Download presentation
Presentation is loading. Please wait.

1
Biology 3201 Unit III: Genetics
Molecular Biology Biology 3201 Unit III: Genetics

2
Textbook Reference: Sections 17.1 and 17.2
Scientific Discoveries Leading to the Identification of DNA as the material of Heredity

3
Modern Molecular Genetics
A turning point in genetics was reached when biologists ceased to ask how genes were transmitted (classical Mendelian genetics) and began to ask how genes functioned (modern molecular genetics). The following individuals made the major advances in the field:
 and began to ask how genes functioned (modern molecular genetics). The following individuals made the major advances in the field:")
4
Mendel Gregor Mendel used the scientific process to lay the foundation for the science of genetics through his study of pea plants. The “factors” described by Mendel were later called genes. Formulated the Law of Dominance, Law of Segregation and Law of Independent Assortment

5
1902- Sutton and Boveri Observed the separation of the homologous pairs of chromosomes during spermatogenesis. Realized that the chromosomes that separated during meiosis were the same as the chromosomes that united in fertilization. Hypothesized that the “factors” of Mendel’s Theory were carried on chromosomes and that that each chromosome contains many genes.

6
1910- Morgan Discovered sex-linked genes

7
1920’s - Levine Discovered 2 types of nucleic acids: Ribonucleic acid (RNA) and Deoxyribonucleic acid (DNA) Each nucleic acid is made up of a long chain of repeating units called nucleotides Basic structure of a nucleotide 5-carbon sugar (ribose in RNA; deoxyribose in DNA) a phosphate group one of 4 nitrogenous bases purines: Adenine, A & Guanine, G (in DNA and RNA) pyrimidines: Cytosine, C & Thymine, T (in DNA); Cytosine & Uracil, U (in RNA)
 a phosphate group. one of 4 nitrogenous bases. purines: Adenine, A & Guanine, G (in DNA and RNA) pyrimidines: Cytosine, C & Thymine, T (in DNA); Cytosine & Uracil, U (in RNA)")
8
Levine (con’t) Many nucleotides make up a single nucleic acid chain.
Phosphate groups and sugar molecule make up the backbone and nitrogenous bases stick out from the chain (Figure 17.5, p.569)
")
9
1928 – Griffith (p.570) Griffith was trying to develop a vaccine for bacterial pneumonia (a disease caused by Streptococcus pneumoniae, a pathogenic strain of bacteria) a) When mice were injected with heat-killed pathogenic bacteria, the mice lived b) When injected with pathogenic bacteria, the mice died c) When injected with a live non-pathogenic mutant strain, the mice lived d) When injected with a mixture of heat-killed pathogenic bacteria and live non-pathogenic bacteria, the mice died. Live pathogenic bacteria could be extracted from their bodies.
 a) When mice were injected with heat-killed pathogenic bacteria, the mice lived. b) When injected with pathogenic bacteria, the mice died. c) When injected with a live non-pathogenic mutant strain, the mice lived. d) When injected with a mixture of heat-killed pathogenic bacteria and live non-pathogenic bacteria, the mice died. Live pathogenic bacteria could be extracted from their bodies.")
10
Griffith This was called the Transforming Principle
Somehow the dead, pathogenic bacteria passed on their disease-causing abilities to the non-pathogenic bacteria ie. they “transformed” them into pathogens

11
1940s – Avery, MacLeod, and McCarty
Identified DNA as the transforming material in Griffith’s experiment. · Transformation did occur when protein in bacteria was destroyed. · Transformation did occur when RNA in bacteria was destroyed. · Transformation did not occur when DNA in bacteria was destroyed.

