Download presentation
Presentation is loading. Please wait.

1
A general statistical analysis for fMRI data Keith Worsley 12, Chuanhong Liao 1, John Aston 123, Jean-Baptiste Poline 4, Gary Duncan 5, Vali Petre 2, Frank Morales 6, Alan Evans 2 1 Department of Mathematics and Statistics, McGill University, 2 Brain Imaging Centre, Montreal Neurological Institute, 3 Imperial College, London, 4 Service Hospitalier Frédéric Joliot, CEA, Orsay, 5 Centre de Recherche en Sciences Neurologiques, Université de Montréal, 6 Cuban Neuroscience Centre

2
050100150200250300350400 920 940 960 fMRI data hot rest warm (a) Highly significant correlation 050100150200250300350400 900 920 940 fMRI data hot rest warm (b) No significant correlation 050100150200250300350400 830 840 850 Time, t (seconds) fMRI data (c) Drift fMRI data: 120 scans, 3 scans each of hot, rest, warm, rest, hot, rest, … Z = (effect hot – warm) / S.d. ~ N(0,1) if no effect
 if no effect.")
4
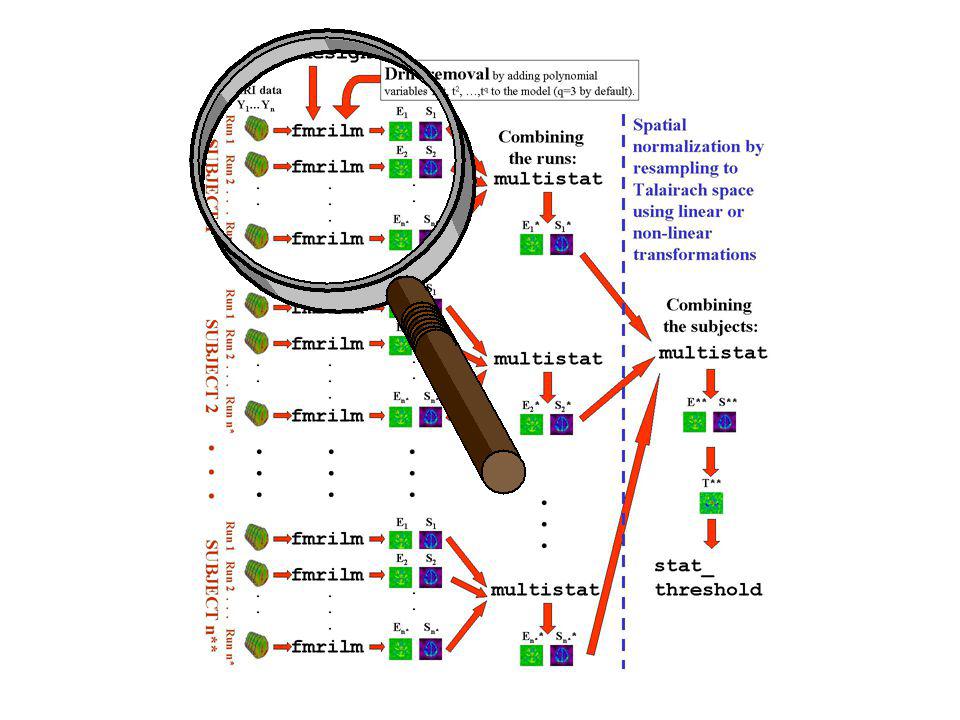
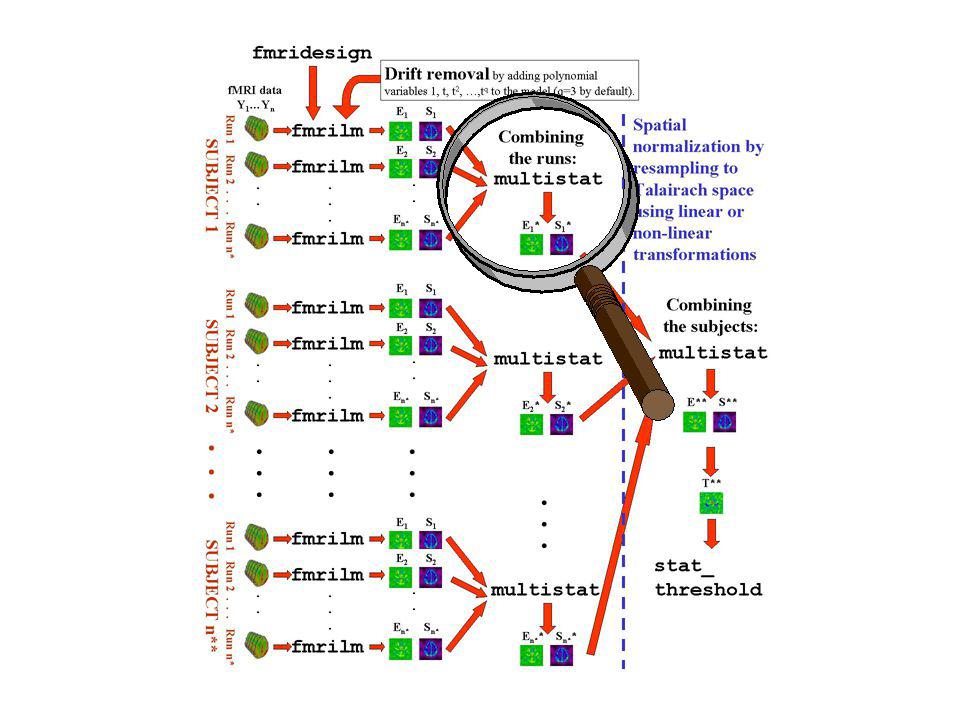
FMRISTAT: Simple, general, valid, robust, fast analysis of fMRI data Linear model: ? ? Y t = (stimulus t * HRF) b + drift t c + error t AR(p) errors: ? ? ? error t = a 1 error t-1 + … + a p error t-p + s WN t unknown parameters
 b + drift t c + error t AR(p) errors: . error t = a 1 error t-1 + … + a p error t-p + s WN t unknown parameters.")
6
