Download presentation
Presentation is loading. Please wait.

1
On adaptive time-dependent DMRG based on Runge-Kutta methods
On adaptive time-dependent DMRG based on Runge-Kutta methods* Adrian Feiguin University of California, Irvine Outline: Review: DMRG Targeting and DMRG Time evolution using Suzuki-Trotter An efficient targeting scheme for 2D / long-range interactions Examples: Real-time Green's functions, Thermodynamic DMRG Collaborator: Steve R. White, UC Irvine * A.E. Feiguin, S.R. White, Submitted to PRB (2005)
")
2
Density Matrix Renormalization Group
S.R. White, Phys. Rev. Lett. 69, 2863(1992), Phys. Rev. B 48, (1993) Can we rotate our basis to one where the weights are more concentrated, to minimize the error? Cut here |gs =∑ ai|xi , ∑ |ai|2 = 1 => Error = 1-∑' |ai|2 Cut here
, Phys. Rev. B 48, (1993) Can we rotate our basis to one where the weights are more concentrated, to minimize the error Cut here. |gs =∑ ai|xi , ∑ |ai|2 = 1. => Error = 1-∑ |ai|2. Cut here.")
3
The density matrix projection
superblock (universe) system |i environment |j |y = ∑ijyij|i|j We need to find the state |y' = ∑majaaj|ua |j that minimizes the distance S=||y' -|y|2 Solution: The optimal states are the eigenvectors of the reduced density matrix with the largest eigenvalues wa rii' = ∑jy*ijyi'j ; Tr r = 1
 system. |i environment. |j |y = ∑ijyij|i|j We need to find the state |y = ∑majaaj|ua |j that minimizes the distance. S=||y -|y|2. Solution: The optimal states are the eigenvectors of the reduced density matrix with the largest eigenvalues wa. rii = ∑jy*ijyi j ; Tr r = 1.")
4
… ans so on, until we converge…
The Algorithm How do we build the reduced basis of states? We grow our basis systematically, adding sites to our system at each step, and using the density matrix projection to truncate We sweep from left to right We sweep from right to left We grow the system by adding sites and applying the density matrix projection to truncate the basis until reaching the desired size We start from a small superblock with 4 sites/blocks, each with a dimension mi , small enough to be easily diagonalized 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 … ans so on, until we converge…

5
Targeting states If we target the ground state only, we cannot expect to have a good representation of excited states (dynamics). If the error is strictly controlled by the DMRG truncation error, we say that the algorithm is “quasiexact”. Non quasiexact algorithms seem to be the source of almost all DMRG “mistakes”. For instance, the infinite system algorithm applied to finite systems is not quasiexact.

6
Time evolution: Suzuki-Trotter approach*
... H= H H H H H H6 HA= H H H6 HB= H H H5 ... So the time-evolution operator is a product of individual link terms. *G. Vidal, PRL (2004)
")
7
One sweep evolves one time step
Time dependent DMRG S.R.White and A.E. Feiguin, PRL (2004), Daley et al, J. Stat. Mech.: Theor. Exp. (2004) We turn off the diagonalization and start applying the evolution operator We start with the finite system algorithm to obtain the ground state 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 e-iτHij e-iτHij e-iτHij e-iτHij e-iτHij One sweep evolves one time step Each link term only involves two-sites interactions => small matrix, easy to calculate!
, Daley et al, J. Stat. Mech.: Theor. Exp. (2004) We turn off the diagonalization and start applying the evolution operator. We start with the finite system algorithm to obtain the ground state e-iτHij. e-iτHij. e-iτHij. e-iτHij. e-iτHij. One sweep evolves one time step. Each link term only involves two-sites interactions => small matrix, easy to calculate!")
8
Real-time dynamics using Runge-Kutta
We need to solve:

