Download presentation
Presentation is loading. Please wait.

1
CS 188: Artificial Intelligence Spring 2007 Lecture 14: Bayes Nets III 3/1/2007 Srini Narayanan – ICSI and UC Berkeley

2
Announcements Office Hours this week will be on Friday (11-1). Assignment 2 grading Midterm 3/13 Review 3/8 (next Thursday) Midterm review materials up over the weekend. Extended office hours next week (Thursday 11-1, Friday 2:30-4:30)
 Midterm review materials up over the weekend. Extended office hours next week (Thursday 11-1, Friday 2:30-4:30).")
3
Representing Knowledge

4
Inference Inference: calculating some statistic from a joint probability distribution Examples: Posterior probability: Most likely explanation: R T B D L T’

5
Inference in Graphical Models Queries Value of information What evidence should I seek next Sensitivity Analysis What probability values are most critical Explanation e.g., Why do I need a new starter motor Prediction e.g., What would happen if my fuel pump stops working

6
Inference Techniques Exact Inference Inference by enumeration Variable elimination Approximate Inference/ Monte Carlo Prior Sampling Rejection Sampling Likelihood weighting Monte Carlo Markov Chain (MCMC)
")
7
Reminder: Alarm Network

8
Inference by Enumeration Given unlimited time, inference in BNs is easy Recipe: State the marginal probabilities you need Figure out ALL the atomic probabilities you need Calculate and combine them Example:

9
Example Where did we use the BN structure? We didn’t!

10
Example In this simple method, we only need the BN to synthesize the joint entries

11
Normalization Trick Normalize

12
Nesting Sums Atomic inference is extremely slow! Slightly clever way to save work: Move the sums as far right as possible Example:

13
Example

14
Evaluation Tree View the nested sums as a computation tree: Still repeated work: calculate P(m | a) P(j | a) twice, etc.
 P(j | a) twice, etc.")
15
Variable Elimination: Idea Lots of redundant work in the computation tree We can save time if we carry out the summation right to left and cache all intermediate results into objects called factors This is the basic idea behind variable elimination

16
Basic Objects Track objects called factors Initial factors are local CPTs During elimination, create new factors Anatomy of a factor: Variables introduced Variables summed out Factor argument variables

17
Basic Operations First basic operation: join factors Combining two factors: Just like a database join Build a factor over the union of the domains Example:

18
Basic Operations Second basic operation: marginalization Take a factor and sum out a variable Shrinks a factor to a smaller one A projection operation Example:

19
Example

21
General Variable Elimination Query: Start with initial factors: Local CPTs (but instantiated by evidence) While there are still hidden variables (not Q or evidence): Pick a hidden variable H Join all factors mentioning H Project out H Join all remaining factors and normalize
 While there are still hidden variables (not Q or evidence): Pick a hidden variable H Join all factors mentioning H Project out H Join all remaining factors and normalize")
22
Variable Elimination What you need to know: VE caches intermediate computations Polynomial time for tree-structured graphs! Saves time by marginalizing variables as soon as possible rather than at the end Approximations Exact inference is slow, especially when you have a lot of hidden nodes Approximate methods give you a (close) answer, faster
 answer, faster.")
23
Sampling Basic idea: Draw N samples from a sampling distribution S Compute an approximate posterior probability Show this converges to the true probability P Outline: Sampling from an empty network Rejection sampling: reject samples disagreeing with evidence Likelihood weighting: use evidence to weight samples

24
Prior Sampling Cloudy Sprinkler Rain WetGrass Cloudy Sprinkler Rain WetGrass

25
Prior Sampling This process generates samples with probability …i.e. the BN’s joint probability Let the number of samples of an event be Then I.e., the sampling procedure is consistent

