Download presentation
Presentation is loading. Please wait.

1
UNIT-II CENTRAL PROCESSING UNIT
INTODUCTION ARITHMETIC LOGIC UNIT FIXED POINT ARITHMETIC FLOATING POINT ARITHMETIC EXECUTION OF A COMPLETE INSTRUCTION BASIC CONCEPTS OF PIPELINING

2
The arithmetic logic unit (ALU)
The central processing unit (CPU) performs operations on data. In most architectures it has three parts: an arithmetic logic unit (ALU), a control unit and a set of registers, fast storage locations (Figure ). Figure Central processing unit (CPU)
 performs operations on data. In most architectures it has three parts: an arithmetic logic unit (ALU), a control unit and a set of registers, fast storage locations (Figure ). Figure Central processing unit (CPU)")
3
Data Representation The basic form of information handled by a computer are instructions and data Data can be in the form of numbers or nonnumeric data Data in the number form can further classified as fixed point and floating point

4
Digit Sets and Encodings
Conventional and unconventional digit sets Decimal digits in [0, 9]; 4-bit BCD, 8-bit ASCII Hexadecimal, or hex for short: digits 0-9 & a-f Conventional digit set for radix r is [0, r – 1] Conventional binary digit set in [0, 1]

5
Positional Number Systems
Representations of natural numbers {0, 1, 2, 3, …} ||||| ||||| ||||| ||||| ||||| || sticks or unary code 27 radix-10 or decimal code radix-2 or binary code XXVII Roman numerals Fixed-radix positional representation with k digits Value of a number: x = (xk–1xk– x1x0)r = S xi r i For example: 27 = (11011)two = (124) + (123) + (022) + (121) + (120) k–1 i=0
r = S xi r i. For example: 27 = (11011)two = (124) + (123) + (022) + (121) + (120) k–1. i=0.")
6
Fixed Point Representation
Fixed point number actually symbolizes the real data types. As radix point is fixed ,the number system is fixed point number system Fixed point numbers are those which have a defined numbers after and before the decimal point.

7
Fixed-Point Numbers Positional representation: k whole and l fractional digits Value of a number: x = (xk–1xk– x1x0 . x–1x– x–l )r = S xi r i For example: 2.375 = (10.011)two = (121) + (020) + (02-1) + (12-2) + (12-3) Numbers in the range [0, rk – ulp] representable, where ulp = r –l Fixed-point arithmetic same as integer arithmetic (radix point implied, not explicit) Two’s complement properties (including sign change) hold here as well: (01.011)2’s-compl = (–021) + (120) + (02–1) + (12–2) + (12–3) = (11.011)2’s-compl = (–121) + (120) + (02–1) + (12–2) + (12–3) = –0.625
r = S xi r i. For example: = (10.011)two = (121) + (020) + (02-1) + (12-2) + (12-3) Numbers in the range [0, rk – ulp] representable, where ulp = r –l. Fixed-point arithmetic same as integer arithmetic. (radix point implied, not explicit) Two’s complement properties (including sign change) hold here as well: (01.011)2’s-compl = (–021) + (120) + (02–1) + (12–2) + (12–3) = (11.011)2’s-compl = (–121) + (120) + (02–1) + (12–2) + (12–3) = –")
8
Unsigned Integer Unsigned integers represent positive numbers
The decimal range of unsigned 8-bit binary numbers is

9
Unsigned Binary Integers
Schematic representation of 4-bit code for integers in [0, 15].

10
Signed Integers We dealt with representing the natural numbers
Signed or directed whole numbers = integers { , -3, -2, -1, 0, 1, 2, 3, } Signed magnitude for 8 bit numbers ranges from +127 to -127 Signed-magnitude representation +27 in 8-bit signed-magnitude binary code –27 in 8-bit signed-magnitude binary code –27 in 2-digit decimal code with BCD digits

11
Introduction to Fixed Point Arithmetic
Using fixed point numbers to simulate floating point numbers Fixed point processor is usually cheaper

