Download presentation
Presentation is loading. Please wait.

1
Panel Data Models Prepared by Vera Tabakova, East Carolina University

2
15.1 Grunfelds Investment Data 15.2 Sets of Regression Equations 15.3 Seemingly Unrelated Regressions 15.4 The Fixed Effects Model 15.4 The Random Effects Model

3
The different types of panel data sets can be described as: long and narrow, with long describing the time dimension and narrow implying a relatively small number of cross sectional units; short and wide, indicating that there are many individuals observed over a relatively short period of time; long and wide, indicating that both N and T are relatively large.

4
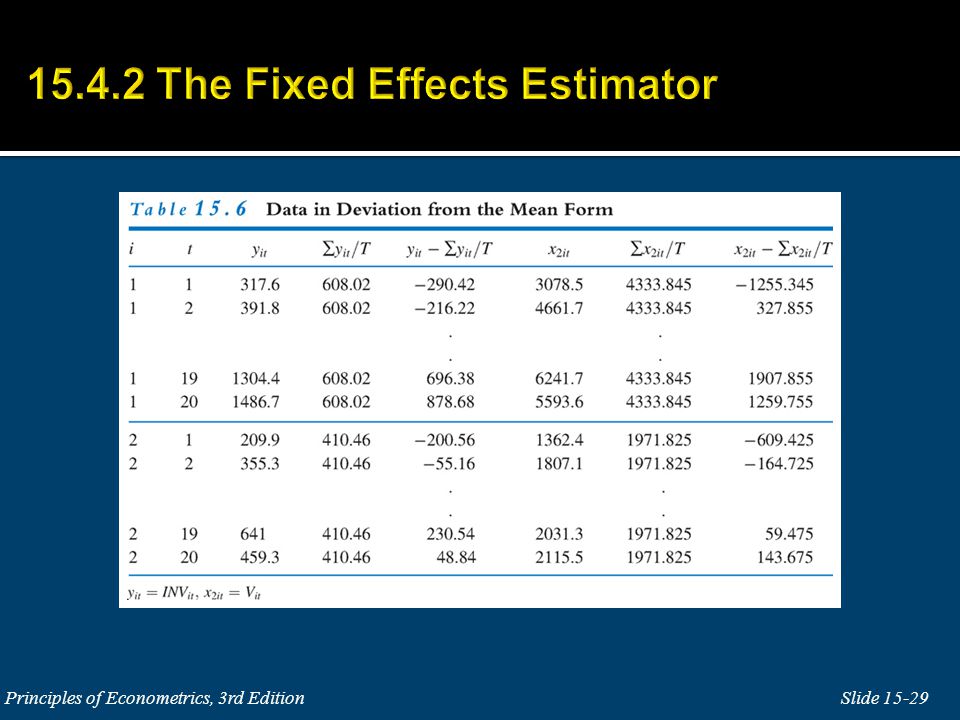
The data consist of T = 20 years of data (1935-1954) for N = 10 large firms. Let y it = INV it and x 2it = V it and x 3it = K it

7
Assumption (15.5) says that the errors in both investment functions (i) have zero mean, (ii) are homoskedastic with constant variance, and (iii) are not correlated over time; autocorrelation does not exist. The two equations do have different error variances

9
Let D i be a dummy variable equal to 1 for the Westinghouse observations and 0 for the General Electric observations.

11
This assumption says that the error terms in the two equations, at the same point in time, are correlated. This kind of correlation is called a contemporaneous correlation.

12
Econometric software includes commands for SUR (or SURE) that carry out the following steps: (i) Estimate the equations separately using least squares; (ii) Use the least squares residuals from step (i) to estimate ; (iii) Use the estimates from step (ii) to estimate the two equations jointly within a generalized least squares framework.
 that carry out the following steps: (i) Estimate the equations separately using least squares; (ii) Use the least squares residuals from step (i) to estimate ; (iii) Use the estimates from step (ii) to estimate the two equations jointly within a generalized least squares framework.")
14
There are two situations where separate least squares estimation is just as good as the SUR technique : (i) when the equation errors are not contemporaneously correlated; (ii) when the same explanatory variables appear in each equation. If the explanatory variables in each equation are different, then a test to see if the correlation between the errors is significantly different from zero is of interest.

15
In this case

16
Testing for correlated errors for two equations: LM = 10.628 > 3.84 Hence we reject the null hypothesis of no correlation between the errors and conclude that there are potential efficiency gains from estimating the two investment equations jointly using SUR.