(c) Response, x(t): sampled at the slice acquisition times every 3 seconds Time, t (seconds) FMRIDESIGN example: Pain perception
 Response, x(t): sampled at the slice acquisition times every 3 seconds Time, t (seconds) FMRIDESIGN example: Pain perception")
8
FMRILM step 1: estimate temporal correlation AR(1) model: error t = a 1 error t-1 + s WN t Fit the linear model using least squares. error t = Y t – fitted Y t â 1 = Correlation ( error t, error t-1 ) Estimating error t s changes their correlation structure slightly, so â 1 is slightly biased. Bias correction is very quick and effective: Raw autocorrelation Smoothed 15mm Bias corrected â 1 ~ -0.05 ~ 0 ?
 Estimating error t s changes their correlation structure slightly, so â 1 is slightly biased. Bias correction is very quick and effective: Raw autocorrelation Smoothed 15mm Bias corrected â 1 ~ ~ 0 .")
9
FMRILM step 2: refit the linear model Pre-whiten: Y t * = Y t – â 1 Y t-1, then fit using least squares: Effect: hot – warm Sd of effect T statistic = Effect / Sd T > 4.90 (P < 0.05, corrected)
")
10
Higher order AR model? Try AR(4): â 1 â 2 â 3 â 4 AR(1) seems to be adequate ~ 0
: â 1 â 2 â 3 â 4 AR(1) seems to be adequate ~ 0")
11
… has no effect on the T statistics: AR(1) AR(2) AR(4) biases T up ~12% more false positives But ignoring correlation …
 AR(2) AR(4) biases T up ~12% more false positives But ignoring correlation …")
13
Results from 4 runs on the same subject Run 1 Run 2 Run 3 Run 4 Effect E i Sd S i T stat E i / S i