12
Addition

13
Subtraction

14
A Serial Multiplier

15
Example of Multiplication Using Serial Multiplier

16
Serial Divider

17
Division Example Using Serial Divider

18
Floating-Point Numbers
To accommodate very large integers and very small fractions, a computer must be able to represent numbers and operate on them in such a way that the position of the binary point is variable and is automatically adjusted as computation proceeds. Floating-point representation is like scientific notation: = -2 = 7 10–9 Significand Exponent Exponent base Also, 7E-9

19
Floating-point Computations
Representation: (fraction, exponent) Has three fields: sign, significant digits and exponent eg *25 Value representation = +/- M*2 E’-127 In case of a 32 bit number 1 bit represents sign 8 bits represents exponent E’=E +127(bias) [ excess 127 format] 23 bits represents Mantissa
 Has three fields: sign, significant digits and exponent. eg *25. Value representation = +/- M*2 E’-127. In case of a 32 bit number 1 bit represents sign. 8 bits represents exponent E’=E +127(bias) [ excess 127 format] 23 bits represents Mantissa.")
20
Floating-point Computations
Arithmetic operations x 102 x 102 x 102 x 105 x 105 x 105 x 103 x 102 x 10-1 x 102 x x 10-1 Addition

21
Floating-point Computations
Biased Exponent Bias: an excess number added to the exponent so that all exponents become positive Advantages Only positive exponents Simpler to compare the relative magnitude

22
Floating-point Computations
Standard Operand Format of floating-point numbers Single-precision data type: 32bits ADDFS Double-precision data type: 64bits ADDFL IEEE Floating-Point Operand Format

23
Floating-point Computations
Significand A leading bit to the left of the implied binary point, together with the fraction in the field f field Significand Decimal Equivalent 100… …0 1.50 010… …0 1.25 000… …0 1.00 s ~ ~ Minimum number Maximum number

24
ANSI/IEEE Standard Floating-Point Format (IEEE 754)
Revision (IEEE 754R) is being considered by a committee Short exponent range is –127 to 128 but the two extreme values are reserved for special operands (similarly for the long format) The two ANSI/IEEE standard floating-point formats.
 is being considered by a committee. Short exponent range is –127 to 128. but the two extreme values. are reserved for special operands. (similarly for the long format) The two ANSI/IEEE standard floating-point formats.")
25
Short and Long IEEE 754 Formats: Features
Table Some features of ANSI/IEEE standard floating-point formats Feature Single/Short Double/Long Word width in bits 32 64 Significand in bits hidden hidden Significand range [1, 2 – 2–23] [1, 2 – 2–52] Exponent bits 8 11 Exponent bias 127 1023 Zero (±0) e + bias = 0, f = 0 Denormal e + bias = 0, f ≠ 0 represents ±0.f 2–126 represents ±0.f 2–1022 Infinity (∞) e + bias = 255, f = 0 e + bias = 2047, f = 0 Not-a-number (NaN) e + bias = 255, f ≠ 0 e + bias = 2047, f ≠ 0 Ordinary number e + bias [1, 254] e [–126, 127] represents 1.f 2e e + bias [1, 2046] e [–1022, 1023] min 2–126 1.2 10–38 2–1022 2.2 10–308 max 2128 3.4 1038 1.8 10308
 e + bias = 0, f = 0. Denormal. e + bias = 0, f ≠ 0. represents ±0.f 2–126. represents ±0.f 2–1022. Infinity (∞) e + bias = 255, f = 0. e + bias = 2047, f = 0. Not-a-number (NaN) e + bias = 255, f ≠ 0. e + bias = 2047, f ≠ 0. Ordinary number. e + bias [1, 254] e [–126, 127] represents 1.f 2e. e + bias [1, 2046] e [–1022, 1023] min. 2–126 1.2 10–38. 2–1022 2.2 10–308. max. 2128 3.4 1.8 ")
26
Floating Point Arithmetic
• Floating point arithmetic differs from integer arithmetic in that exponents must be handled as well as the magnitudes of the operands. • The exponents of the operands must be made equal for addition and subtraction. The fractions are then added or subtracted as appropriate, and the result is normalized. • Eg: Perform the floating point operation:(.101* *24)2 • Start by adjusting the smaller exponent to be equal to the larger exponent, and adjust the fraction accordingly. Thus we have .101* 23 = .010 *24, losing .001 *23 of precision in the process. • The resulting sum is ( )*24 =1.001*24 =.1001* 25, and rounding to three significant digits, .100 *25, and we have lost another *24 in the rounding process.
2. • Start by adjusting the smaller exponent to be equal to the larger exponent, and adjust the fraction accordingly. Thus we have .101* 23 = .010 *24, losing .001 *23 of precision in the process. • The resulting sum is ( )*24 =1.001*24 =.1001* 25, and rounding to three significant digits, .100 *25, and we have lost another *24 in the rounding process.")
27
Floating Point Multiplication/Division
• Floating point multiplication/division are performed in a manner similar to floating point addition/subtraction, except that the sign, exponent, and fraction of the result can be computed separately. • Like/unlike signs produce positive/negative results, respectively. Exponent of result is obtained by adding exponents for multiplication, or by subtracting exponents for division. Fractions are multiplied or divided according to the operation, and then normalized. • Ex: Perform the floating point operation: (+.110 *25)/(+.100* 24)2 • The source operand signs are the same, which means that the result will have a positive sign. We subtract exponents for division, and so the exponent of the result is 5 – 4 = 1. • We divide fractions, producing the result: 110/100 = 1.10. • Putting it all together, the result of dividing (+.110 *25) by ( * 24) produces (+1.10* 21). After normalization, the final result is (+.110* 22).
/(+.100* 24)2. • The source operand signs are the same, which means that the result will have a positive sign. We subtract exponents for division, and so the exponent of the result is 5 – 4 = 1. • We divide fractions, producing the result: 110/100 = • Putting it all together, the result of dividing (+.110 *25) by (+.100 * 24) produces (+1.10* 21). After normalization, the final result is (+.110* 22).")
28
Floating point Arithmetic
Represent binary number in floating point format = *210 In single precision format sign =0,exponent =e+127 =10+127=137= …0

