Download presentation
Presentation is loading. Please wait.

1
Mkael Symmonds, Bahador Bahrami
Random Field Theory Mkael Symmonds, Bahador Bahrami

2
Mkael Symmonds, Bahador Bahrami
Random Field Theory Mkael Symmonds, Bahador Bahrami

3
Overview Spatial smoothing Statistical inference
The multiple comparison problem …and what to do about it

4
Overview Spatial smoothing Statistical inference
The multiple comparison problem …and what to do about it

5
Statistical inference
Aim to decide if the data represents convincing evidence of the effect we are interested in. How perform a statistical test across the whole brain volume to tell us how likely our data are to have come about by chance (the null distribution). We perform a statistical test to inform us how surprising our data are – that is, how likely that the data is to have come about by chance.
. We perform a statistical test to inform us how surprising our data are – that is, how likely that the data is to have come about by chance.")
6
Inference at a single voxel
NULL hypothesis, H0: activation is zero t-distribution t-value = 2.42 p-value: probability of getting a value of t at least as extreme as 2.42 from the t distribution (= 0.01). The null hypothesis is that the data are drawn from a purely random distribution of values, with a Gaussian distribution of noise. So our null hypothesis is that there is no activation and our data variance is pure noise. Say we perform a t-test, and get a value of 2. We translate this into a p value, the probability of getting this t value from our distribution with our given degrees of freedom (p=0.01 for df=40 and t=2.42). We set the value of alpha at a level that we feel is reasonable (i.e. the proportion or rate of false positives that we are willing to accept). This can be anything we like – in this case 2.5%, though in most social research it is set at 5% by convention. If p is less than alpha, we reject the null hypothesis – it is unlikely that the data arose by chance. For the given example, a p value of 0.01 means that there is a 1% chance for making a type 1 error (falsely rejecting the null hypothesis). a = p(t>t-value|H0) alpha = 0.025 t-value = 2.02 t-value = 2.42 As p < α , we reject the null hypothesis
. The null hypothesis is that the data are drawn from a purely random distribution of values, with a Gaussian distribution of noise. So our null hypothesis is that there is no activation and our data variance is pure noise. Say we perform a t-test, and get a value of 2. We translate this into a p value, the probability of getting this t value from our distribution with our given degrees of freedom (p=0.01 for df=40 and t=2.42). We set the value of alpha at a level that we feel is reasonable (i.e. the proportion or rate of false positives that we are willing to accept). This can be anything we like – in this case 2.5%, though in most social research it is set at 5% by convention. If p is less than alpha, we reject the null hypothesis – it is unlikely that the data arose by chance. For the given example, a p value of 0.01 means that there is a 1% chance for making a type 1 error (falsely rejecting the null hypothesis). a = p(t>t-value|H0) alpha = t-value = t-value = As p < α , we reject the null hypothesis.")
7
Sensitivity and Specificity
ACTION Don’t Reject Reject Chance H0 True TN FP – type I error H0 False FN TP Not by chance So from our threshold we can have 4 possibilities. Null hypothesis is true and we treat it is such a true -ve, Null hypothesis is true and we reject it - think its activation and get a False positive. Alternatively, the null hypothesis is false and we incorrectly reject it, a false negative. Lastly, we correctly reject the null hypothesis and so get a true positive.. We can define two terms. Firstly , the specificity that is given by the number of true negatives given that the null hypothesis is true (no activation) – this is simply 1-alpha. Secondarily, we get the sensitivity that is; given that there is an activation, the null hypothesis is wrong how much of the time do we get it correct. Specificity = TN/(# H True) = TN/(TN+FP) = 1 - a Sensitivity = TP/(# H False) = TP/(TP+FN) = b = power
 – this is simply 1-alpha. Secondarily, we get the sensitivity that is; given that there is an activation, the null hypothesis is wrong how much of the time do we get it correct. Specificity = TN/(# H True) = TN/(TN+FP) = 1 - a. Sensitivity = TP/(# H False) = TP/(TP+FN) = b = power.")
8
Many statistical tests
In functional imaging, there are many voxels, therefore many statistical tests If we do not know where in the brain our effect will occur, the hypothesis relates to the whole volume of statistics in the brain We would reject H0 if the entire family of statistical values is unlikely to have arisen from a null distribution – a family-wise hypothesis The risk of error we are prepared to accept is called the Family-Wise Error (FWE) rate – what is the likelihood that the family of voxel values could have arisen by chance The family wise error is like the alpha for an individual test, but now we are considering a whole set of tests, one for each voxel
 rate – what is the likelihood that the family of voxel values could have arisen by chance. The family wise error is like the alpha for an individual test, but now we are considering a whole set of tests, one for each voxel.")
9
How to test a family-wise hypothesis?
Height thresholding To test a family-wise hypothesis, we can look for any statistic values are larger than we expect, if they had all come from a null distribution. Therefore, we need to find a threshold that we can apply to every statistic value, in order to say that values above the threshold are unlikely to have arisen by chance. If we find voxels with statistic values above threshold, we can conclude that there is an effect at these voxel locations. This can localise significant test results