14
MULTISTAT combines effects from different runs/sessions/subjects: E i = effect for run/session/subject i S i = standard error of effect Mixed effects model: E i = covariates i c + S i WN i F + WN i R Random effect, due to variability from run to run Fixed effects error, due to variability within the same run Usually 1, but could add group, treatment, age, sex,... } from FMRILM ??

15
REML estimation of the mixed effects model using the EM algorithm Slow to converge (10 iterations by default). Stable (maintains estimate 2 > 0 ), but 2 biased if 2 (random effect) is small, so: Re-parametrise the variance model: Var(E i ) = S i 2 + 2 = (S i 2 – min j S j 2 ) + ( 2 + min j S j 2 ) = S i * 2 + * 2 2 = * 2 – min j S j 2 (less biased estimate) ^^ ^ ? ? ^
, but 2 biased if 2 (random effect) is small, so: Re-parametrise the variance model: Var(E i ) = S i = (S i 2 – min j S j 2 ) + ( 2 + min j S j 2 ) = S i * 2 + * 2 2 = * 2 – min j S j 2 (less biased estimate) ^^ ^ . ^.")
16
Run 1 Run 2 Run 3 Run 4 MULTISTAT Effect E i Sd S i T stat E i / S i Problem: 4 runs, 3 df for random effects sd... … and T>15.96 for P<0.05 (corrected): … very noisy sd: … so no response is detected …
: … very noisy sd: … so no response is detected ….")
17
Basic idea: increase df by spatial smoothing (local pooling) of the sd. Cant smooth the random effects sd directly, - too much anatomical structure. Instead, random effects sd fixed effects sd which removes the anatomical structure before smoothing. Solution: Spatial regularization of the sd sd = smooth fixed effects sd )
.")
18
Random effects sd (3 df) Fixed effects sd (448 df) Random effects sd Fixed effects sd Regularized sd (112 df) Fixed effects sd Smooth15mm~1 ~1.6 Over runs~3 Over subjects
 Fixed effects sd (448 df) Random effects sd Fixed effects sd Regularized sd (112 df) Fixed effects sd Smooth15mm~1 ~1.6 Over runs~3 Over subjects")
19
df ratio = df random ( 2 + 1 ) 1 1 1 df eff df ratio df fixed e.g. df random = 3, df fixed = 112, FWHM data = 6mm: FWHM ratio (mm) 0 5 10 15 20 infinite df eff 3 11 45 112 192 448 Effective df depends on the smoothing Random effects Fixed effects variability bias compromise! FWHM ratio 2 3/2 FWHM data 2 = +
 infinite df eff Effective df depends on the smoothing Random effects Fixed effects variability bias compromise. FWHM ratio 2 3/2 FWHM data 2 = +.")
20
Run 1 Run 2 Run 3 Run 4 MULTISTAT Effect E i Sd S i T stat E i / S i Final result: 15mm smoothing, 112 effective df … … less noisy sd: … and T>4.90 for P<0.05 (corrected): … and now we can detect a response!
: … and now we can detect a response!")
21
Conjunction: All T i > threshold = Min T i > threshold Minimum of T i Average of T i For P=0.05, threshold = 1.82 For P=0.05, threshold = 4.90 Efficiency = 82%

22
If the conjunction is significant, does it mean that all effects > 0? Problem: for the conjunction of 20 effects, the threshold can be negative!?!?! Reason: significance is based on the wrong null hypothesis, namely: all effects = 0 Correct null hypothesis is: at least one effect = 0. Unfortunately the P-value depends on the unknown > 0 effects … If the effects are random, all effects > 0 is meaningless. The only parameter is the (single) population effect, so that the conjunction just tests if population effect > 0. P-values now depend on the random effects sd, not the fixed effects sd. But the minimum (i.e. the conjunction) is less efficient (sensitive) than the average (the usual test).
 population effect, so that the conjunction just tests if population effect > 0. P-values now depend on the random effects sd, not the fixed effects sd. But the minimum (i.e. the conjunction) is less efficient (sensitive) than the average (the usual test)..")
24
FWHM – the local smoothness of the noise Used by STAT_THRESHOLD to find the P-value of local maxima and the spatial extent of clusters of voxels above a threshold. u = normalised residuals from linear model = residuals / sd u = vector of spatial derivatives of u λ = |Var(u)| 1/2 (mm -3 ) FWHM = (4 log 2) 1/2 λ -1/3 (mm) (If residuals are modeled as white noise smoothed with a Gaussian kernel, this would be its FWHM). λ and FWHM are corrected for low df and large voxel size so they are approximately unbiased. For a search region S, the number of resolution elements is Resels(S) = Vol(S) Avg S (FWHM -3 ) = Vol(S) Avg S (λ) (4 log 2) -3/2 For local maxima in S, P_value = Resels(S) x (function of threshold). For a cluster C, P-value depends on Resels(C) instead of Vol(C), so that clusters in smooth regions are less significant. Need a correction for the randomness of λ and FWHM - depends on df. Correction is more important for small clusters C than for large search regions S. · ·
| 1/2 (mm -3 ) FWHM = (4 log 2) 1/2 λ -1/3 (mm) (If residuals are modeled as white noise smoothed with a Gaussian kernel, this would be its FWHM). λ and FWHM are corrected for low df and large voxel size so they are approximately unbiased. For a search region S, the number of resolution elements is Resels(S) = Vol(S) Avg S (FWHM -3 ) = Vol(S) Avg S (λ) (4 log 2) -3/2 For local maxima in S, P_value = Resels(S) x (function of threshold). For a cluster C, P-value depends on Resels(C) instead of Vol(C), so that clusters in smooth regions are less significant. Need a correction for the randomness of λ and FWHM - depends on df. Correction is more important for small clusters C than for large search regions S. · ·.")
25
Resels=1.90 P=0.007 Resels=0.57 P=0.387 …. FWHM depends on the spatial correlation between neighbours

