Download presentation
Presentation is loading. Please wait.

1
CS 541: Artificial Intelligence Lecture VII: Inference in Bayesian Networks

2
Re-cap of Lecture VI – Part I Probability is a rigorous formalism for uncertain knowledge Joint probability distribution species probability of every atomic event Queries can be answered by summing over atomic events For nontrivial domains, we must find a way to reduce the joint size Independence and conditional independence provide the tools

3
Re-cap of Lecture VI – Part II Bayes nets provide a natural representation for (causally induced) conditional independence Topology + CPTs = compact representation of joint distribution Generally easy for (non)experts to construct Canonical distributions (e.g., noisy-OR) = compact representation of CPTs Continuous variables parameterized distributions (e.g., linear Gaussian)
 conditional independence Topology + CPTs = compact representation of joint distribution Generally easy for (non)experts to construct Canonical distributions (e.g., noisy-OR) = compact representation of CPTs Continuous variables parameterized distributions (e.g., linear Gaussian)")
4
Outline Exact inference by enumeration Exact inference by variable elimination Approximate inference by stochastic simulation Approximate inference by Markov chain Monte Carlo

5
Exact inference by enumeration

6
Inference tasks Simple queries: compute posterior marginal P( X i | E=e ) e.g., P( NoGas | Gauge=empty, Lights=on, Starts=false ) Conjunctive queries: P( X i, X j | E=e ) = P( X i | E=e )P( X j | X i, E=e ) Optimal decisions: decision networks include utility information; probabilistic inference required for P( outcome | action, evidence) Value of information: which evidence to seek next? Sensitivity analysis: which probability values are most critical? Explanation: why do I need a new starter motor?

7
Inference by enumeration Slightly intelligent way to sum out variables from the joint without actually constructing its explicit representation Simple query on the burglary network: Rewrite full joint entries using product of CPT entries: Recursive depth-first enumeration: O(n) space, O(d n ) time
 space, O(d n ) time")
8
Enumeration algorithm

9
Evaluation tree Enumeration is inefficient: repeated computation E.g., computes for every value of e

10
Inference by variable elimination

11
Variable elimination: carry out summations right-to-left, storing intermediate results (factors) to avoid recomputation
 to avoid recomputation")
12
Variable elimination: basic operations Summing out a variable from a product of factors: Move any constant factors outside the summation Add up submatrices in pointwise product of remaining factors Assuming do not depend on Pointwise product of factors and : E.g.,

13
Variable elimination algorithm

14
Irrelevant variables Consider the query Sum over m is identically 1,M is irrelevant of to the query Theorem 1: is irrelevant unless Here, and so is irrelevant (Compare this to backward chaining from the query in Horn clause KBs)
")
15
Irrelevant variables Definition: moral graph of Bayesian network: marry all parents and drop arrows Definition: A is m-separated from B by C iff separated by C in the moral graph Theorem 2: Y is irrelevant if m-separated from X by E For, both Burglary and Earthquake are irrelevant

16
Singly connected networks (or polytree): any two nodes are connected by at most one (undirected) path time and space cost of variable elimination are O(d k n) Multiply connected networks: Can reduce 3SAT to exact inference NP-hard Equivalent to counting 3SAT models #P-complete Complexity of exact inference
: any two nodes are connected by at most one (undirected) path time and space cost of variable elimination are O(d k n) Multiply connected networks: Can reduce 3SAT to exact inference NP-hard Equivalent to counting 3SAT models #P-complete Complexity of exact inference")
17
Inference by stochastic simulation

19
Direct sampling

20
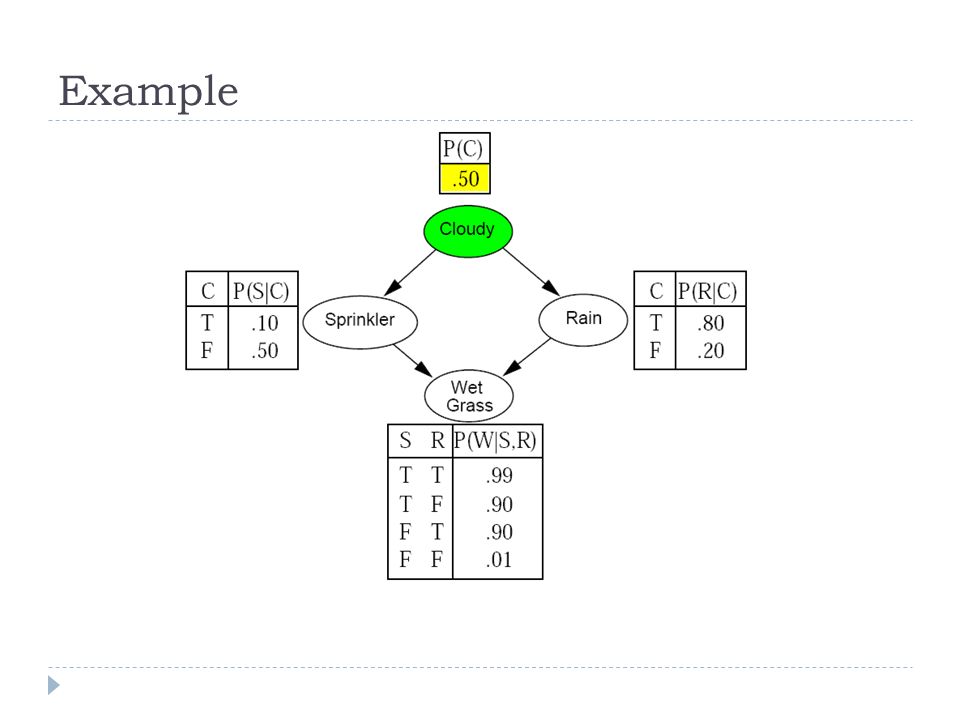
Example

27
Direct sampling Probability that P RIOR S AMPLE generates a particular event i.e., the true prior probability E.g., Let be the number of samples generated for events Then we have That is, estimates from P RIOR S AMPLE are consistent Shorthand:

