Download presentation
Presentation is loading. Please wait.

1
PatReco: Model and Feature Selection Alexandros Potamianos Dept of ECE, Tech. Univ. of Crete Fall 2004-2005

2
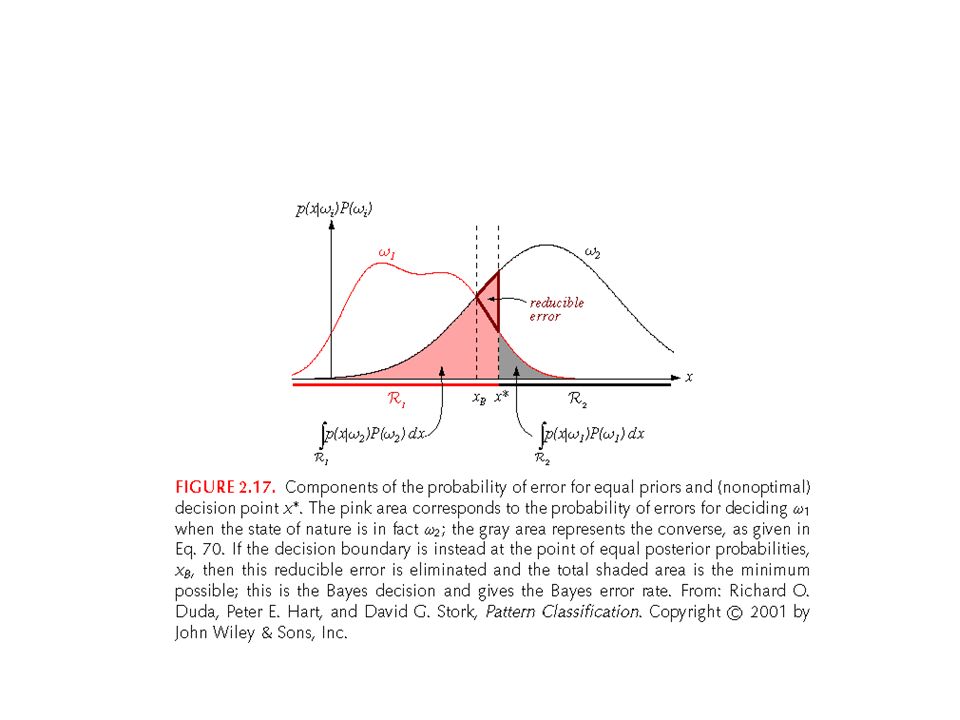
Breakdown of Classification Error Bayes error Model selection error Model estimation error Data mismatch error (training-testing)
")
4
True statements about Bayes error (valid within statistical significance) The Bayes error is ALWAYS smaller than the total (empirical) classification error If the model, estimation and mismatch errors are zero than the total classification error equals the Bayes error The ONLY way to reduce the Bayes error is to add new features in the classifier design
 The Bayes error is ALWAYS smaller than the total (empirical) classification error If the model, estimation and mismatch errors are zero than the total classification error equals the Bayes error The ONLY way to reduce the Bayes error is to add new features in the classifier design")
5
More true statements Adding new features can only reduce the Bayes error (this is not true about the total classification error!!!) Adding new features will NOT reduce the Bayes error if the new features are Very bad at discriminating between classes (feature pdfs overlapping) Highly correlated with existing features
 Adding new features will NOT reduce the Bayes error if the new features are Very bad at discriminating between classes (feature pdfs overlapping) Highly correlated with existing features")
6
Gaussian classification Bayes Error For two classes ω 1 and ω 2 following Gaussian distributions with means μ 1, μ 2 and the same variance σ 2 then the Bayes error is: P(error) = 1/(2π) 0.5 r/2 exp{-u 2 /2} du where r = |μ 1 -μ 2 |/σ
 = 1/(2π) 0.5 r/2 exp{-u 2 /2} du where r = |μ 1 -μ 2 |/σ ")
7
Feature Selection If we had infinite amounts of data then The more features the better! However in practice finite data: More features more parameters to train!!! Good features: Uncorrelated Able to discriminate among classes

8
Model selection Number of model parameters is number of parameters that need to be estimated Overfiting: too many parameters, too little data!!! Gaussian models-Model selection: Single Gaussians Mixture of Gaussians Fixed Variance Tied Variance Diagonal Variance

9
Conclusion Introducing more features and/or more complex models can only reduce the classification error (if infinite amounts of training data are available) In practice: number of features and number of model parameters is a function of amount of training data available (avoid overfiting!) Good features are uncorrelated and discriminative
 In practice: number of features and number of model parameters is a function of amount of training data available (avoid overfiting!) Good features are uncorrelated and discriminative")
Similar presentations