: derive this fact from an existing model of speech production Growth: new words entering the language Preferential attachment: new words tend to contain common phonemes Preferential attachment can be modeled using a spreading activation model of speech production

7
The evolving lexicon A speech community tends to converge on a single alternative when confronted with multiple synonyms (Lass 1997, Croft 2000, Baronchelli et al. 2006) Words compete to enter the lexicon The lexicon is composed of the winners of these competitions Properties that contribute to winning will increase in frequency (Boersma 1998, 2007) Lexical competition can be modeled as a race between two lexical entries in a speech production network
 Words compete to enter the lexicon The lexicon is composed of the winners of these competitions Properties that contribute to winning will increase in frequency (Boersma 1998, 2007) Lexical competition can be modeled as a race between two lexical entries in a speech production network.")
8
Spreading activation network (Dell 1986) dagkætr kæt
 dagkætr kæt")
9
Adding feedback dagkætr kæ t

10
Competing synonyms k aʊaʊʧ əs oʊoʊ f

11
Competing synonyms Evidence for the simultaneous activation of synonyms comes from speech errors Blending errors typically formed from synonyms (Wells 1951, Fromkin 1971, Poulisse 1999) frown + scowl frowl These could result from cases in which both lexical entries are equally active
 frown + scowl frowl These could result from cases in which both lexical entries are equally active")
12
Phoneme frequency effects (Dell & Gordon 2003) P1P2 P2 P2 P1 P1
 P1P2 P2 P2 P1 P1")
13
Simulation Toy language: 10 phonemes Lexicon: 50 words, each 5 phonemes long Initial state: words contain random phonemes drawn from a uniform distribution Implemented in a speech production network Each “generation,” a competing synonym is introduced for each word in the lexicon Phonemes are always equiprobable in new words The lexical entry with the highest activation after 5 time steps is the winner The loser is eliminated from the lexicon

14
Simulation network agabj abcdefghij concept cdcdc concept cijhh concept agiij concept bjgge concept accjh concept fjbhb concept iifcc concept jghhe concept iifccjghhe

15
Simulation Activation at each time step is determined with the following equation (Dell 1986) : Skewness of the phoneme distribution in each generation is measured using Shannon entropy: Low entropy = more skewed
 : Skewness of the phoneme distribution in each generation is measured using Shannon entropy: Low entropy = more skewed")
16
Simulation results

18
The single-phoneme problem The simulation approaches a state in which there is only one phoneme One solution: a teleological pressure away from inventories with few phonemes Another solution: give some words with low- frequency phonemes an advantage Some non-phonological factors (e.g., sociolinguistic) surely contribute to word usage Implemented in simulation as a weight assigned to each lexical node, which affects the probability of winning a production competition
 surely contribute to word usage Implemented in simulation as a weight assigned to each lexical node, which affects the probability of winning a production competition")
19
Non-phonological factors Weights are drawn randomly from a Gaussian distribution with mean 1 and standard deviation of δ A word’s weight does not change over the course of the simulation Revised update algorithm: Higher weight = more activation

20
Results

21
What about markedness? The most frequent phonemes tend to be similar across languages (e.g., coronal consonants) Giving phoneme nodes differing weights creates skewed distributions, but power laws result only if the weights are themselves power-law distributed In my account, the nature of the distribution emerges as a natural consequence of the architecture of the model
 Giving phoneme nodes differing weights creates skewed distributions, but power laws result only if the weights are themselves power-law distributed In my account, the nature of the distribution emerges as a natural consequence of the architecture of the model.")
22
Conclusions Phoneme frequency distributions are heavily skewed This is a consequence of a feedback loop: new words tend to contain frequent sounds, making those sounds even more frequent The feedback loop emerges from a spreading activation model of speech production in which words compete to be used Differing degrees of skew can be modeled by incorporating non-phonological factors into the model

23
Thank you Andy Martin amartin@humnet.ucla.edu

24
References 1 Barabási, Albert-László and Réka Albert. 1999. Emergence of Scaling in Random Networks. Science 286: 509–512. Baronchelli, Andrea, Maddalena Felici, Vittorio Loreto, Emanuele Caglioti and Luc Steels. 2006. Journal of Statistical Mechanics: Theory and Experiment. Boersma, Paul. 1998. Functional phonology: Formalizing the interactions between articulatory and perceptual drives. The Hague: Holland Academic Graphics. Boersma, Paul. 2007. The evolution of phonotactic distributions in the lexicon. Talk given at the Presentation Workshop on Variation, Gradience and Frequency in Phonology, Stanford University. Croft, William. 2000. Explaining Language Change: An evolutionary approach. Harlow, Essex: Longman. Dell, Gary. 1986. A spreading-activation theory of retrieval in sentence production. Psychological Review 93: 283–321.

25
References 2 Dell, Gary and Jean Gordon. 2003. Neighbors in the lexicon: Friends or foes? In N. O. Schiller & A. S. Meyer (eds.), Phonetics and phonology in language comprehension and production: Differences and similarities. Berlin: Mouton de Gruyter. Fromkin, Victoria. 1971. The Non-anomalous Nature of Anomalous Utterances. Language 47(1): 27–52. Lass, Roger. 1997. Historical Linguistics and Language Change. Cambridge: Cambridge University Press. Poulisse, Nanda. 1999. Slips of the Tongue: Speech Errors in First and Second Language Production. Amsterdam and Philadelphia: John Benjamins. Tambovtsev, Yuri and Colin Martindale. 2007. Phoneme Frequencies Follow a Yule Distribution. SKASE Journal of Theoretical Linguistics 4: 2. Wells, R. 1951. Predicting Slips of the Tongue. Yale Scientific Magazine, December. 9–12.
, Phonetics and phonology in language comprehension and production: Differences and similarities. Berlin: Mouton de Gruyter. Fromkin, Victoria The Non-anomalous Nature of Anomalous Utterances. Language 47(1): 27–52. Lass, Roger Historical Linguistics and Language Change. Cambridge: Cambridge University Press. Poulisse, Nanda Slips of the Tongue: Speech Errors in First and Second Language Production. Amsterdam and Philadelphia: John Benjamins. Tambovtsev, Yuri and Colin Martindale Phoneme Frequencies Follow a Yule Distribution. SKASE Journal of Theoretical Linguistics 4: 2. Wells, R Predicting Slips of the Tongue. Yale Scientific Magazine, December. 9–12..")
26
References 3 Wilensky, Uri. 2005. NetLogo Preferential Attachment model. http://ccl.northwestern.edu/netlogo/models/PreferentialAttachment. Center for Connected Learning and Computer-Based Modeling, Northwestern University, Evanston, IL. http://ccl.northwestern.edu/netlogo/models/PreferentialAttachment Zipf, George. 1935. The Psycho-biology of Language. Boston: Houghton Mifflin. Zipf, George. 1949. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology. Addison-Wesley Press.

Similar presentations


>")









>")