26
T>4.86 T > 4.90 (P < 0.05, corrected)
")
27
Smooth the data before analysis? Temporal smoothing or low-pass filtering is used by SPM99 to validate a global AR(1) model. For our local AR(p) model, it is not necessary (but ~ harmless). Spatial smoothing is used by SPM99 to validate random field theory. Can be harmful for focal signals. Should fix the theory! STAT_THRESHOLD uses the better of the Bonferroni or the random field theory. A better reason for spatial smoothing is greater detectability of extensive activation: choose the FWHM to match the activation (e.g. 10mm FWHM for 10mm activations) – or try a range of FWHMs i.e. scale space – but thresholds are higher …
 model. For our local AR(p) model, it is not necessary (but ~ harmless). Spatial smoothing is used by SPM99 to validate random field theory. Can be harmful for focal signals. Should fix the theory. STAT_THRESHOLD uses the better of the Bonferroni or the random field theory. A better reason for spatial smoothing is greater detectability of extensive activation: choose the FWHM to match the activation (e.g. 10mm FWHM for 10mm activations) – or try a range of FWHMs i.e. scale space – but thresholds are higher ….")
28
False Discovery Rate (FDR) Benjamini and Hochberg (1995), Journal of the Royal Statistical Society Benjamini and Yekutieli (2001), Annals of Statistics Genovese et al. (2001), NeuroImage FDR controls the expected proportion of false positives amongst the discoveries, whereas Bonferroni / random field theory controls the probability of any false positives No correction controls the proportion of false positives in the volume
, NeuroImage FDR controls the expected proportion of false positives amongst the discoveries, whereas Bonferroni / random field theory controls the probability of any false positives No correction controls the proportion of false positives in the volume.")
29
Noise P 1.64 5% of volume is false + FDR 2.82 5% of discoveries is false + P 4.22 5% probability of any false + Signal + Gaussian white noise False + True + Signal

30
FDR depends on the ordered P-values (not smoothness): P 1 < P 2 < … < P n. To control the FDR at a = 0.05, find K = max {i : P i < (i/n) a }, threshold the P-values at P K Proportion of true + 1 0.1 0.01 0.001 0.0001 Threshold Z 1.64 2.56 3.28 3.88 4.41 Bonferroni thresholds the P-values at a /n: Number of voxels 1 10 100 1000 10000 Threshold Z 1.64 2.58 3.29 3.89 4.42 Random field theory: resels = volume / FHHM 3 : Number of resels 0 1 10 100 1000 Threshold Z 1.64 2.82 3.46 4.09 4.65 Comparison of thresholds
 a }, threshold the P-values at P K Proportion of true Threshold Z Bonferroni thresholds the P-values at a /n: Number of voxels Threshold Z Random field theory: resels = volume / FHHM 3 : Number of resels Threshold Z Comparison of thresholds.")
31
FDR 2.91 5% of discoveries is false + P 4.86 5% probability of any false + P 1.64 5% of volume is false + Which do you prefer?

33
-50510152025 -0.4 -0.2 0 0.2 0.4 0.6 t (seconds) Estimating the delay of the response Delay or latency to the peak of the HRF is approximated by a linear combination of two optimally chosen basis functions: HRF(t + shift) ~ basis 1 (t) w 1 (shift) + basis 2 (t) w 2 (shift) Convolve bases with the stimulus, then add to the linear model basis 1 basis 2 HRF shift delay
 Estimating the delay of the response Delay or latency to the peak of the HRF is approximated by a linear combination of two optimally chosen basis functions: HRF(t + shift) ~ basis 1 (t) w 1 (shift) + basis 2 (t) w 2 (shift) Convolve bases with the stimulus, then add to the linear model basis 1 basis 2 HRF shift delay")
34
-505 -3 -2 0 1 2 3 shift (seconds) Fit linear model, estimate w 1 and w 2 Equate w 2 / w 1 to estimates, then solve for shift (Hensen et al., 2002) To reduce bias when the magnitude is small, use shift / (1 + 1/T 2 ) where T = w 1 / Sd(w 1 ) is the T statistic for the magnitude Shrinks shift to 0 where there is little evidence for a response. w1w1 w2w2 w 2 / w 1