17
Testing for correlated errors for three equations:

18
Testing for correlated errors for M equations: Under the null hypothesis that there are no contemporaneous correlations, this LM statistic has a χ 2 -distribution with M(M–1)/2 degrees of freedom, in large samples.
/2 degrees of freedom, in large samples.")
19
Most econometric software will perform an F-test and/or a Wald χ 2 –test; in the context of SUR equations both tests are large sample approximate tests. The F-statistic has J numerator degrees of freedom and (MT K) denominator degrees of freedom, where J is the number of hypotheses, M is the number of equations, and K is the total number of coefficients in the whole system, and T is the number of time series observations per equation. The χ 2 -statistic has J degrees of freedom.
 denominator degrees of freedom, where J is the number of hypotheses, M is the number of equations, and K is the total number of coefficients in the whole system, and T is the number of time series observations per equation. The χ 2 -statistic has J degrees of freedom..")
20
We cannot consistently estimate the 3×N×T parameters in (15.9) with only NT total observations.
 with only NT total observations.")
21
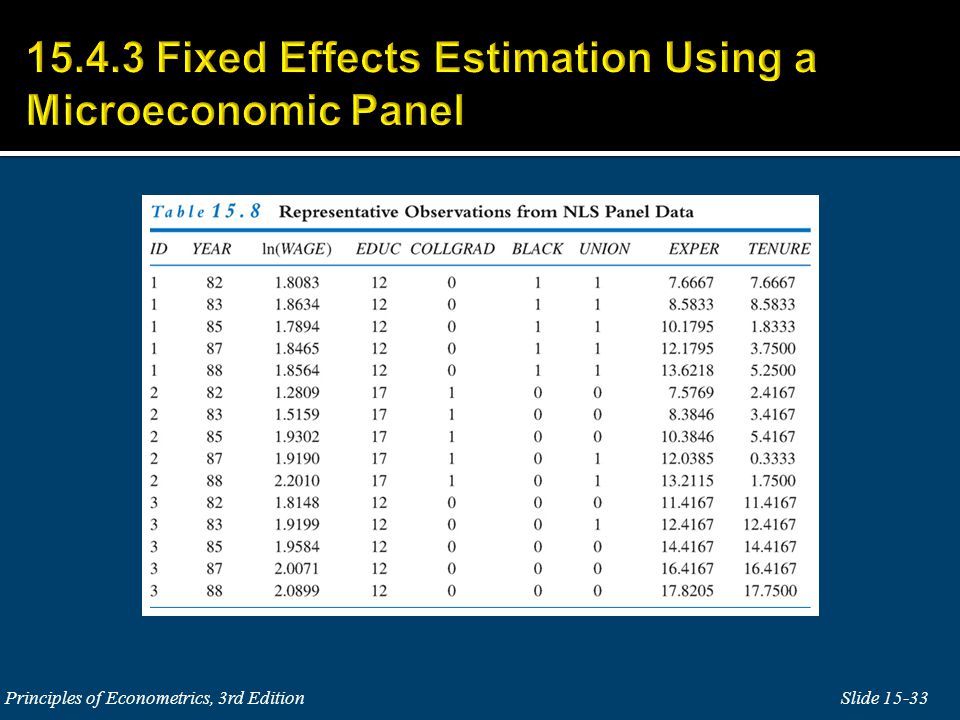
All behavioral differences between individual firms and over time are captured by the intercept. Individual intercepts are included to control for these firm specific differences.

22
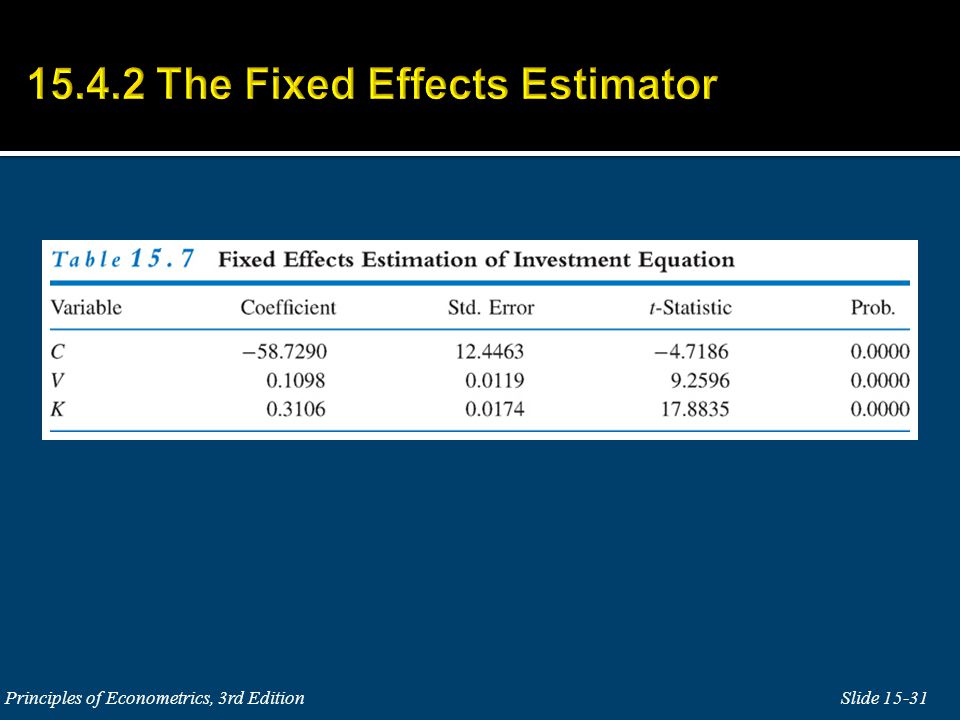
This specification is sometimes called the least squares dummy variable model, or the fixed effects model.