29
Floating Point Addition
B= …0 Exponent for A= Actual Exponent = =10 Exponent B = =133 Actual exponent= =6 Number B has smaller exponent with difference 4 .Hence its mantissa is shifted right by 4 bits Shifted mantissa of B= Add mantissas A = …0 B = …0 Result= …0 Result = …0

30
Adders and Simple ALUs Addition is the most important arithmetic operation in computers: Even the simplest computers must have an adder An adder, plus a little extra logic, forms a simple ALU Simple Adders Carry Lookahead Adder Counting and Incrementing Design of Fast Adders Logic and Shift Operations Multifunction ALUs

31
Simple Adders Binary half-adder (HA) and full-adder (FA).
 and full-adder (FA).")
32
Full-Adder Implementations
Full adder implemented with two half-adders, by means of two 4-input multiplexers, and as two-level gate network.

33
Ripple-Carry Adder: Slow But Simple
Because of the carry propagation time to MSb position. It is linearly proportional to the length n of the adder Critical path Ripple-carry binary adder with 32-bit inputs and output.

34
Carry Look ahead adder The carry look ahead adder generates carry for any position parallely by additional logic circuit referred to as carry look ahead block. gi = xi yi pi = xi yi The main part of an adder is the carry network. The rest is just a set of gates to produce the g (carry generate function) and p (carry propagate function) signals and the sum bits.
 and p (carry propagate function) signals and the sum bits.")
35
Carry-Lookahead Addition
• Carries are represented in terms of Gi (generate) and Pi (propagate) expressions. Gi = aibi and Pi = ai + bi c0 = 0 c1 = G0 c2 = G1 + P1G0 c3 = G2 + P2G1 + P2P1G0 c4 = G3 + P3G2 + P3P2G1 + P3P2P1G0
 and Pi (propagate) expressions. Gi = aibi and Pi = ai + bi. c0 = 0. c1 = G0. c2 = G1 + P1G0. c3 = G2 + P2G1 + P2P1G0. c4 = G3 + P3G2 + P3P2G1 + P3P2P1G0.")
36
Ripple-Carry Adder Revisited
The carry recurrence: ci+1 = gi + pi ci Latency of k-bit adder is roughly 2k gate delays: 1 gate delay for production of p and g signals, plus 2(k – 1) gate delays for carry propagation, plus 1 XOR gate delay for generation of the sum bits The carry propagation network of a ripple-carry adder.
 gate delays for carry propagation, plus. 1 XOR gate delay for generation of the sum bits. The carry propagation network of a ripple-carry adder.")
37
The Complete Design of a Carry Look Ahead Adder
gi = xi yi pi = xi yi K-bit carry- lookahead adder