35
Delay of the hot stimulus (= shift + 5.4 sec) T stat for magnitude T stat for shift Delay (secs) Sd of delay (secs)
 T stat for magnitude T stat for shift Delay (secs) Sd of delay (secs)")
36
Varying the delay and dispersion of the reference HRF T stat for magnitude T stat for shift Delay (secs) Sd of delay (secs)
 Sd of delay (secs)")
37
Delay (secs) 6.5 5 5.5 4 4.5 T > 4.86 (P < 0.05, corrected)
 T > 4.86 (P < 0.05, corrected)")
38
Delay (secs) 6.5 5 5.5 4 4.5 T > 4.86 (P < 0.05, corrected)
 T > 4.86 (P < 0.05, corrected)")
40
EFFICIENCY for optimum block design 0 0.1 0.2 0.3 0.4 0.5 InterStimulus Interval (secs) Sd of hot stimulus X 5101520 0 5 10 15 20 0 0.1 0.2 0.3 0.4 0.5 Sd of hot-warm X 5101520 0 5 10 15 20 0 0.2 0.4 0.6 0.8 1 (secs) 5101520 5 10 15 20 0 0.2 0.4 0.6 0.8 1 Stimulus Duration (secs) (secs) 5101520 0 5 10 15 20 Optimum design Optimum design X Optimum design Optimum design X Magnitude Delay (Not enough signal)
 Sd of hot stimulus X Sd of hot-warm X (secs) Stimulus Duration (secs) (secs) Optimum design Optimum design X Optimum design Optimum design X Magnitude Delay (Not enough signal)")
41
5101520 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 Average time between events (secs) Sd of effect (secs for delays) uniform......... random......... concentrated : EFFICIENCY for optimum event design ____ magnitudes ……. delays (Not enough signal)
.")
42
How many subjects? Variance = sd run 2 sd sess 2 sd subj 2 n run n sess n subj n sess n subj n subj The largest portion of variance comes from the last stage, i.e. combining over subjects. If you want to optimize total scanner time, take more subjects, rather than more scans per subject. What you do at early stages doesnt matter very much - any reasonable design will do … ++

43
Comparison Different slice acquisition times: Drift removal: Temporal correlation: Estimation of effects: Rationale: Random effects: FWHM: Map of delay: SPM99: Adds a temporal derivative Low frequency cosines (flat at the ends) AR(1), global parameter, bias reduction not necessary Band pass filter, then least-squares, then correction for temporal correlation More robust, low df No regularization, low df Global, ~ OK for local maxima, but not clusters No FMRISTAT: Shifts the model Polynomials (free at the ends) AR(p), voxel parameters, bias reduction Pre-whiten, then least squares (no further corrections needed) More efficient, high df Regularization, high df Local, is OK for local maxima and clusters Yes
 AR(1), global parameter, bias reduction not necessary Band pass filter, then least-squares, then correction for temporal correlation More robust, low df No regularization, low df Global, ~ OK for local maxima, but not clusters No FMRISTAT: Shifts the model Polynomials (free at the ends) AR(p), voxel parameters, bias reduction Pre-whiten, then least squares (no further corrections needed) More efficient, high df Regularization, high df Local, is OK for local maxima and clusters Yes")
44
References Worsley et al. (2002). A general statistical analysis for fMRI data. NeuroImage, 15:1-15. Liao et al. (2002). Estimating the delay of the fMRI response. NeuroImage, 16:593-606. http://www.math.mcgill.ca/keith/fmristat - 200K of MATLAB code - fully worked example
. Estimating the delay of the fMRI response. NeuroImage, 16: K of MATLAB code - fully worked example.")
45
Functional connectivity Measured by the correlation between residuals at every pair of voxels (6D data!) Local maxima are larger than all 12 neighbours P-value can be calculated using random field theory Good at detecting focal connectivity, but PCA of residuals x voxels is better at detecting large regions of co-correlated voxels Voxel 2 Voxel 1 + + + + + + Activation only Voxel 2 Voxel 1 + + + + + + Correlation only
 Local maxima are larger than all 12 neighbours P-value can be calculated using random field theory Good at detecting focal connectivity, but PCA of residuals x voxels is better at detecting large regions of co-correlated voxels Voxel 2 Voxel Activation only Voxel 2 Voxel Correlation only")
46
First Principal Component > threshold |Correlations| > 0.7, P<10 -10 (corrected)
")
Similar presentations















>")
 Institute for Empirical.>")



 Calculates P=0.05 (corrected) threshold t for the T statistic using the minimum given by a Bonferroni correction and.>")