9
Time evolution and DMRG
Some history: Cazalilla and Marston, PRL 88, (2002). Use the infinite system method to find the ground state, and evolved in time using this fixed basis without sweeps. This is not quasiexact. However, they found that works well for transport in chains for short to moderate time intervals. t=0 t= τ t=2τ t=3τ t=4τ Luo, Xiang and Wang, PRL 91, (2003) showed how to target correctly for real-time dynamics. They target ψ(t=0), ψ(t=τ) , ψ(t=2τ) , ψ(t=3τ)… t=0 t= τ t=2τ t=3τ t=4τ This is quasiexact as τ→0 if you add sweeping. The problem with this idea is that you keep track of all the history of the time-evolution, requiring large number of states m. It becomes highly inefficient.
. Use the infinite system method to find the ground state, and evolved in time using this fixed basis without sweeps. This is not quasiexact. However, they found that works well for transport in chains for short to moderate time intervals. t=0. t= τ. t=2τ. t=3τ. t=4τ. Luo, Xiang and Wang, PRL 91, (2003) showed how to target correctly for real-time dynamics. They target. ψ(t=0), ψ(t=τ) , ψ(t=2τ) , ψ(t=3τ)… t=0. t= τ. t=2τ. t=3τ. t=4τ. This is quasiexact as τ→0 if you add sweeping. The problem with this idea is that you keep track of all the history of the time-evolution, requiring large number of states m. It becomes highly inefficient.")
10
Time-step targeting method Feiguin and White, submitted to PRB, Rapid Comm.
To fix these problems, White and I have developed a new approach: We target one time step accurately, then we move to the next step. The targeting principle is that of Luo et al. , but instead of keeping track of the whole history, we keep track of intermediate points between t and t+τ t=4τ t=0 t=τ t=2τ t=3τ The time-evolution can be implemented in various ways: 1) Calculate Lanczos (tri-diagonal) matrix, and exponentiate. (time consuming) 2) Runge-Kutta.
 Calculate Lanczos (tri-diagonal) matrix, and exponentiate. (time consuming) 2) Runge-Kutta.")
11
Time-step targeting method (continued)
")
12
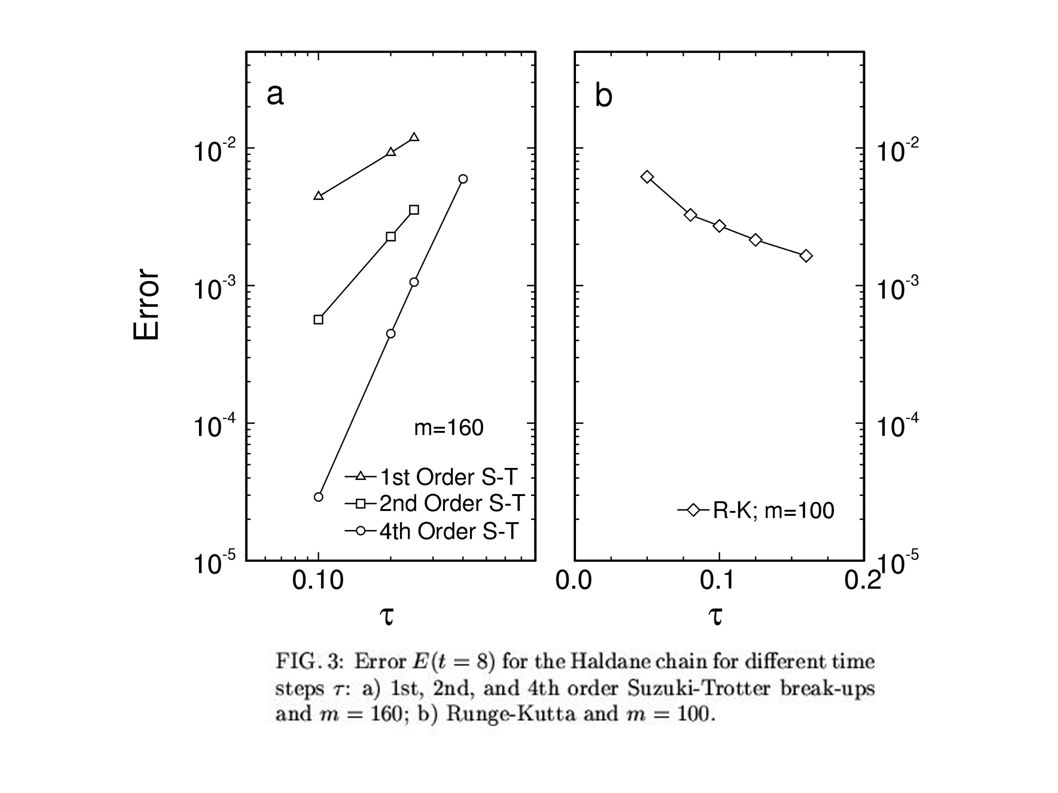
S=1 Heisenberg chain (L=32; t=8)
time targeting+RK 1st order S-T 4th order S-T

