Download presentation
Presentation is loading. Please wait.

1
Nonnegative Matrix Factorization with Sparseness Constraints S. Race MA591R

2
Introduction to NMF Factor A = WH A – matrix of data m non-negative scalar variables n measurements form the columns of A W – m x r matrix of basis vectors H – r x n coefficient matrix Describes how strongly each building block is present in measurement vectors

3
Introduction to NMF cont Purpose: parts-based representation of the data Data compression Noise reduction Examples: Term – Document Matrix Image processing Any data composed of hidden parts

4
Introduction to NMF cont Optimize accuracy of solution: min || A-WH || F where W,H 0 We can drop nonnegative constraints min || A-(W.W)(H.H) || Many options for objective function Many options for algorithm W,H will depend on initial choices Convergence is not always guaranteed
(H.H) || Many options for objective function Many options for algorithm W,H will depend on initial choices Convergence is not always guaranteed")
5
Common Algorithms Alternating Least Squares Paatero 1994 Multiplicative Update Rules Lee-Seung 2000 Nature Used by Hoyer Gradient Descent Hoyer 2004 Berry-Plemmons 2004

6
Why is sparsity important? Nature of some data Text-mining Disease patterns Better Interpretation of Results Storage concerns

7
Non-negative Sparse Coding I Proposed by Patrik Hoyer in 2002 Add a penalty function to the objective to encourage sparseness OBJ: Parameter λ controls trade-off between accuracy and sparseness f is strictly increasing: f=Σ H ij works

8
Sparse Objective Function The objective can always be decreased by scaling W up, H down Set W= cW and H=(1/c)H Thus, alone the objective will simply yield the NMF solution Constraint on the scale of H or W is needed Fix norm of columns of W or rows of H
H Thus, alone the objective will simply yield the NMF solution Constraint on the scale of H or W is needed Fix norm of columns of W or rows of H")
9
Non-negative Sparse Coding I Pros Simple, efficient Guaranteed to reach global minimum using multiplicative update rule Cons Sparseness controlled implicitly: Optimal λ found by trial and error Sparseness only constrained for H

10
NMF with sparseness constraints II First need some way to define the sparseness of a vector A vector with one nonzero entry is maximally sparse A multiple of the vector of all ones, e, is minimally sparse CBS Inequality How can we combine these ideas?

11
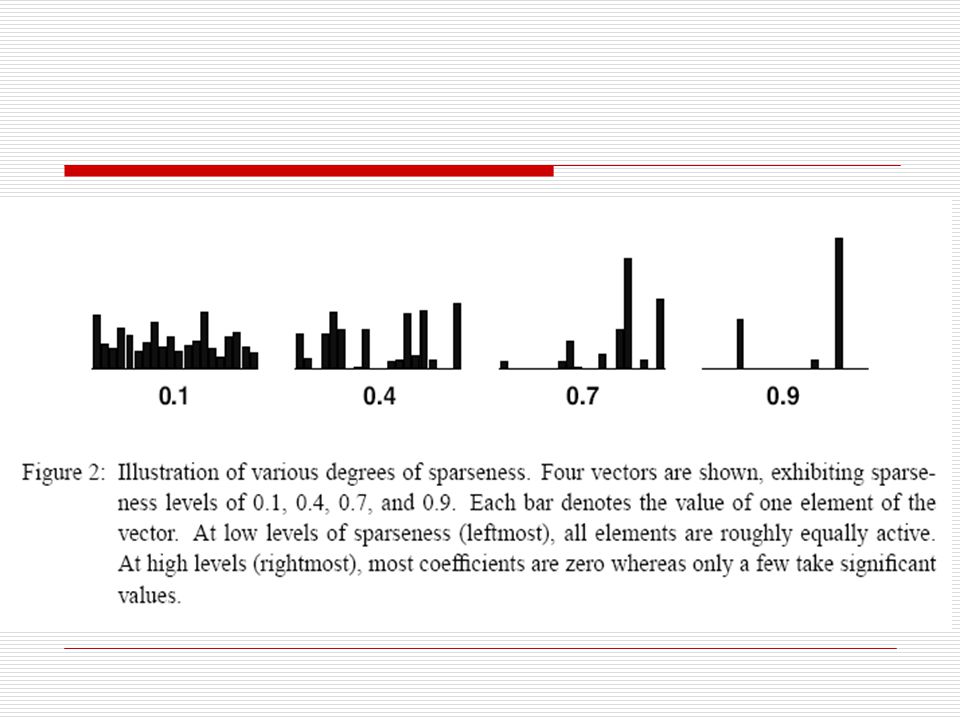
Hoyers Sparseness Parameter sparseness(x)= where n is the dimensionality of x This measure indicates that we can control a vectors sparseness by manipulating its L1 and L2 norms
= where n is the dimensionality of x This measure indicates that we can control a vectors sparseness by manipulating its L1 and L2 norms")
13
Picture of Sparsity function for vectors w/ n=2