38
Carry Lookahead Adder • Maximum gate delay for the carry generation is only 3. The full adders introduce two more gate delays. Worst case path is 5 gate delays.

39
16-bit Group Carry Lookahead Adder
• A16-bit GCLA is composed of four 4-bit CLAs, with additional logic that generates the carries between the four-bit groups. GG0 = G3 + P3G2 + P3P2G1 + P3P2P1G0 GP0 = P3P2P1P0 c4 = GG0 + GP0c0 c8 = GG1 + GP1c4 = GG1 + GP1GG0 + GP1GP0c0 c12 = GG2 + GP2c8 = GG2 + GP2GG1 + GP2GP1GG0 + GP2GP1GP0c0 c16 = GG3 + GP3c12 = GG3 + GP3GG2 + GP3GP2GG1 + GP3GP2GP1GG0 + GP3GP2GP1GP0c0

40
16-Bit Group Carry Lookahead Adder
• Each CLA has a longest path of 5 gate delays. • In the GCLL section, GG and GP signals are generated in 3 gate delays; carry signals are generated in 2 more gate delays, resulting in 5 gate delays to generate the carry out of each GCLA group and 10 gates delays on the worst case path (which is s15 – not c16).
.")
41
The Booth Algorithm • Booth multiplication reduces the number of additions for intermediate results, but can sometimes make it worse as we will see. • Positive and negative numbers treated alike.

42
A Worst Case Booth Example
• A worst case situation in which the simple Booth algorithm requires twice as many additions as serial multiplication.

43
Bit-Pair Recoding (Modified Booth Algorithm)
")
44
Coding of Bit Pairs

45
Multifunction ALUs Logic fn (AND, OR, . . .) Operand 1 Logic unit
Arith 1 Operand 1 Result Operand 2 Select fn type (logic or arith) Arith fn (add, sub, . . .) General structure of a simple arithmetic/logic unit.
 Arith fn (add, sub, . . .) General structure of a simple arithmetic/logic unit.")
46
An ALU for MiniMIPS Figure A multifunction ALU with 8 control signals (2 for function class, 1 arithmetic, 3 shift, 2 logic) specifying the operation.
 specifying the operation.")
47
Machine Cycle The CPU uses repeating machine cycles to execute instructions in the program, one by one, from beginning to end. A simplified cycle can consist of three phases: fetch, decode and execute The steps of a cycle