10
How to set the threshold?
Should we use the same alpha as when we perform inference at a single voxel? What threshold should we set? Should we use the same value for alpha as we use in a single statistical test – an ‘uncorrected’ p value

11
Overview Spatial smoothing Statistical inference
The multiple comparison problem …and what to do about it

12
How to set the threshold?
Signal + Noise 11.3% 12.5% 10.8% 11.5% 10.0% 10.7% 11.2% 10.2% 9.5% Use of ‘uncorrected’ alpha, a=0.1 Percentage of Null Pixels that are False Positives If alpha, our threshold, = 0.1, then 10% of our voxels will be falsely positive – i.e. lead to false rejection of the null hypothesis LOTS OF SIGNIFICANT ACTIVATIONS OUTSIDE OF OUR SIGNAL BLOB!

13
How to set the threshold?
So, if we see 1 t-value above our uncorrected threshold in the family of tests, this is not good evidence against the family-wise null hypothesis If we are prepared to accept a false positive rate of 5%, we need a threshold such that, for the entire family of statistical tests, there is a 5% chance of there being one or more t values above that threshold. If we see one or more t-values above our threshold in the family of tests that we perform, this is not good evidence against the family-wise null hypothesis that all these values have been drawn from a null distribution.

14
Bonferroni Correction
For one voxel (all values from a null distribution) Probability of a result greater than the threshold = α Probability of a result less than the threshold = 1-α For n voxels (all values from a null distribution) Probability of all n results being less than the threshold = (1-α)n Probability of one (or more) tests being greater than the threshold: = 1-(1-α)n ~= n.α (as alpha is small) We want to set the threshold such that the probability of an individual test exceeding the threshold is 0.05, at a 5% significance level. So we want our family-wise error rate to be 5%, which the Bonferroni correction tells us is when our threshold alpha is 5%/n FAMILY WISE ERROR RATE
 Probability of a result greater than the threshold = α. Probability of a result less than the threshold = 1-α. For n voxels (all values from a null distribution) Probability of all n results being less than the threshold. = (1-α)n. Probability of one (or more) tests being greater than the threshold: = 1-(1-α)n ~= n.α (as alpha is small) We want to set the threshold such that the probability of an individual test exceeding the threshold is 0.05, at a 5% significance level. So we want our family-wise error rate to be 5%, which the Bonferroni correction tells us is when our threshold alpha is 5%/n. FAMILY WISE ERROR RATE.")
15
Bonferroni Correction
So, Set the PFWE < n.α Gives a threshold α = PFWE / n Should we use the Bonferroni correction for imaging data?