14
Implementing Sparseness Constraints Now that we have an explicit measure of sparseness, how can we incorporate it into the algorithm? Hoyer: at each step, project each column of a matrix onto the nearest vector of desired sparseness.

15
Hoyers Projection Algorithm Problem: Given any vector, x, find the closest (in the Euclidean sense) non-negative vector s with a given L 1 norm and a given L 2 norm We can easily solve this problem in the 3 dimensional case and extend the result.
 non-negative vector s with a given L 1 norm and a given L 2 norm We can easily solve this problem in the 3 dimensional case and extend the result.")
16
Hoyers Projection Algorithm Set s i =x i + (L 1 -Σx i )/n for all i Set Z={} Iterate Set m i =L 1 /(n-size(Z)) if i in Z, 0 otherwise Set s=m+β(s-m) where β0 solves quadratic If s, non-negative were finished Set Z=Z U {i : s i <0} Set s i =0 for all i in Z Calculate c=(Σs i – L 1 )/(n-size(Z)) Set s i =s i -c for all i not in Z
/n for all i Set Z={} Iterate Set m i =L 1 /(n-size(Z)) if i in Z, 0 otherwise Set s=m+β(s-m) where β0 solves quadratic If s, non-negative were finished Set Z=Z U {i : s i <0} Set s i =0 for all i in Z Calculate c=(Σs i – L 1 )/(n-size(Z)) Set s i =s i -c for all i not in Z")
17
The Algorithm in words Project x onto hyperplane Σs i =L 1 Within this space, move radially outward from center of joint constraint hypersphere toward point If result non-negative, destination reached Else, set negative values to zero and project to new point in similar fashion

18
NMF with sparseness constraints Step 1: Initialize W, H to random positive matrices Step 2: If constraints apply to W or H or both, project each column or row respectively to have unchanged L 2 norm and desired L 1 norm

19
NMF w/ Sparseness Algorithm Step 3: Iterate If sparseness constraints on W apply, Set W=W-μ w (WH-A)H T Project columns of W as in step 2 Else, take standard multiplicative step If sparseness constraints on H apply Set H=H- μ H W T (WH-A) Project rows of H as in step 2 Else, take standard multiplicative step
H T Project columns of W as in step 2 Else, take standard multiplicative step If sparseness constraints on H apply Set H=H- μ H W T (WH-A) Project rows of H as in step 2 Else, take standard multiplicative step")
20
Advantages of New Method Sparseness controlled explicitly with a parameter that is easily interpretted Sparseness of W, H or both can be constrained Number of iterations required grows very slowly with the dimensionality of the problem

21
Dotted Lines Represent Min and Max Iterations Solid Line shows average number required

22
An Example from Hoyers Work

23
Text Mining Results Text to Matrix Generator Dimitrios Zeimpekis and E. Gallopoulos Dimitrios ZeimpekisE. Gallopoulos University of Patras http://scgroup.hpclab.ceid.upatras.gr/sc group/Projects/TMG/ http://scgroup.hpclab.ceid.upatras.gr/sc group/Projects/TMG/ NMF with sparseness constraints from Hoyers web page

Similar presentations











 Alberto Pascual-Montano, Member, IEEE, J.M. Carazo, Senior Member, IEEE, Kieko Kochi, Dietrich Lehmann,>")






 Slides are from RPI Registration Class.>")
 by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley.>")