48
Load Fetch/Execute Cycle
PC -> MAR Transfer the address from the PC to the MAR MDR -> IR Transfer the instruction to the IR IR(address) -> MAR Address portion of the instruction loaded in MAR MDR -> A Actual data copied into the accumulator PC + 1 -> PC Program Counter incremented
 -> MAR. Address portion of the instruction loaded in MAR. MDR -> A. Actual data copied into the accumulator. PC + 1 -> PC. Program Counter incremented.")
49
Store Fetch/Execute Cycle
PC -> MAR Transfer the address from the PC to the MAR MDR -> IR Transfer the instruction to the IR IR(address) -> MAR Address portion of the instruction loaded in MAR A -> MDR* Accumulator copies data into MDR PC + 1 -> PC Program Counter incremented *Notice how Step #4 differs for LOAD and STORE
 -> MAR. Address portion of the instruction loaded in MAR. A -> MDR* Accumulator copies data into MDR. PC + 1 -> PC. Program Counter incremented. *Notice how Step #4 differs for LOAD and STORE.")
50
ADD Fetch/Execute Cycle
PC -> MAR Transfer the address from the PC to the MAR MDR -> IR Transfer the instruction to the IR IR(address) -> MAR Address portion of the instruction loaded in MAR A + MDR -> A Contents of MDR added to contents of accumulator PC + 1 -> PC Program Counter incremented
 -> MAR. Address portion of the instruction loaded in MAR. A + MDR -> A. Contents of MDR added to contents of accumulator. PC + 1 -> PC. Program Counter incremented.")
51
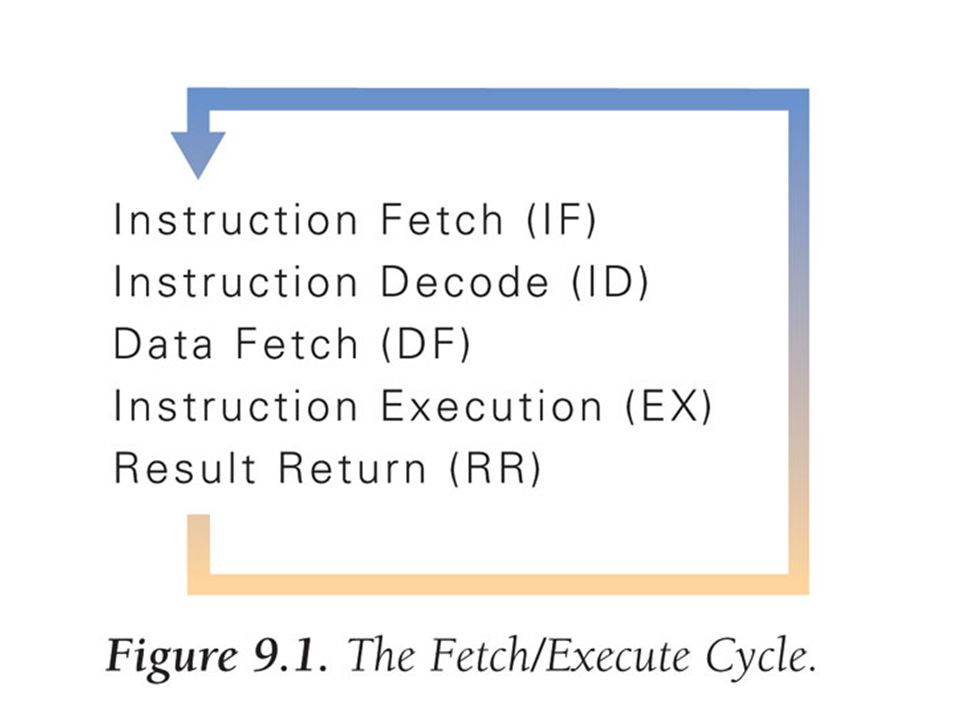
The Fetch/Execute Cycle
A five-step cycle: Instruction Fetch (IF) Instruction Decode (ID) Data Fetch (DF) Instruction Execution (EX) Result Return (RR)
 Instruction Decode (ID) Data Fetch (DF) Instruction Execution (EX) Result Return (RR)")
52
Instruction Interpretation
Process of executing a program Computer is interpreting our commands, but in its own language