24
These N–1= 9 joint null hypotheses are tested using the usual F-test statistic. In the restricted model all the intercept parameters are equal. If we call their common value β 1, then the restricted model is:

26
We reject the null hypothesis that the intercept parameters for all firms are equal. We conclude that there are differences in firm intercepts, and that the data should not be pooled into a single model with a common intercept parameter.

36
Because the random effects regression error in (15.24) has two components, one for the individual and one for the regression, the random effects model is often called an error components model.
 has two components, one for the individual and one for the regression, the random effects model is often called an error components model.")
38
There are several correlations that can be considered. The correlation between two individuals, i and j, at the same point in time, t. The covariance for this case is given by

39
The correlation between errors on the same individual (i) at different points in time, t and s. The covariance for this case is given by

40
The correlation between errors for different individuals in different time periods. The covariance for this case is

45
If the random error is correlated with any of the right- hand side explanatory variables in a random effects model then the least squares and GLS estimators of the parameters are biased and inconsistent.

48
We expect to find because Hausman proved that

49
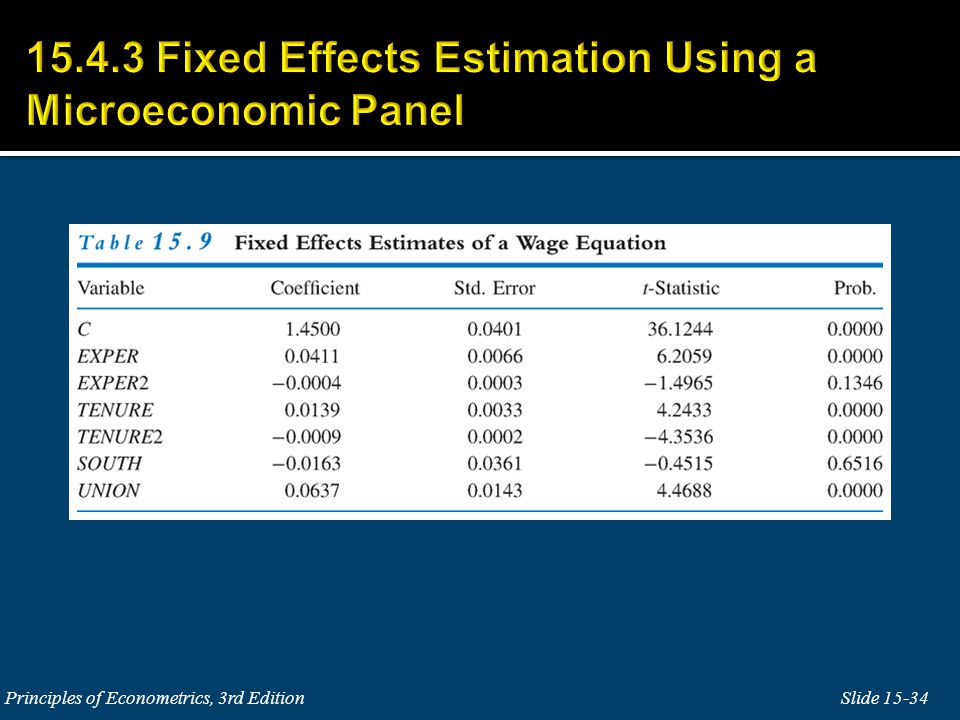
The test statistic to the coefficient of SOUTH is: Using the standard 5% large sample critical value of 1.96, we reject the hypothesis that the estimators yield identical results. Our conclusion is that the random effects estimator is inconsistent, and we should use the fixed effects estimator, or we should attempt to improve the model specification.

50
Slide 15-50 Principles of Econometrics, 3rd Edition Balanced panel Breusch-Pagan test Cluster corrected standard errors Contemporaneous correlation Endogeneity Error components model Fixed effects estimator Fixed effects model Hausman test Heterogeneity Least squares dummy variable model LM test Panel corrected standard errors Pooled panel data regression Pooled regression Random effects estimator Random effects model Seemingly unrelated regressions Unbalanced panel

51
Slide 15-51 Principles of Econometrics, 3rd Edition

52
Slide 15-52 (15A.1) (15A.2) (15A.3)
 (15A.2) (15A.3)")
53
Principles of Econometrics, 3rd Edition Slide 15-53 (15A.4) (15A.5)
 (15A.5)")
54
Principles of Econometrics, 3rd Edition Slide 15-54 (15A.6) (15A.7)
 (15A.7)")
Similar presentations