26
Example We’ll get a bunch of samples from the BN: c, s, r, w c, s, r, w c, s, r, w c, s, r, w c, s, r, w If we want to know P(W) We have counts Normalize to get P(W) = This will get closer to the true distribution with more samples Can estimate anything else, too What about P(C| r)? P(C| r, w)? Cloudy Sprinkler Rain WetGrass C S R W
. Cloudy Sprinkler Rain WetGrass C S R W.")
27
Rejection Sampling Let’s say we want P(C) No point keeping all samples around Just tally counts of C outcomes Let’s say we want P(C| s) Same thing: tally C outcomes, but ignore (reject) samples which don’t have S=s This is rejection sampling It is also consistent (correct in the limit) c, s, r, w c, s, r, w c, s, r, w c, s, r, w c, s, r, w Cloudy Sprinkler Rain WetGrass C S R W
 No point keeping all samples around Just tally counts of C outcomes Let’s say we want P(C| s) Same thing: tally C outcomes, but ignore (reject) samples which don’t have S=s This is rejection sampling It is also consistent (correct in the limit) c, s, r, w c, s, r, w c, s, r, w c, s, r, w c, s, r, w Cloudy Sprinkler Rain WetGrass C S R W")
28
Likelihood Weighting Problem with rejection sampling: If evidence is unlikely, you reject a lot of samples You don’t exploit your evidence as you sample Consider P(B|a) Idea: fix evidence variables and sample the rest Problem: sample distribution not consistent! Solution: weight by probability of evidence given parents BurglaryAlarm BurglaryAlarm

29
Likelihood Sampling Cloudy Sprinkler Rain WetGrass Cloudy Sprinkler Rain WetGrass

30
Likelihood Weighting Sampling distribution if z sampled and e fixed evidence Now, samples have weights Together, weighted sampling distribution is consistent Cloudy Rain C S R W =

31
Likelihood Weighting Note that likelihood weighting doesn’t solve all our problems Rare evidence is taken into account for downstream variables, but not upstream ones A better solution is Markov-chain Monte Carlo (MCMC), more advanced We’ll return to sampling for robot localization and tracking in dynamic BNs Cloudy Rain C S R W
, more advanced We’ll return to sampling for robot localization and tracking in dynamic BNs Cloudy Rain C S R W")
32
Summary Exact inference in graphical models is tractable only for polytrees. Variable elimination caches intermediate results to make the exact inference process more efficient for a given for a given query. Approximate inference techniques use a variety of sampling methods and can scale to large models. NEXT: Adding dynamics and change to graphical models

33
Bayes Net for insurance

Similar presentations
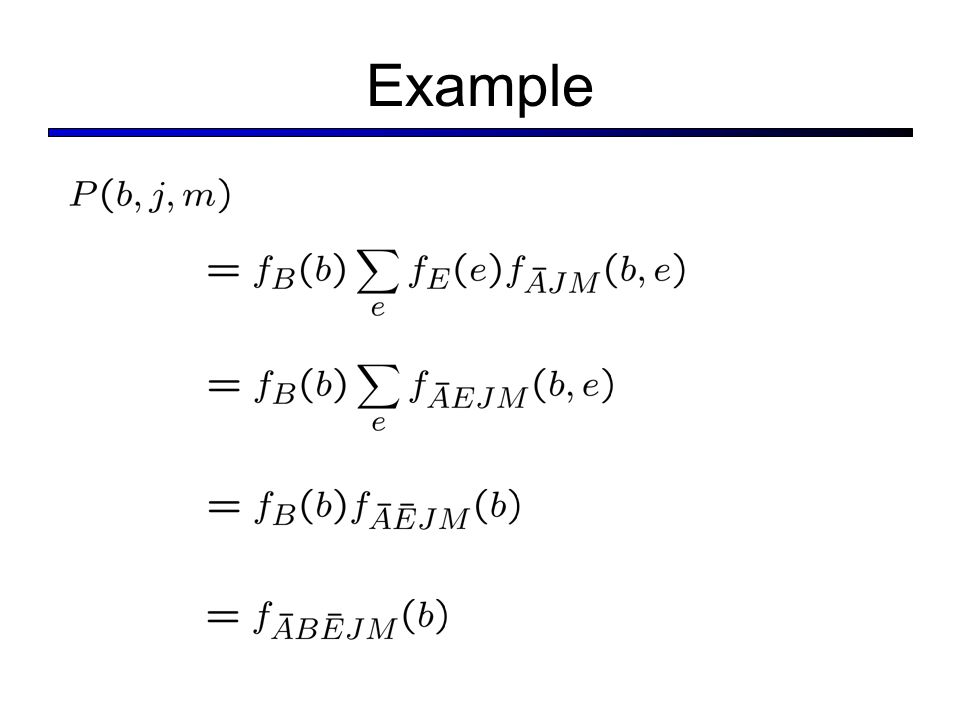
 Computer Science cpsc422, Lecture 11 Jan, 29, 2014.>")

 Thursday, Feb 25, 2014.>")


>")

>")








 Review session Tuesday.>")
>")