53
Execution begins by moving the instruction at the address given by the PC from memory to the control unit

54
Instruction Interpretation (cont'd)
Bits of the instruction are placed into the decoder circuit of the CU Once an instruction is fetched, the Program Counter (PC) can be readied for fetching the next instruction The PC is “incremented”
 can be readied for fetching the next instruction. The PC is incremented")
55
Instruction Interpretation (cont'd)
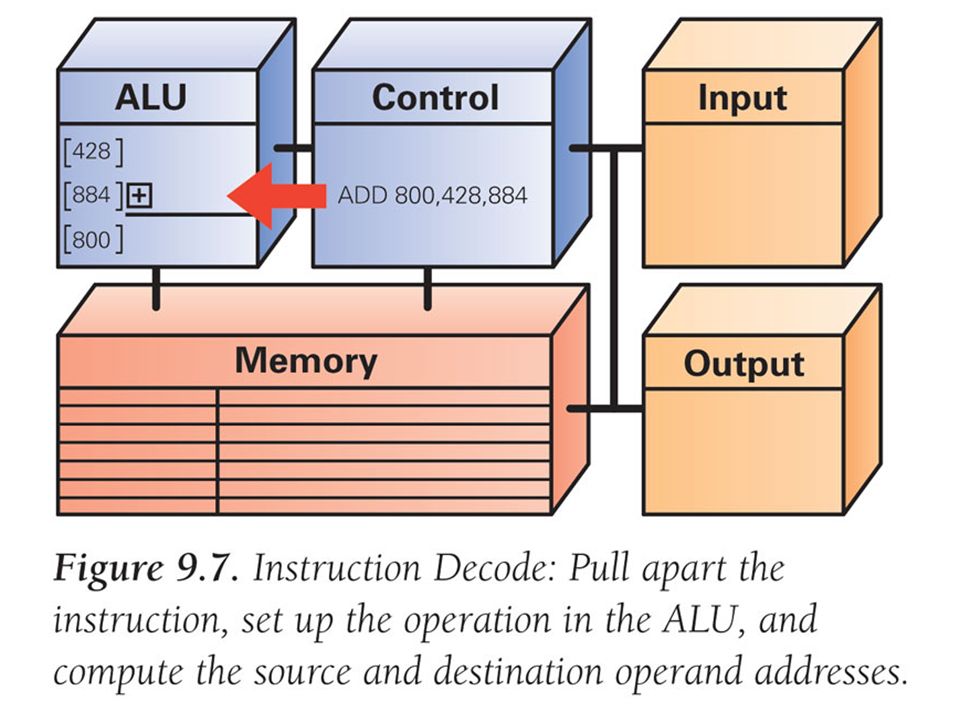
In the Instruction Decode step, the ALU is set up for the indicated operation The Decoder will find the memory address of the instruction's data (source operands) Most instructions operate on 2 data values stored in memory (like ADD), so most instructions have addresses for two source operands These addresses are passed to the circuit that fetches the values from memory during the next step, Data Fetch The Decoder finds destination address for the Result Return step, and places it in RR circuit Decoder determines what operation the ALU will perform, and sets it up appropriately
 Most instructions operate on 2 data values stored in memory (like ADD), so most instructions have addresses for two source operands. These addresses are passed to the circuit that fetches the values from memory during the next step, Data Fetch. The Decoder finds destination address for the Result Return step, and places it in RR circuit. Decoder determines what operation the ALU will perform, and sets it up appropriately.")
58
Instruction Interpretation (cont'd)
Instruction Execution: The actual computation is performed. For the ADD instruction, the addition circuit adds the two source operands together to produce their sum

60
Instruction Interpretation (cont'd)
Result Return: result of execution is returned to the memory location specified by the destination address. Once the result is returned, the cycle begins again (This is a Loop).
.")
64
Execution of complete Instructions
Consider the instruction Add (R3), R1 which adds the content of memory location pointed to by R3 to register R1. Executing this instruction requires the following actions Fetch the instruction Fetch the first operand Perform the addition Load the result into R1
, R1 which adds the content of memory location pointed to by R3 to register R1. Executing this instruction requires the following actions. Fetch the instruction. Fetch the first operand. Perform the addition. Load the result into R1.")
65
FETCH OPERATION Loading the content of PC into MAR and sending Read request to the memory. Select signal is set to select 4, which causes the MUX to select the constant 4 and add to the operand at B, Which is the content of PC and the result is stored in register Z The updated value is moved from register Z back into PC The word fetched from memory loaded into IR

66
DECODE and EXECUTING PHASE
Interprets the content of IR Enables the control circuitry to activate the control signals The content of register R3 transferred to MAR and memory Read initiated Content of R1 transferred to register Y to prepare for addition operation Memory operand available in register MDR and addition performed Sum is stored in register Z, then transferred to R1

67
What Is A Pipeline? Pipelining is used by virtually all modern microprocessors to enhance performance by overlapping the execution of instructions. A common analogue for a pipeline is a factory assembly line. Assume that there are three stages: Welding Painting Polishing For simplicity, assume that each task takes one hour.