12
1940’s – Chargoff Discovered the nitrogenous base ratio in DNA = Chargaff’s Rule · The number of adenine bases equals the number of thymine bases · The number of guanine bases equals the number of cytosine bases Nucleotide composition(proportion of each of the 4 nucleotides in DNA) · varies from one species to another · is constant within the same species
 · varies from one species to another. · is constant within the same species.")
13
1950-51 – Franklin and Wilkins (p.573)
Using X-ray technology discovered a pattern of repeating structures (nucleotides) These repeating units were arranged in the form of a helix (spiral) Observed how DNA reacted with water Hydrophobic nitrogenous bases on inside Hydrophilic sugar-phosphate backbone on outside
 These repeating units were arranged in the form of a helix (spiral) Observed how DNA reacted with water. Hydrophobic nitrogenous bases on inside. Hydrophilic sugar-phosphate backbone on outside.")
14
1952 – Hershey and Chase Provided final proof that DNA, not protein, is the genetic material Conducted experiments on bacteriophages, viruses made up of a DNA core surrounded by a protein coat. They attack bacterial cells. Tagged viral DNA with radioactive phosphorus and tagged viral protein with radioactive sulphur; then mixed the viruses with bacteria The bacterial cells showed only radioactive DNA, not radioactive protein (Figure 17.8 page 571)
")
15
1953 –64 – Watson and Crick (p.574 & 575)
First to produce a structural model of DNA DNA is composed of two strands of nucleotides wound around each other forming a double helix (like a twisted ladder) Alternating sugar and phosphate groups form the sides (like handrails of a ladder) Nitrogenous bases pair up in the interior of the helix, linked by hydrogen bonds (like rungs of a ladder).
 Alternating sugar and phosphate groups form the sides (like handrails of a ladder) Nitrogenous bases pair up in the interior of the helix, linked by hydrogen bonds (like rungs of a ladder).")
16
Only certain bases bond with each other
Adenine with Thymine, Cytosine with Guanine. Therefore the 2 strands are not identical, but are complementary to one another Eg: A strand of DNA with base sequence T-A-G-C-A-T would be paired with a complementary strand sequence of A-T-C-G-T-A. The 2 complementary strands are antiparallel to one another ie. the phosphate bridges joining one nucleotide to the next run in opposite directions in each strand Thus the end of each DNA molecule contains the 5’ end of one strand and the 3’ end of the other

17
Important Terms Nucleus: The location of DNA and the site of replication. Nucleolus: A granular body found in the nucleus that is the location of ribosomal synthesis. Chromosomes: Made up of DNA and proteins Chromatin: Made up of DNA and proteins and is the material that makes up chromosomes. The threads in the nucleus are usually referred to as chromosomes and the material that comprises chromosomes is usually referred to as chromatin.

18
DNA: The genetic/information molecule The control centre for directing metabolism via regulation of production of enzymes and other proteins The portion of a chromosome that carries the code for protein synthesis. Every three nucleotides codes for one amino acid in a protein

19
Genes Functional units of DNA
Code for a specific protein or part of a protein (polypeptide chain) polypeptides are assembled into finished proteins What proteins a cell produces depends on the genes (pieces of DNA) that are expressed—leads to specialization of form and/or function of cells
 polypeptides are assembled into finished proteins. What proteins a cell produces depends on the genes (pieces of DNA) that are expressed—leads to specialization of form and/or function of cells.")
20
Proteins: (p.46) · Comprise 50% of the dry weight of cells
· Most complex organic molecules known · Humans have numerous proteins, each with a specific structure and function · Each protein is determined by a specific gene

21
Structure of Protein Monomers = amino acids (20 total, 8 = essential)
Polymers = polypeptide chains which are folded in specific ways to form proteins

22
Function of Protein Structure: eg. collagen in tendons; keratin in hair Storage of amino acids: eg. casein in milk Transport: eg. hemoglobin in blood Movement: eg. actin & myosin in muscles Catalysts (enzymes): eg. proteases hydrolyze proteins Others: receptor proteins in cell membranes and defensive proteins (antibodies)
: eg. proteases hydrolyze proteins. Others: receptor proteins in cell membranes and defensive proteins (antibodies)")
23
RNA DNA doesn’t have to leave the nucleus. The information for protein production contained within the DNA is carried to the ribosomes by messenger RNA. RNA is a nucleic acid similar to DNA. The RNA molecule is a large complex molecule composed of a chain of smaller molecules called nucleotides. A single nucleotide unit consists of: A sugar called ribose A phosphate group One of four nitrogen bases: adenine, guanine, uracil and cytosine