28
Rejection sampling

29
estimated from samples agreeing with e E.g, estimate using 100 samples 27 samples have Of these, 8 have, 19 have. Similar to a basic real-world empirical estimation procedure

30
Analysis of rejection sampling Hence rejection sampling returns consistent posterior estimates Problem: hopelessly expensive if P(e) is small P(e) drops off exponentially with number of evidence variables!
 is small P(e) drops off exponentially with number of evidence variables!")
31
Likelihood weighting

32
Idea: fix evidence variables, sample only nonevidence variables, and weight each sample by the likelihood it accords the evidence

33
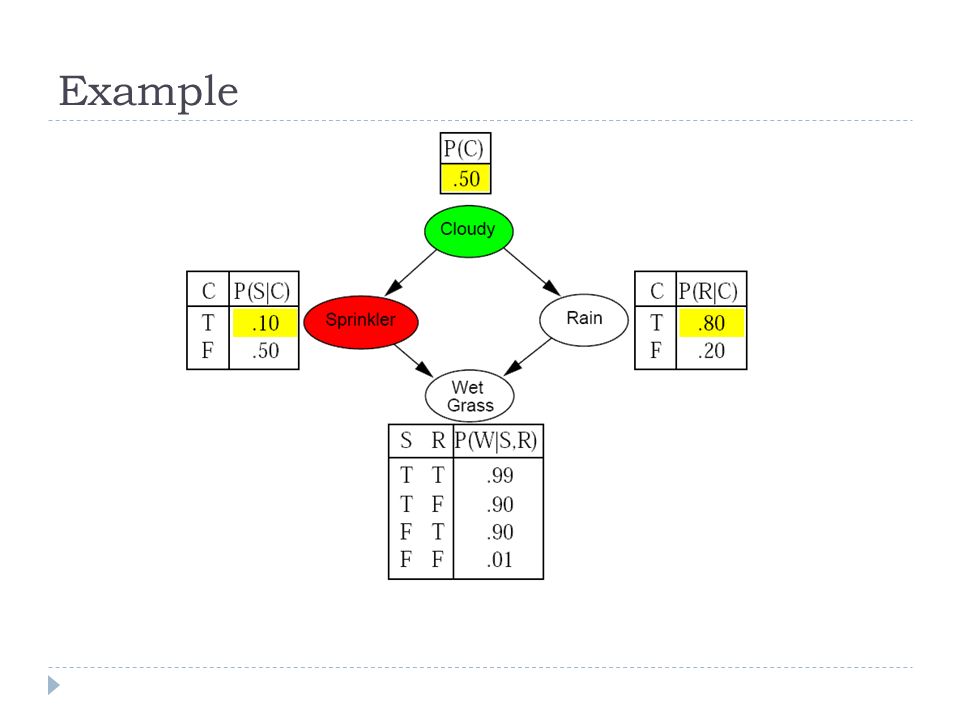
Likelihood weighting example

40
Sampling probability for W EIGHTED S AMPLE is Note: pays attention to evidence in ancestors only Somewhere "between" prior and posterior distribution Weight for a given sample z, e is Weighted sampling probability is Hence likelihood weighting returns consistent estimates but performance still degrades with many evidence variables because a few samples have nearly all the total weight Likelihood weighting analysis

41
Markov chain Monte Carlo

42
"State" of network = current assignment to all variables. Generate next state by sampling one variable given Markov blanket Sample each variable in turn, keeping evidence fixed Can also choose a variable to sample at random each time Approximate inference using MCMC

43
The Markov chain With Sprinkler =true, WetGrass=true, there are four states: Wander about for a while, average what you see

44
MCMC example Estimate Sample Cloudy or Rain given its Markov blanket, repeat. Count number of times Rain is true and false in the samples. E.g., visit 100 states 31 have Rain=true, 69 have Rain=false Theorem: chain approaches stationary distribution, i.e., long-run fraction of time spent in each state is exactly proportional to its posterior probability

45
Markov blanket sampling Markov blanket of Cloudy is Sprinkler and Rain Markov blanket of Rain is Cloudy, Sprinkler, and WetGrass Probability given the Markov blanket is calculated as follows: Easily implemented in message-passing parallel systems, brains Main computational problems: Difficult to tell if convergence has been achieved Can be wasteful if Markov blanket is large: P(X i |mb(X i )) won't change much (law of large numbers)
) won t change much (law of large numbers)")
46
Summary Exact inference by variable elimination: polytime on polytrees, NP-hard on general graphs space = time, very sensitive to topology Approximate inference by LW, MCMC: LW does poorly when there is lots of (downstream) evidence LW, MCMC generally insensitive to topology Convergence can be very slow with probabilities close to 1 or 0 Can handle arbitrary combinations of discrete and continuous variables
 evidence LW, MCMC generally insensitive to topology Convergence can be very slow with probabilities close to 1 or 0 Can handle arbitrary combinations of discrete and continuous variables")
47
HW#3 Probabilistic reasoning Mandatory Problem 14.1 (1 points) Problem 14.4 (2 points) Problem 14.5 (2 points) Problem 14.21 (5 points) Programming is needed for question e) You need to submit your executable along with source code, with detailed readme file on how we can run it. You lose 3 points if no program. Bonus Problem 14.19 (2 points)
.")
Similar presentations












>")
>")
>")

 Problem:>")





 Review session Tuesday.>")

>")