16
100 x 100 voxels – normally distributed independent random numbers
10,000 tests 5% FWE rate Apply Bonferroni correction to give threshold of 0.05/10000 = This corresponds to a z-score of 4.42 We expect only 5 out of 100 such images to have one or more z-scores > 4.42 NULL HYPOTHESIS TRUE 100 x 100 voxels averaged Now only 10 x 10 independent numbers in our image The appropriate Bonferroni correction is 0.05/100= This corresponds to z-score = 3.29 Only 5/100 such images will have one or more z-scores > 3.29 by chance If we smooth randomly generated data by averaging, we reduce the number of independent observations, so change the Bonferroni correction required.

17
Spatial correlation Physiological Correlation Spatial pre-processing
Smoothing Assumes Independent Voxels Independent Voxels Spatially Correlated Voxels The Bonferroni assumes n independent statistical tests – in fact the data is spatially correlated In imaging data, how can we tell how many independent observations there are? The data are spatially correlated before smoothing, and this is even more so after smoothing. Bonferroni is too conservative for brain images, but how to tell how many independent observations there are?

18
Overview Spatial smoothing Statistical inference
The multiple comparison problem …and what to do about it

19
Spatial smoothing Why do you want to do it?
Increases signal-to-noise ratio Enables averaging across subjects Allows use of Gaussian Random Field Theory for thresholding

20
Spatial Smoothing What does it do?
Reduces effect of high frequency variation in functional imaging data, “blurring sharp edges”

21
Spatial Smoothing How is it done?
Typically in functional imaging, a Gaussian smoothing kernel is used Shape similar to normal distribution bell curve Width usually described using “full width at half maximum” (FWHM) measure e.g., for kernel at 10mm FWHM: 5 -5
 measure e.g., for kernel at 10mm FWHM:")
22
Spatial Smoothing How is it done?
Gaussian kernel defines shape of function used successively to calculate weighted average of each data point with respect to its neighbouring data points Raw data x Gaussian function = Smoothed data

23
Spatial Smoothing How is it done?
Gaussian kernel defines shape of function used successively to calculate weighted average of each data point with respect to its neighbouring data points Raw data x Gaussian function = Smoothed data

24
Spatial correlation Physiological Correlation Spatial pre-processing
Smoothing Assumes Independent Voxels Independent Voxels Spatially Correlated Voxels The Bonferroni assumes n independent statistical tests – in fact the data is spatially correlated In imaging data, how can we tell how many independent observations there are? The data are spatially correlated before smoothing, and this is even more so after smoothing. Bonferroni is too conservative for brain images, but how to tell how many independent observations there are?

25
Overview Spatial smoothing Statistical inference
The multiple comparison problem …and what to do about it

26
References Previous MfD slides
An Introduction to Random Field Theory, from Human Brain Mapping, Matthew Brett, Will Penny, Stefan Kiebel Statistical Parametric Mapping short course lecture on RFT, Tom Nichols

27
Random Field Theory (ii)
Methods for Dummies 2008 Mkael Symmonds Bahador Bahrami

28
What is a random field? A random field is a list of random numbers whose values are mapped onto a space (of n dimensions). Values in a random field are usually spatially correlated in one way or another, in its most basic form this might mean that adjacent values do not differ as much as values that are further apart.
. Values in a random field are usually spatially correlated in one way or another, in its most basic form this might mean that adjacent values do not differ as much as values that are further apart.")
29
Why random field? To characterise the properties our study’s statistical parametric map under the NULL hypothesis NULL hypothesis = if all predictions were wrong all activations were merely driven by chance each voxel value was a random number What would the probability of getting a certain z-score for a voxel in this situation be?