24
DNA and Protein Synthesis
Chromosomes are not concrete objects. They are chemical in nature composed of the substance deoxyribonucleic acid (DNA). This DNA controls protein production in all cells.
. This DNA controls protein production in all cells.")
25
The process can be studied in three stages:
1. Source of the blue print for protein production – the structure of DNA contained within the nucleus of the cell. 2. Transmission of the information in the original blueprint (DNA) to the site of the protein production – the structure of messenger RNA and its movement from the nucleus to the ribosome. 3. Translation of the original blueprint (DNA) into the final product – the interaction of all the factors on the ribosome in the formation of protein.
 to the site of the protein production – the structure of messenger RNA and its movement from the nucleus to the ribosome. 3. Translation of the original blueprint (DNA) into the final product – the interaction of all the factors on the ribosome in the formation of protein.")
26
A similar concept in the world of automation would look as follows:
Source of Blue Print Transmission of Blueprint Site of Production Programmed computer Electrical wires Printer DNA mRNA Ribosome

27
DNA REPLICATION Introduction
The formation of a multicellular organism from a single zygote is a miraculous one. In humans, during the 240-day gestation period the trillions of cells that are produced become differentiated, ie. they develop into specialized tissues and organs. In order for this to be successful and produce a viable human being, two conditions must be met:

28
1. The genome - the sum of all the DNA carried in an organism’s cells - must be copied quickly,
2. it must be copied accurately. The structural features of DNA and the action of a certain set of enzymes are responsible for this speed and accuracy of the process of DNA replication

29
The Process of Replication
· Occurs in the nucleus during interphase of the cell cycle · two molecules of DNA are made from one. · replication follows a semi-conservative model (Fig , p. 582). · when a molecule of DNA is copied, each new molecule contains one strand of parental DNA and one strand of new DNA.
. · when a molecule of DNA is copied, each new molecule contains one strand of parental DNA and one strand of new DNA.")
30
The 3 stages of DNA replication are:
1. Initiation-when a portion of the double helix is unwound 2. Elongation-when two new strands of DNA are assembled 3. Termination-when the new DNA molecules re-form into helices NOTE: all of these stages may be happening simultaneously on the same DNA molecule. DNA replication is followed by proofreading and correction.

31
Stage 1: Initiation Replication begins at the replication origin - a specific nucleotide sequence that codes for replication. A group of enzymes recognize this nucleotide sequence, bind to the DNA at the origin and separate the two strands to open a replication bubble.

32
· The DNA strand must be unwound from its helical shape in order for the individual chains of nucleotides to be exposed and serve as templates for the new strands. · Replication forks are the points at which the DNA helix is unwound and new strands develop. One replication fork is found at each end of a replication bubble.

33
· Helicases are a set of enzymes that cleave and unravel short segments of DNA just ahead of the replication fork. · Replication is initiated at hundreds or even thousands of replication origins at any one time. Replication continues until all the replication bubbles have met and the two new DNA molecules separate from each other. (Figure 17.21,p. 583)
")
34
Stage 2: Elongation Elongation of new DNA at the replication fork is catalyzed by enzymes called DNA polymerases. Using each parent strand as a template, these enzymes add nucleotides, one at a time to create a new daughter strand that is complementary to the parent strand

35
DNA polymerase attaches new nucleotides only to the 3' end of a pre-existing chain of nucleotides therefore replication can only take place in the 5' to 3' direction DNA polymerase cannot initiate synthesis of the new strands by joining the first nucleotides but adds nucleotides to a primer, a short strand of RNA that is synthesized by the enzyme primase and is complementary to the DNA sequence of the parent strand

36
Once the primer has been constructed, DNA polymerase extends the fragment by adding DNA nucleotides.
A second molecule of DNA polymerase later replaces the RNA nucleotides with DNA nucleotides. During DNA synthesis the overall direction of elongation is the same for both daughter strands but different along each of the parent strands

37
Leading strand: This strand is replicated continuously in the 5' to 3' direction, with the steady addition of nucleotides to the end of a single primer. Elongation proceeds in the same direction as the movement of the replication fork.

38
Lagging strand The other strand is manufactured more slowly than the leading strand. This strand is first made in short pieces of 100 to 200 nucleotides called Okazaki fragments A new primer is made for each Okazaki fragment

39
DNA polymerase adds nucleotides to the end of each fragment in the 5' to 3' direction.
The fragments are spliced together by the enzyme DNA ligase, which catalyzes the formation of phosphate bonds between nucleotides. The resulting daughter strand of DNA still ends up being manufactured in the same direction as the movement of the replication fork. (Figure 17.23, p.585)
")
40
Stage 3: Termination Once the newly formed strands are complete, the daughter DNA molecules rewind automatically in order to regain their chemically stable helical structure. This creates a problem at each end of a linear chromosome (in eukaryotes). (Figure 17.24, p.585)
. (Figure 17.24, p.585)")
41
Once the RNA primer has been removed form the 5' end of each daughter strand there is no adjacent fragment onto which new DNA nucleotides can be added to fill the gap. The result is that each daughter molecule is slightly shorter than its parent template. With each replication, more DNA is lost. Human cells lose about 100 base pairs from the ends of each chromosome with each replication.

