Download presentation
Presentation is loading. Please wait.

1
PANEL DATA 1. Dummy Variable Regression 2. LSDV Estimator
3. Panel Data Fixed Effects Estimator 4. Panel Data Random Effects Estimator

2
Suppose our model is: Yi = + Xi + i
Using Group Dummies Suppose our model is: Yi = + Xi + i There are two categories: Di = { 1 if i belongs to group 1 0 otherwise We run the regression: Yi = 1 + 2Di + 1Xi + 2DiXi + i In interpreting the results, we should read two regressions: Yi = (1+2) + (1+2)Xi + i for group 1 Yi = 1 + 1Xi + i for group 0 If 2 ≠ 0 , then Yi for group 1 has a different mean If 2 ≠ 0 , then Yi for group 1 has a different sensitivity to X
 + (1+2)Xi + i for group 1. Yi = 1 + 1Xi + i for group 0. If 2 ≠ 0 , then Yi for group 1 has a different mean. If 2 ≠ 0 , then Yi for group 1 has a different sensitivity to X.")
3
LSDV Model

4
If category (individual) effects are significant, then ei,t is not white noise (correlated with ei,t-1 and/or Xi,t) which means OLS without dummies is biased and inconsistent. For this reason, we may fail to find a significant relationship between Y and X1.

5
If you control for group effects, however, you will get unbiased results.

6
Fixed Effects Panel Estimator
An equivalent approach to the dummy variables pooled OLS estimator is the Fixed Effects (FE) estimator (it produces identical results). FE estimator is useful when we have a very large number of cross-sectional units (so that creating so many dummy variables would overcrowd the regression equation).
 estimator (it produces identical results). FE estimator is useful when we have a very large number of cross-sectional units (so that creating so many dummy variables would overcrowd the regression equation).")
10
LSDV and Panel Data FE Models will provide identical results:

11
Understanding the Procedure of the FE Estimator
1) For each group calculate group average over time. 2) Obtain the time-demeaned data: 3) Run the regression on time-demeaned data: Now, the error term is white noise. Hence, the FE estimator is unbiased.
 For each group calculate group average over time. 2) Obtain the time-demeaned data: 3) Run the regression on time-demeaned data: Now, the error term is white noise. Hence, the FE estimator is unbiased.")
12
STATA Fixed Effects Model Output

13
Random Effects (RE) estimator would be useful if some explanatory variables remain constant over time. It assumes that group effects are uncorrelated with regressors, hence it must be checked whether this assumption is satisfied. Fixed Effects (FE) estimator measures the relationship based on time variation within a cross-sectional unit. Between Effects (BE) estimator measures the relationship based on cross-sectional variation at each time period. Random Effects (RE) estimator is a weighted average of the two.
 estimator measures the relationship based on time variation within a cross-sectional unit. Between Effects (BE) estimator measures the relationship based on cross-sectional variation at each time period. Random Effects (RE) estimator is a weighted average of the two.")
16
Understanding the Procedure of the RE Estimator
1) For each group calculate group average over time. (as before) 2) Obtain the quasi-demeaned data: where 3) Run the regression on quasi-demeaned data: Again, the error term is white noise. Hence, the RE estimator is unbiased.
 For each group calculate group average over time. (as before) 2) Obtain the quasi-demeaned data: where. 3) Run the regression on quasi-demeaned data: Again, the error term is white noise. Hence, the RE estimator is unbiased.")
17
H0: difference in FE and RE is not systematic HA: RE cannot be used
Usually, one needs to apply all of the FE, BE, RE estimators, respectively, to gain insight on which models is the most appropriate. Recall: RE is consistent only if Cov (Xi, ui) = 0. Under H0 (below), RE is more efficient than FE. Hausman Test: H0: difference in FE and RE is not systematic HA: RE cannot be used STATA commands: xtreg r f e, fe estimates store fixed xtreg r f e, re estimates store random hausman fixed random (Hausman test is not available in menu)
 = 0. Under H0 (below), RE is more efficient than FE. Hausman Test: H0: difference in FE and RE is not systematic. HA: RE cannot be used. STATA commands: xtreg r f e, fe. estimates store fixed. xtreg r f e, re. estimates store random. hausman fixed random. (Hausman test is not available in menu)")
Similar presentations

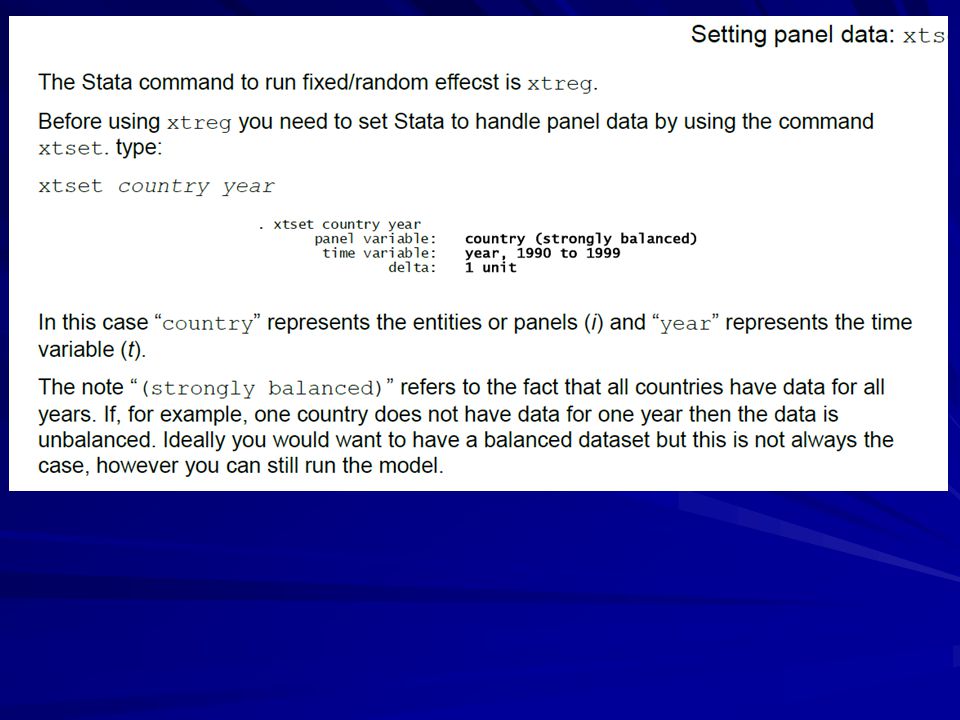












>")



 Advanced Panel Data Method>")



 = 0.>")