30
Random Field

31
one Zero

32
three Measurement 1 Number of blobs = 4 Measurement 2 Number of blobs = 0 Measurement 3 Number of blobs = 1 Measurement Number of blobs = 2 Average number of blobs = ( … + 2)/ The probability of getting a z-score>3 by chance
/ The probability of getting a z-score>3 by chance.")
33
Therefore, for every z-score, the expected value of number of blobs =
probability of rejecting the null hypothesis erroneously (α)
")
34
The million-dollar question is:
thresholding the random field at which Z-score produces average number of blobs < 0.05? Or, Which Z-score has a probability = 0.05 of rejecting the null hypothesis erroneously? Any z-scores above that will be significant!

35
So, it all comes down to estimating the average number of blobs (that you expect by chance) in your SPM Random field theory does that for you!

36
Expected number of blobs in a random field depends on …
Chosen threshold z-score Volume of search region Roughness (i.e.,1/smoothness) of the search region: Spatial extent of correlation among values in the field; it is described by FWHM Volume and Roughness are combined into RESELs Where does SPM get R from: it is calculated from the residuals (RPV.img) Given the R and Z, RFT calculates the expected number of blobs for you: E(EC) = R (4 ln 2) (2π) -3/2 z exp(-z2/2)
 of the search region: Spatial extent of correlation among values in the field; it is described by FWHM. Volume and Roughness are combined into RESELs. Where does SPM get R from: it is calculated from the residuals (RPV.img) Given the R and Z, RFT calculates the expected number of blobs for you: E(EC) = R (4 ln 2) (2π) -3/2 z exp(-z2/2)")
37
α = PFWE = R (4 ln 2) (2π) -3/2 z exp(-z2/2)
Probability of Family Wise Error PFWE = average number of blobs under null hypothesis α = PFWE = R (4 ln 2) (2π) -3/2 z exp(-z2/2)
 (2π) -3/2 z exp(-z2/2)")
40
Thank you References: Brett, Penny & Keibel. An introduction to Random Field Theory. Chapter from Human Brain Mapping Will Penny’s slides ( Field Theory) Jean-Etienne Poirrier’s slides ( Tom Nichol’s lecture in SPM Short Course (2006)
 Jean-Etienne Poirrier’s slides ( Tom Nichol’s lecture in SPM Short Course (2006)")
41
False Discovery Rate o o o o o o o x x x o o x x x o x x x x ACTION
H True (o) TN=7 FP=3 H False (x) FN=0 TP=10 Don’t Reject ACTION TRUTH FDR=3/13=23% a=3/10=30% At u1 Eg. t-scores from regions that truly do and do not activate FDR = FP/(# Reject) a = FP/(# H True) o o o o o o o x x x o o x x x o x x x x u1
 TN=7 FP=3. H False (x) FN=0 TP=10. Don’t. Reject. ACTION. TRUTH. FDR=3/13=23% a=3/10=30% At u1. Eg. t-scores. from regions. that truly do and. do not activate. FDR = FP/(# Reject) a = FP/(# H True) o o o o o o o x x x o o x x x o x x x x. u1.")
42
False Discovery Rate o o o o o o o x x x o o x x x o x x x x ACTION
H True (o) TN=9 FP=1 H False (x) FN=3 TP=7 Don’t Reject ACTION TRUTH At u2 FDR=1/8=13% a=1/10=10% Eg. t-scores from regions that truly do and do not activate FDR = FP/(# Reject) a = FP/(# H True) o o o o o o o x x x o o x x x o x x x x u2
 TN=9 FP=1. H False (x) FN=3 TP=7. Don’t. Reject. ACTION. TRUTH. At u2. FDR=1/8=13% a=1/10=10% Eg. t-scores. from regions. that truly do and. do not activate. FDR = FP/(# Reject) a = FP/(# H True) o o o o o o o x x x o o x x x o x x x x. u2.")
43
False Discovery Rate Noise Signal Signal+Noise

44
Control of Familywise Error Rate at 10%
FWE Control of Familywise Error Rate at 10% Occurrence of Familywise Error 6.7% 10.4% 14.9% 9.3% 16.2% 13.8% 14.0% 10.5% 12.2% 8.7% Control of False Discovery Rate at 10% Percentage of Activated Pixels that are False Positives