42
This loss of genetic material would prove disastrous for the cell, except for the presence of special regions at the end of each chromosome in eukaryotes, called telomeres - stretches of highly repetitive nucleotide sequences, typically rich in G nucleotides, which do not direct cell development. Instead, their erosion with each cell division helps to protect against the loss of other, important genetic material. In human cells, telomeres are composed of the sequence TTAGGG repeated several thousand times. The erosion of the telomeres is related to the death of the cell.

43
Proofreading and Correction
DNA Replication also involves much proofreading and correction of base pairing After each nucleotide is added to a new DNA strand, DNA polymerase can recognize whether or not hydrogen bonding is taking place between base pairs. The absence of hydrogen bonding indicates a mismatch between the bases.

44
When this occurs, the polymerase excises (removes) the incorrect base from the new strand and then replaces it with the correct nucleotide using the parent strand as a template. This double check brings the accuracy of the replication process to a factor of about one error per billion base pairs. In total, the process of DNA replication involves the action of dozens of different enzymes and other proteins. These substances work closely together in a complex known as a replication machine. Refer to Table 17.2, p. 587 for the key enzymes involved in DNA replication.

45
Importance of DNA replication to cell division and the continuity of life
DNA replication occurs during mitosis and meiosis and must ensure that the daughter cells receive the exact duplicates of the genetic information. Mistakes in the DNA code are very damaging because DNA guides the entire functioning of the cell. DNA codes for polypeptides that make up proteins. These proteins are the main structural components of the cell and are other important molecules such as enzymes, antibodies and hormones.