68
What Is A Pipeline? If a single person were to work on the product it would take three hours to produce one product. If we had three people, one person could work on each stage, upon completing their stage they could pass their product on to the next person (since each stage takes one hour there will be no waiting). We could then produce one product per hour assuming the assembly line has been filled.
. We could then produce one product per hour assuming the assembly line has been filled.")
69
Characteristics Of Pipelining
If the stages of a pipeline are not balanced and one stage is slower than another, the entire throughput of the pipeline is affected. In terms of a pipeline within a CPU, each instruction is broken up into different stages. Ideally if each stage is balanced (all stages are ready to start at the same time and take an equal amount of time to execute.) the time taken per instruction (pipelined) is defined as: Time per instruction (unpipelined) / Number of stages
 the time taken per instruction (pipelined) is defined as: Time per instruction (unpipelined) / Number of stages.")
70
Characteristics Of Pipelining
The previous expression is ideal. We will see later that there are many ways in which a pipeline cannot function in a perfectly balanced fashion. In terms of a CPU, the implementation of pipelining has the effect of reducing the average instruction time, therefore reducing the average CPI. EX: If each instruction in a microprocessor takes 5 clock cycles (unpipelined) and we have a 4 stage pipeline, the ideal average CPI with the pipeline will be
 and we have a 4 stage pipeline, the ideal average CPI with the pipeline will be")
71
Instruction Pipelining
• Break the instruction cycle into stages • Simultaneously work on each stage Two Stage Instruction Pipeline Break instruction cycle into two stages: • FI: Fetch instruction • EI: Execute instruction FI EI Clock cycle ® Instruction i Instruction i+1 Instruction i+2 Instruction i+3 Instruction i+4 FI EI E

72
Two Stage Instruction Pipeline
Break instruction cycle into two stages: • FI: Fetch instruction • EI: Execute instruction Clock cycle Instruction i FI EI Instruction i FI EI Instruction i FI EI Instruction i FI EI Instruction i FI EI

73
Two Stage Instruction Pipeline
• But not doubled: q Fetch usually shorter than execution q If execution involves memory accessing, the fetch stage has to wait q Any jump or branch means that prefetched instructions are not the required instructions • Add more stages to improve performance

74
Six Stage Pipelining • Fetch instruction (FI)
• Decode instruction (DI) • Calculate operands (CO) • Fetch operands (FO) • Execute instructions (EI) • Write operand (WO)
 • Calculate operands (CO) • Fetch operands (FO) • Execute instructions (EI) • Write operand (WO)")
75
MIPS Pipeline Pipeline stages: IF ID (decode + Reg fetch) EX MEM
Write back On each clock cycle another instruction is fetched and begins its five-step execution. If an instruction is started every clock cycle, the performance will be five times that of a machine that is not pipelined.

76
Looking At The Big Picture
Overall the most time that an non-pipelined instruction can take is 5 clock cycles. Below is a summary: Branch - 2 clock cycles Store - 4 clock cycles Other - 5 clock cycles EX: Assuming branch instructions account for 12% of all instructions and stores account for 10%, what is the average CPI of a non-pipelined CPU? ANS: 0.12*2+0.10*4+0.78*5 = 4.54

77
The Classical RISC 5 Stage Pipeline
In an ideal case to implement a pipeline we just need to start a new instruction at each clock cycle. Unfortunately there are many problems with trying to implement this. Obviously we cannot have the ALU performing an ADD operation and a MULTIPLY at the same time. But if we look at each stage of instruction execution as being independent, we can see how instructions can be “overlapped”.

Similar presentations






>")













 Fetch Operand (FO) Decode Instruction (DI) Write Operand (WO) Execution Instruction (EI) S3S3 S4S4 S1S1 S2S2.>")


 operand(s) Usually more than.>")