45
Cluster Level Inference
We can increase sensitivity by trading off anatomical specificity Given a voxel level threshold u, we can compute the likelihood (under the null hypothesis) of getting a cluster containing at least n voxels CLUSTER-LEVEL INFERENCE Similarly, we can compute the likelihood of getting c clusters each having at least n voxels SET-LEVEL INFERENCE
 of getting a cluster containing at least n voxels. CLUSTER-LEVEL INFERENCE. Similarly, we can compute the likelihood of getting c. clusters each having at least n voxels. SET-LEVEL INFERENCE.")
46
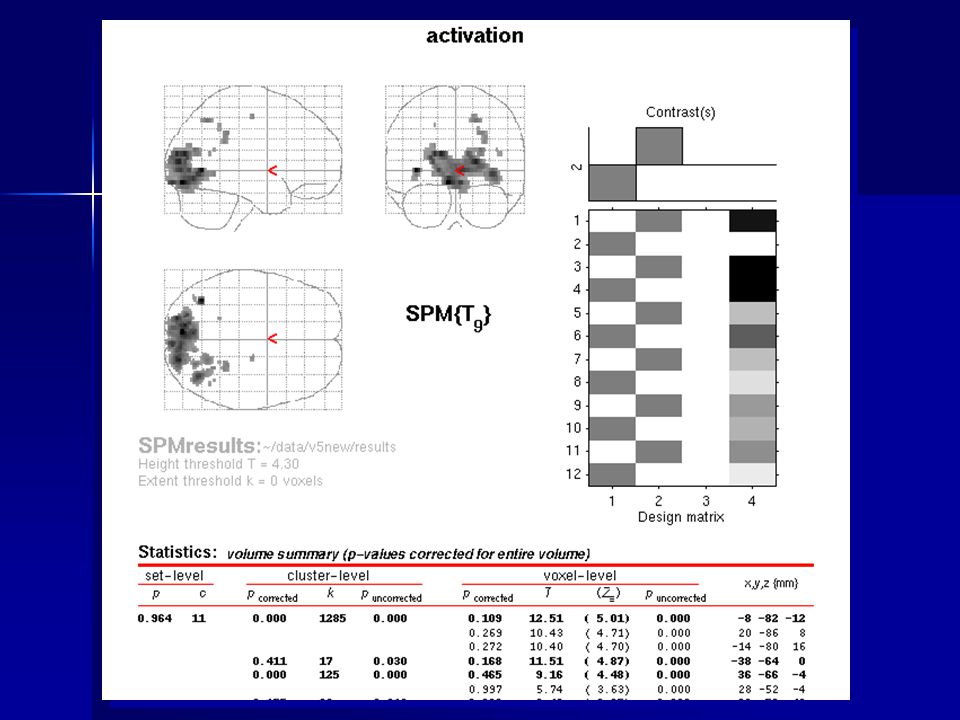
Levels of inference voxel-level
P(c 1 | n > 0, t 4.37) = (corrected) At least one cluster with unspecified number of voxels above threshold n=82 n=32 n=12 set-level P(c 3 | n 12, u 3.09) = 0.019 At least 3 clusters above threshold cluster-level P(c 1 | n 82, t 3.09) = (corrected) At least one cluster with at least 82 voxels above threshold
 = (corrected) At least one. cluster with. unspecified. number of. voxels above. threshold. n=82. n=32. n=12. set-level. P(c 3 | n 12, u 3.09) = At least 3 clusters above. threshold. cluster-level. P(c 1 | n 82, t 3.09) = (corrected) At least one cluster with at least 82 voxels above threshold.")
Similar presentations

, Nelson Trujillo-Barreto (2) Guillaume Flandin (1) Stefan Kiebel(1), Karl Friston (1) (1) Wellcome.>")















 Institute for Empirical.>")