46
THE GENETIC CODE AND GENE EXPRESSION
· How DNA stores information · This is determined by the order of the nitrogen bases (nucleotides) in a DNA molecule · Every three nucleotides of a DNA molecule (triplet) specifies a particular amino acid. · Amino acids are joined together to form polypeptides chains, 2 or more of which are joined together to make a particular protein
 in a DNA molecule. · Every three nucleotides of a DNA molecule (triplet) specifies a particular amino acid. · Amino acids are joined together to form polypeptides chains, 2 or more of which are joined together to make a particular protein.")
47
A gene is a segment of DNA that contains the instructions for the synthesis of a particular polypeptide. The gene is made up of many nucleotide triplets, the order of which determines the order of amino acids present in the polypeptide. The gene will also contain codes for punctuation – to say where a polypeptide begins and ends. (Table 17.2, p. 590)
")
48
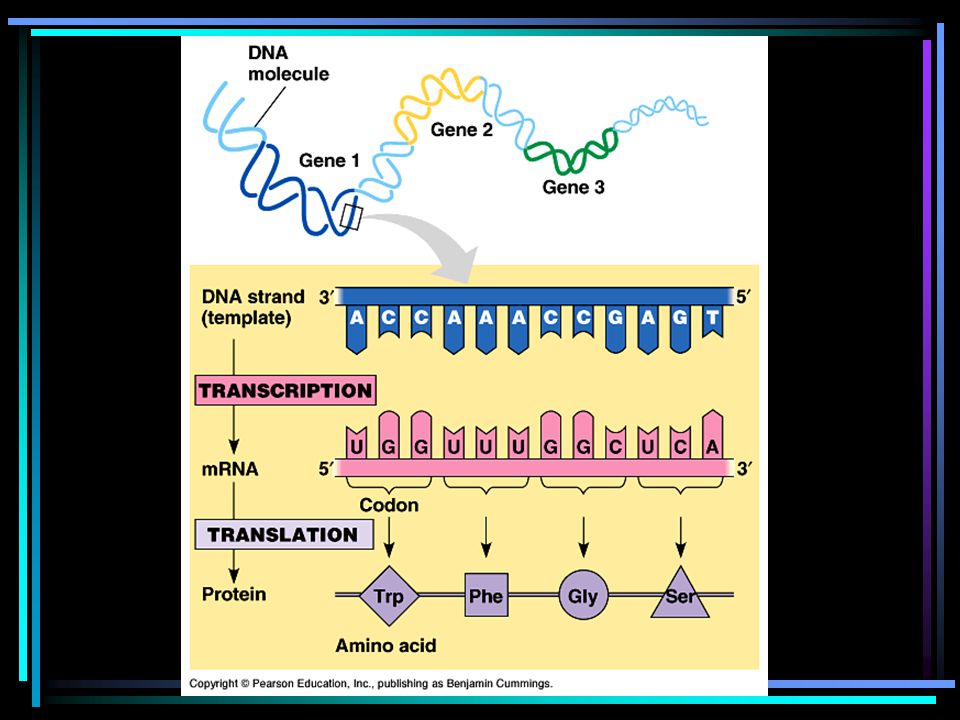
Gene Expression (Protein Synthesis)
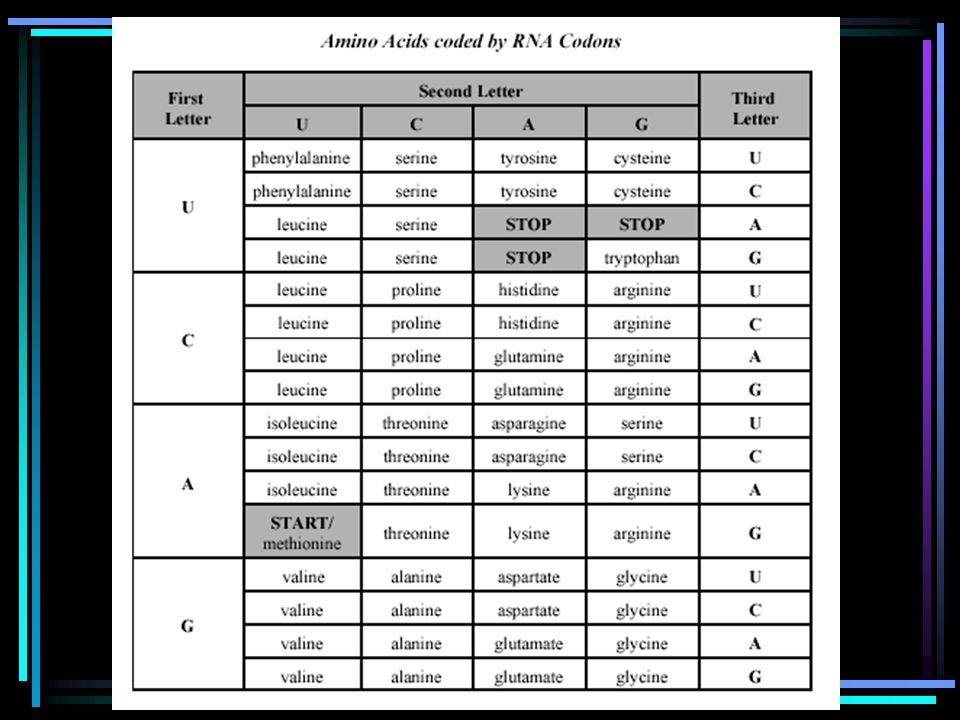
The transfer of genetic information from DNA to protein consists of two processes: 1. Transcription: · The information in DNA is copied onto an RNA molecule called messenger RNA (mRNA) which is complementary (not identical) to the DNA strand. · Every 3 RNA nucleotides is called a codon · There are 20 different amino acids but only four different nucleotides. · There are 64 possible combinations of three bases each. · Most amino acids are specified by more than one codon (Table 17.2, p.590)
 which is complementary (not identical) to the DNA strand. · Every 3 RNA nucleotides is called a codon. · There are 20 different amino acids but only four different nucleotides. · There are 64 possible combinations of three bases each. · Most amino acids are specified by more than one codon (Table 17.2, p.590)")
49
mRNA Codons

50
2. Translation: · The mRNA travels from the nucleus to ribosomes in the cytoplasm where a polypeptide is synthesized