14
Fixed error, variable number of states

15
Time dependent correlation functions (Example: S=1 Heisenberg chain)
")
16
S=1/2 Heisenberg ladder 2xL (L=32)
")
17
System coupled to a spin bath V. Dobrovitski et al, PRL (2003), A
System coupled to a spin bath V. Dobrovitski et al, PRL (2003), A. Melikidze et al PRB (2004) |y(t=0)=||c0; |c0c0|=I ... H=HS+ HB+ VSB
, A. Melikidze et al PRB (2004) |y(t=0)=||c0; |c0c0|=I. ... H=HS+ HB+ VSB.")
18
Comparing S-T and time step targeting
S-T is fast and efficient for one-dimensional geometries with nearest neighbor interactions S-T error depends strongly on the Trotter error but it can be reduced by using higher order expansions. Time step targeting (RK) can be applied to ladders and systems with long range interactions It has no Trotter error, but is less efficient.
 can be applied to ladders and systems with long range interactions. It has no Trotter error, but is less efficient.")
19
Evolution in imaginary time *,**
Thermo-field representation*: O(β)|O(β) |O(β)=e-βH/2 |I; Z(β)=O(β)|O(β) where |I is the maximally mixed state for β=0 (T=∞) (thermal vacuum) Evolution in imaginary time is equivalent to evolving the maximally mixed state in imaginary time. We can do so by solving -2 *Takahashi and Umezawa, Collect Phenom. 2, 55 (1975), ** Verstraete PRL 2004, Zwolak PRL 2004
|O(β) |O(β)=e-βH/2 |I; Z(β)=O(β)|O(β) where |I is the maximally mixed state for β=0 (T=∞) (thermal vacuum) Evolution in imaginary time is equivalent to evolving the maximally mixed state in imaginary time. We can do so by solving. -2. *Takahashi and Umezawa, Collect Phenom. 2, 55 (1975), ** Verstraete PRL 2004, Zwolak PRL")
20
CM: thermofield representation, QI: mixed state purification
Maximally mixed state for β=0 (T=∞) CM: thermofield representation, QI: mixed state purification |I =∑|n,ñ (auxiliary field ñ is called ancilla state) with |n= |s1 s2 s3…sN 2N states!!! |I=|↑↑,↑↑+|↓↓,↓↓+|↑↓,↑↓+|↓↑,↓↑ each term can be re-written as a product of local “site-ancilla” states: |I=|↑,↑|↑,↑+|↓,↓|↓,↓+|↑,↑|↓,↓+|↓,↓|↑,↑ after a “particle-hole” transformation on the ancilla we get |I=|I0|I0 with |I0= |↑,↓+|↓,↑ → only one product state! and we can work in the subspace with Sz=0!!!
 CM: thermofield representation, QI: mixed state purification. |I =∑|n,ñ (auxiliary field ñ is called ancilla state) with |n= |s1 s2 s3…sN 2N states!!! |I=|↑↑,↑↑+|↓↓,↓↓+|↑↓,↑↓+|↓↑,↓↑ each term can be re-written as a product of local site-ancilla states: |I=|↑,↑|↑,↑+|↓,↓|↓,↓+|↑,↑|↓,↓+|↓,↓|↑,↑ after a particle-hole transformation on the ancilla we get. |I=|I0|I0 with |I0= |↑,↓+|↓,↑ → only one product state! and we can work in the subspace with Sz=0!!!")
21
In DMRG language this looks like:
In this basis, left and right block have only one state! As we evolve in time, the size of the basis will grow.

