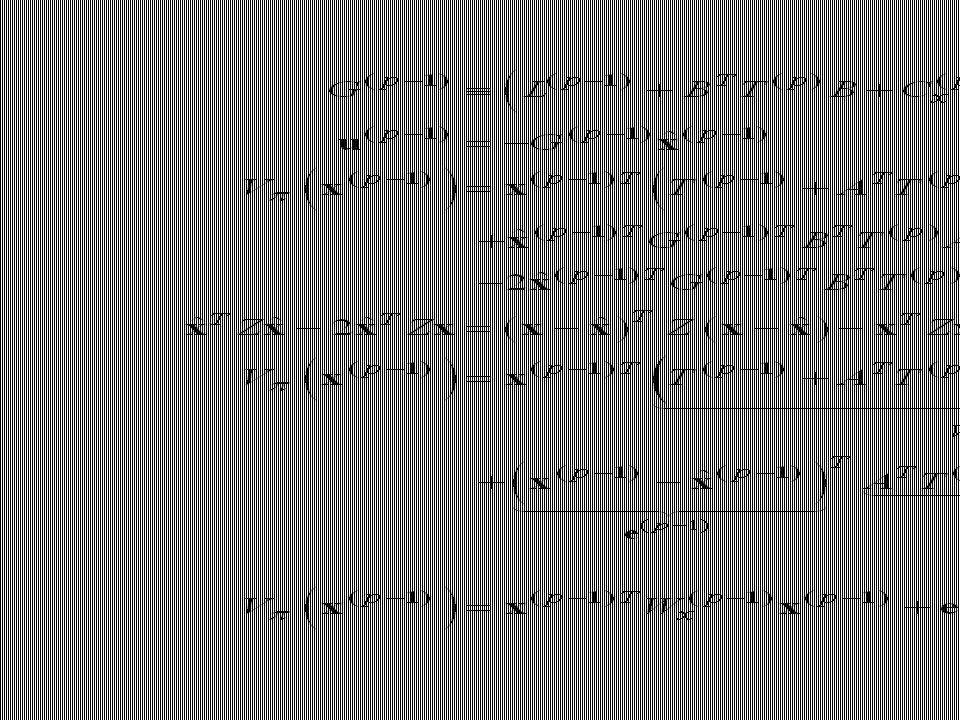Download presentation
Presentation is loading. Please wait.

1
580.691 Learning Theory Reza Shadmehr Optimal feedback control stochastic feedback control with signal dependent noise

2
Representing signal dependent noise Vector of zero mean, variance 1 Gaussian random variables signal independent noisesignal dependent motor noise So the motor noise has mean zero and variance that grows with the square of the motor command.

3
Computing a cost for the motor commands: minimize endpoint variance Because there is noise in the motor commands, it will produce variance in our state. The above equation shows that the variance at the end of the movement is mostly influenced by the motor commands late in the movement. To see this, note that A is a matrix that when raised to a power, will become smaller. The larger the raised power, the smaller the resulting matrix will become. In the sum, we have a contribution from each motor command. When n is zero (the very first command), A is raised to a very high power. The noise in this command will have little influence on the endpoint variance. When n is larger (commands near end of the movement), A is raised to a small power. The noise in these commands will have a great deal of influence on the endpoint variance. Therefore, we have a natural cost function for the motor commands:
, A is raised to a very high power. The noise in this command will have little influence on the endpoint variance. When n is larger (commands near end of the movement), A is raised to a small power. The noise in these commands will have a great deal of influence on the endpoint variance. Therefore, we have a natural cost function for the motor commands:.")
4
Cost per step: Control problem with signal dependent noise (Todorov, Neural Computation 2005)
")
7
Conjecture: If at some time point k+1 the value function under an optimal control policy is quadratic in x and e, and provided that we produce a u that minimizes the cost-to-go at time step k, then the value function at time step k will also be quadratic. To prove this, our first step is to find the u that minimizes the cost-to-go at time step k, and then show that at the resulting value function remains in the quadratic form above. To compute the expected value term, we need to do some work on the term e.

8
Terms that do not depend on u

9
So we just showed that if at some time point k+1 the value function under an optimal control policy is quadratic in x and e, and provided that we produce a u that minimizes the cost-to-go at time step k, then the value function at time step k will also be quadratic. Since we had earlier shown that at time step p-1 the cost is quadratic in x and e, we now have the solution to our problem.

10
Cost per step Summary: Control problem with signal dependent noise (Todorov 2005) For the last time step
 For the last time step")
11
Unlike the Gaussian noise, signal dependent noise affects the optimal control policy: feedback gain becomes smaller with increased signal dependent noise This reduction is particularly large near the end of the movement when the cost associated with motor commands tends to be larger. 00.020.040.060.080.10.120.14 sec 0 10 20 30 40 50 s o P n i a G 1 0.1 0.01 Variance of the motor noise Feedback gain for a 30 deg saccade

Similar presentations