51
GENE EXPRESSION (PROTEIN SYNTHESIS)
Genes are found in the nucleus but proteins are synthesized on ribosomes in the cytoplasm. DNA provides the code for protein synthesis but RNA initiates and completes protein synthesis. There are three (3) types of RNA involved in protein synthesis. A. Messenger RNA (mRNA): · A single strand of DNA that is produced in the nucleus · Carries the genetic message from DNA to the ribosome in the cytoplasm. · Each RNA codon (3 nucleotides) is complementary to a DNA triplet (3 nucleotides)
 types of RNA involved in protein synthesis. A. Messenger RNA (mRNA): · A single strand of DNA that is produced in the nucleus. · Carries the genetic message from DNA to the ribosome in the cytoplasm. · Each RNA codon (3 nucleotides) is complementary to a DNA triplet (3 nucleotides)")
52
B.Transfer RNA (tRNA): · Found in the cytoplasm and transfers free amino acids in the cytoplasm to the ribosome. · Each tRNA has a cloverleaf shape and carries only one amino acid · At one end is the amino acid (Figure 17.29, p.593) · At the other is a tRNA antocodon (3 nucleotides) that specifies the amino acid it carries and is complementary to the mRNA codon C. Ribosomal RNA (rRNA): · Forms part of the ribosome (60%). · Thought to be involved in the bonding of amino acids to form protein chains. · Formed in the nucleoli of the cell.
 · At the other is a tRNA antocodon (3 nucleotides) that specifies the amino acid it carries and is complementary to the mRNA codon. C. Ribosomal RNA (rRNA): · Forms part of the ribosome (60%). · Thought to be involved in the bonding of amino acids to form protein chains. · Formed in the nucleoli of the cell.")
55
Transcription: DNA mRNA (p.591)
Only one strand of DNA, the sense strand needs to be transcribed. This strand provides the template for mRNA synthesis. The other strand = the antisense strand. 1. A particular sequence of nucleotides on the DNA molecule tells the enzyme RNA polymerase where to bind and begin transciption. 2. Once bound to the DNA, RNA polymerase opens a section of the DNA helix.

56
3. RNA polymerase moves along the sense strand, in the 5' to 3' direction adding RNA nucleotides that are complementary to those on the DNA strand (Uracil bonds instead of thymine). 4. As RNA polymerase passes a section of DNA, the DNA helix reforms and the elongating mRNA separates from the DNA 5. Enzymes catalyse the bonding of phosphate groups to sugar groups forming the backbone of the mRNA

57
Transcription continued
6. Transcription stops when the terminator is reached on the DNA strand. The mRNA detaches from the DNA molecule. 7. The messenger RNA will undergo some further processing, and then leave the nucleus to travel to a ribosome in the cytoplasm.

58
Recall that: Each group of three bases on a mRNA is called a codon and specifies for a particular amino acid. This codon is complementary to a DNA triplet on the sense strand which codes for that same amino acid. There are also intiation codons which start protein synthesis and termination codons which stop protein synthesis

59
Translation: mRNA protein (p. 593)
· The mRNA reaches the ribosome. The ribosome moves along the RNA until it reaches an initiation codon (AUG - methionine). The ribosome attaches to the initiation codon and the next adjacent codon. · Amino acids are brought to the ribosome bound to molecules of tRNA. The anticodon (UAC) of the tRNA that carries the amino acid methionine binds to the initiation codon (AUG).
. The ribosome attaches to the initiation codon and the next adjacent codon. · Amino acids are brought to the ribosome bound to molecules of tRNA. The anticodon (UAC) of the tRNA that carries the amino acid methionine binds to the initiation codon (AUG).")
60
Translation then follows a cycle of 3 steps:
1. The anticodon of the next tRNA bonds to the next mRNA codon. 2. Enzymes catalyse the formation of a peptide bond between the two adjacent amino acids. The polypeptide chain on the first tRNA is transferred to the next tRNA. 3. The ribosome moves one codon along the mRNA. The first tRNA is released and is free to pick up another amino acid.

61
· The cycle repeats with the arrival of the next tRNA
· The cycle repeats with the arrival of the next tRNA. The tRNA will attach to the next site and the bonding process is repeated until a termination codon is reached. The termination codon on the mRNA determines the end of protein synthesis and the polypeptide chain is released from the ribosome.