22
Thermodynamics of the spin-1/2 chain L=64

23
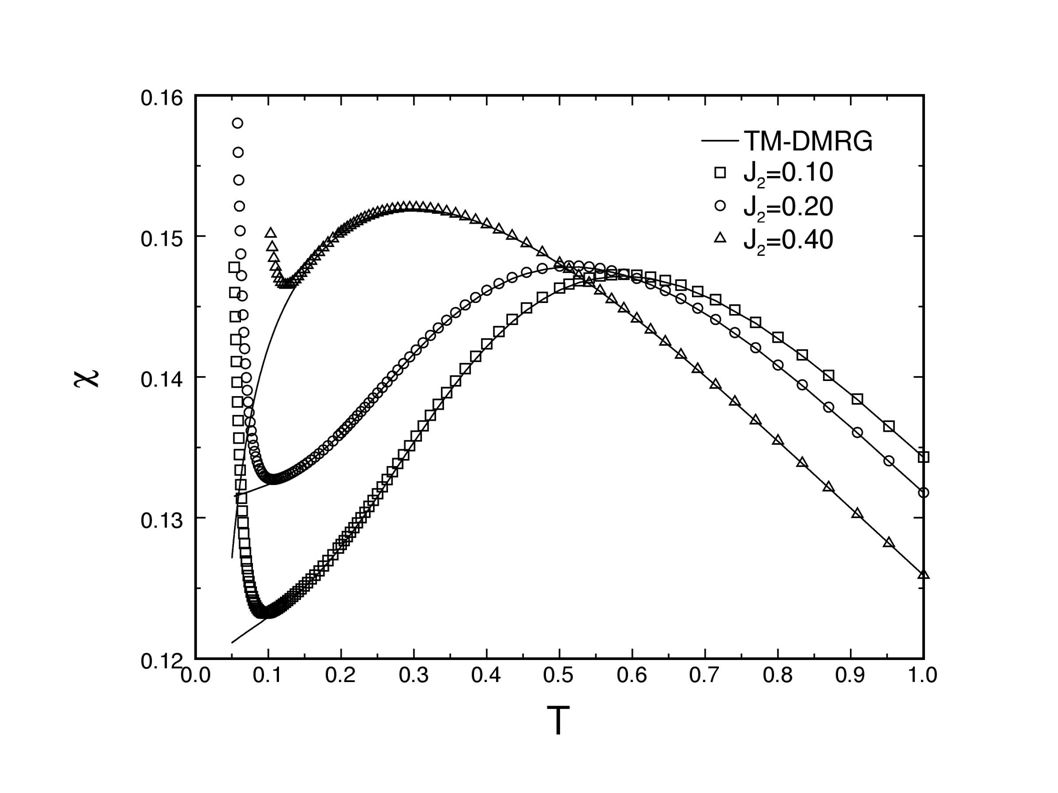
Frustrated Heisenberg chain*
* TM-DMRG results from Wang and Xiang, PRB 97; Maisinger and Schollwoeck, PRL 98.

25
Conclusions If your DMRG program incorporates wavefunction transformations, time-dependent DMRG is easy to implement. Time-targeting method allows to study 2D and systems with long-range interactions. Error is dominated by the DMRG truncation error. Care must be taken in order to control it by keeping more states. Generalization to finite temperature (imaginary time) is straightforward.
 is straightforward.")
Similar presentations















>")

 Multiscale Entanglement.>")

 Miami 2009.>")