64
Question # 1 Which genetic researcher isolated two types of nucleic acids? (A) Levene (B) McClintock (C) Mendel (D) Watson
 Mendel. (D) Watson.")
65
What does X represent in the diagram below?
(A) base pairs (B) deoxyribose (C) phosphates (D) ribose
 base pairs. (B) deoxyribose. (C) phosphates. (D) ribose.")
66
Question # 3 In which step of DNA replication does the molecule unwind and unzip? (A) elongation (B) initiation (C) proofreading (D) termination
 proofreading. (D) termination.")
67
Question # 4 How many amino acids does a codon represent? (A) 1 (B) 2
 1 (B) 2")
69
Question # 5 Which sequence on a DNA strand corresponds to the first amino acid inserted into a protein? (A) ATG (B) AUG (C) TAC (D) UAC
 ATG. (B) AUG. (C) TAC. (D) UAC.")
70
Question # 6 If the amino acid sequence below is produced, what would be the corresponding DNA sequence? cysteine - tryptophan - proline - glycine (A) ACA ACC GGC CCC (B) ACA ACT GAA TAG (C) ACG ACC GGG TAC (D) ACG ACT GCG GAG
 ACA ACC GGC CCC. (B) ACA ACT GAA TAG. (C) ACG ACC GGG TAC. (D) ACG ACT GCG GAG.")
71
Hormonal and Environmental Factors on Gene Expression
Textbook Reference: Section 17.4, Pgs Some environmental factors can switch genes “on” or “off”. They may include: light, changes in temperature and diet. As a result, certain proteins may or may not be produced to express a particular phenotype.

72
Some effects of the environment on genes expression may include differences in:
a. Identical Twins: Since identical twins have the same genotype, differences may be attributed to the environment. Differences may appear in intelligence, personality and skills. b. Color of Fur in Himalayan Rabbits due to temperature: The rabbit has mostly white fur. When body temperature falls below 33C the gene that produces black pigment is turned on. c. Sex of offspring in reptiles due to incubation period: In painted turtle, high incubation temperature produces more females while low incubation temperatures produces more males.

73
D. Color of Arctic Fox: These foxes are white in the winter but as the temperature warms it triggers the synthesis of polypeptides that produce a brown pigment in the fur. E. Male Slipper Limpet: The male can turn into a female when surrounded by other males F. Warm temperatures can cause plants to germinate and cool temperatures can cause them to be dormant

74
G. Bright lights can trigger proteins that cause wakefulness in animals and proteins involved in photosynthesis in plants H. Presence or absence of nutrients in the Environment: E. coli can produce more lactose when in the presence of high amounts of lactose in the environment. On the contrary, they can produce less tryptophan when there are high amounts in their environment.

75
Gene Expression in Development
Different genes must be active in different stages of an organism’s life cycle. (For example, the development of secondary sex characteristics in humans). Development may involve the production of different enzymes or hormones. Homeobox genes or hox genes in humans are responsible for development by switching other genes on or off. They operate by producing a protein that affects transcription. Oncogenes are genes that cause some kinds of cancers. They are normally switched off.
. Development may involve the production of different enzymes or hormones. Homeobox genes or hox genes in humans are responsible for development by switching other genes on or off. They operate by producing a protein that affects transcription. Oncogenes are genes that cause some kinds of cancers. They are normally switched off.")
76
Textbook References: Section 17.4, pgs Section 16.3, pgs Section pgs Mutations A mutation is an error or change in the replication of the genetic material (DNA) that becomes a part of the genotype of the cells and its dependents. A mutation may have no real effect, it may be detrimental or it may be beneficial to an organism and its descendents.
 that becomes a part of the genotype of the cells and its dependents. A mutation may have no real effect, it may be detrimental or it may be beneficial to an organism and its descendents.")
77
Causes of Mutations a. There is no known cause for natural or spontaneous mutations. They may be a result of random errors in the replication of DNA. b. Mutagens are factors in the environment that cause mutations. Examples of some mutagens may include: (i) Radiation from x-rays or UV light (ii) Chemicals such as chloroform, mustard gas, benzene, formaldehyde, pesticides, weed killers, and food additives (iii) High temperature (iv) Viruses
 Radiation from x-rays or UV light. (ii) Chemicals such as chloroform, mustard gas, benzene, formaldehyde, pesticides, weed killers, and food additives. (iii) High temperature. (iv) Viruses.")
78
Types of Mutations a. Somatic Mutations: Occur in somatic cells (body cells) and they can not be passed on to the offspring. (mitosis) b. Germ Mutations: Occur during meiosis (gamete production) and thus such mutations can be passed on to the offspring. c. Chromosomal Mutations: May occur in the somatic or germ cells. This is a mutation to all or part of a chromosome or may cause a change in the number of chromosomes. d. Gene Mutation: May occur in somatic or germ cells. This is a change in the gene on a chromosome.
 and thus such mutations can be passed on to the offspring. c. Chromosomal Mutations: May occur in the somatic or germ cells. This is a mutation to all or part of a chromosome or may cause a change in the number of chromosomes. d. Gene Mutation: May occur in somatic or germ cells. This is a change in the gene on a chromosome.")
79
Types of Chromosomal Mutations (page 550, Figure 16.27)
a. Deletion: Occurs when a piece of chromosome breaks off, resulting in the loss of some genes. For example, “cri du chat” syndrome is a deletion in the fifth largest chromosome. b. Duplication: (Addition) This is when a piece of chromosome breaks off and attaches to a homologous chromosome. The homologous chromosome will have some genes repeated. In fragile X syndrome in males, there are 700 repeats.
 This is when a piece of chromosome breaks off and attaches to a homologous chromosome. The homologous chromosome will have some genes repeated. In fragile X syndrome in males, there are 700 repeats.")
80
C. Inversion: This occurs when a piece of chromosome is rotated and thus reverses the order of the genes in that segment. Some genes participate in a common function. If these genes are separated by an inversion, they may not be able to function properly. This is believed to be the cause of some forms of autism. D. Translocation: This is the transfer of a part of a chromosome to a non-homologous chromosome. This can explain some forms of cancer such as leukemia and some forms of Down’s syndrome.

81
E. Nondisjunction: This is the addition or loss of a whole chromosome and occurs during meiosis. In this case homologous chromosomes or sister chromatids stay together. Trisomy is the condition in which a cell has one extra chromosome. If a cell is missing one chromosome, the condition is known as monsomy. Monosomy is usually lethal. Why? (Because the cell lacks genetic material) Conditions caused by nondisjunction in humans include: Down’s syndrome (trisomy 21), Turner’s syndrome (XO), and Klinefelters syndrome (XYY).
 Conditions caused by nondisjunction in humans include: Down’s syndrome (trisomy 21), Turner’s syndrome (XO), and Klinefelters syndrome (XYY)..")
82
F. Polyploidy: The condition that results in an organism having an extra set of chromosomes. This occurs when a nucleus does not undergo the second meiotic division. The gametes become 2n instead of n. The zygote becomes 3n. This is common in plants but lethal in animals.

85
Types of Gene Mutations
Gene mutations may change the particular amino acid the triplet represents and thereby changing the overall shape and function of a protein. ie. sickle-cell anemia Point Mutations: May involve the substitution of one nucleotide for another, or the insertion or deletion of one or more nucleotides. There are two types of point mutations:

86
Silent: has no effect on the cell’s metabolism
A. Substitution: A mutation in which one base replaces another in the DNA chain. The old dog ran and the fox did too The old hog ran and the fox did too Silent: has no effect on the cell’s metabolism Mis-sense: creates a slightly altered but functional protein: may be harmful or beneficial Nonsense: the gene is unable to code for any functional protein: severe consequences

87
B. Frame-shift mutation: A mutation in which a base deletion or base insertion causes the gene’s message to be translated incorrectly. Base Insertion: A mutation in which an extra nucleotide base is added to the DNA sequence. The entire message may be translated incorrctly. The old dog ran and the fox did too The old dog ran tan dth efo xdi dto o Base Deletion: A mutation in which a nucleotide base is lost from the DNA sequence. Again the entire message may be translated incorrectly. The old dog rna ndt hef oxd idt oo

88
Jumping Gene Theory Most genes have a specific location on the chromosome. A geneticist named Barbara McClintock discovered genes that can move from position to position on a chromosome or move from chromosome to chromosome. They are called “jumping genes” or transposons. Jumping genes are considered to be a form of mutation and another source of genetic variation. Jumping genes explain the random pattern of colors in the kernel of Indian corn. It can also explain the development of new species.

Similar presentations
















>")

>")






 Nucleic acid that composes chromosomes and carries genetic information.>")
