Download presentation
Presentation is loading. Please wait.

1
As a national resource for molecular biology information, NCBI's mission is to develop new information technologies to aid in the understanding of fundamental molecular and genetic processes that control health and disease. NCBI has a multi-disciplinary research group composed of computer scientists, molecular biologists, mathematicians, biochemists, research physicians, and structural biologists concentrating on basic and applied research in computational molecular biology. What is National Center for Biotechnology Information (NCBI)
.")
2
Responsibilities of NCBI: conducts research on fundamental biomedical problems at the molecular level using mathematical and computational methods maintains collaborations with several NIH institutes, academia, industry, and other governmental agencies fosters scientific communication by sponsoring meetings, workshops, and lecture series supports training on basic and applied research in computational biology for postdoctoral fellows through the NIH Intramural Research Program engages members of the international scientific community in informatics research and training through the Scientific Visitors Program develops, distributes, supports, and coordinates access to a variety of databases and software for the scientific and medical communities develops and promotes standards for databases, data deposition and exchange, and biological nomenclature

3
What Is Bioinformatics? Bioinformatics is the field of science in which biology, computer science, and information technology merge to form a single discipline. The ultimate goal of the field is to enable the discovery of new biological insights as well as to create a global perspective from which unifying principles in biology can be discerned. At the beginning of the "genomic revolution", a bioinformatics concern was the creation and maintenance of a database to store biological information, such as nucleotide and amino acid sequences. Development of this type of database involved not only design issues but the development of complex interfaces whereby researchers could both access existing data as well as submit new or revised data.

4
Why Is Bioinformatics So Important? The primary goal of bioinformatics is to increase the understanding of biological processes. What sets it apart from other approaches, however, is its focus on developing and applying computationally intensive techniques (e.g., pattern recognition, data mining, machine learning algorithms, and visualization) to achieve this goal. Major research efforts in the field include sequence alignment, gene finding, genome assembly, drug design, drug discovery, protein structure alignment, protein structure prediction, prediction of gene expression and protein-protein interactions, genome-wide association studies and the modeling of evolution.
 to achieve this goal. Major research efforts in the field include sequence alignment, gene finding, genome assembly, drug design, drug discovery, protein structure alignment, protein structure prediction, prediction of gene expression and protein-protein interactions, genome-wide association studies and the modeling of evolution..")
5
Bioinformatics

6
Tools available in NCBI

7
NUCLEOTIDE DATABASES NCBI's sequence databases accept genome data from sequencing projects from around the world and serve as the cornerstone of bioinformatics research. GenBank: An annotated collection of all publicly available nucleotide and amino acid sequences. EST database: A collection of expressed sequence tags, or short, single-pass sequence reads from mRNA (cDNA). GSS databaseGSS database: A database of genome survey sequences, or short, single-pass genomic sequences. HomoloGene: A gene homology tool that compares nucleotide sequences between pairs of organisms in order to identify putative orthologs. HTG database: A collection of high-throughput genome sequences from large-scale genome sequencing centers, including unfinished and finished sequences. SNPs database: A central repository for both single-base nucleotide substitutions and short deletion and insertion polymorphisms. RefSeq: A database of non-redundant reference sequences standards, including genomic DNA contigs, mRNAs, and proteins for known genes. Multiple collaborations, both within NCBI and with external groups, support our data-gathering efforts. STS database: A database of sequence tagged sites, or short sequences that are operationally unique in the genome. UniSTS: A unified, non-redundant view of sequence tagged sites (STSs). UniGene: A collection of ESTs and full-length mRNA sequences organized into clusters, each representing a unique known or putative human gene annotated with mapping and expression information and cross-references to other sources.
. GSS databaseGSS database: A database of genome survey sequences, or short, single-pass genomic sequences. HomoloGene: A gene homology tool that compares nucleotide sequences between pairs of organisms in order to identify putative orthologs. HTG database: A collection of high-throughput genome sequences from large-scale genome sequencing centers, including unfinished and finished sequences. SNPs database: A central repository for both single-base nucleotide substitutions and short deletion and insertion polymorphisms. RefSeq: A database of non-redundant reference sequences standards, including genomic DNA contigs, mRNAs, and proteins for known genes. Multiple collaborations, both within NCBI and with external groups, support our data-gathering efforts. STS database: A database of sequence tagged sites, or short sequences that are operationally unique in the genome. UniSTS: A unified, non-redundant view of sequence tagged sites (STSs). UniGene: A collection of ESTs and full-length mRNA sequences organized into clusters, each representing a unique known or putative human gene annotated with mapping and expression information and cross-references to other sources..")
8
TOOLS FOR DATA MINING Various data retrieval and submission tools may be found on the NCBI Web site, including: Sequence Similarity Searching BLAST Homepage Access to BLAST (Basic Local Alignment Search Tool) programs, overview, help documentation, and FAQs. BLink Displays the results of BLAST searches that have been done for every protein sequence in the Entrez Protein database. Stand-alone BLAST Download BLAST executables for local use. For more information on how BLAST works, its output, and how both the output and program itself can be further manipulated or customized, see the BLAST section of the NCBI Handbook.NCBI Handbook Taxonomy Taxonomy Browser A tool for searching NCBI's taxonomy database. Taxonomy BLAST Groups BLAST hits by source organism according to their classification in NCBI's Taxonomy database. TaxPlot Provides a three-way comparisons of genomes on the basis of the protein sequences they encode. Sequence Submission Sequin A data submission tool that includes ORF Finder, an alignment viewer/editor, and a link to PowerBLAST. See the GenBank Submission Page for general submission information.GenBank Submission Page BankIt WWW submission tool for one or simple sequence submissions.

9
TOOLS FOR SEQUENCE ANALYSIS NCBI provides access to various sequence analysis tools, including: BLAST The Basic Local Alignment Search Tool (BLAST) for comparing gene and protein sequences against others in public databases, comes in several types including PSI-BLAST, PHI-BLAST, and BLAST 2 sequences. Conserved Domain Database (CDD) A collection of sequence alignments and profiles representing protein domains conserved in molecular evolution. The CD Search Service can be used to search CDD.CD Search Service Electronic-PCR (e-PCR) Can be used to compare a query sequence to mapped sequence-tagged sites to find a possible map location for the query sequence. Entrez Gene Find information on sequence analyses for a particular gene and organism. Gene Expression Omnibus (GEO) GEO provides several tools to assist with the visualization and exploration of curated GEO data. ORF Finder A graphical analysis tool that finds all open reading frames of a selected minimum size in a user's sequence or in a sequence already in the database. Open Mass Spectrometry Search Algorithm OMSSA allows for identification of MS/MS peptide spectra by searching libraries of known protein sequences. Trace Archive Developed to store the raw sequence data underlying sequences generated by various genome projects. VecScreen A tool for identifying segments of a nucleic acid sequence that may be of vector, linker, or adapter origin before using Tools for Sequence Analysis or submission.
 A collection of sequence alignments and profiles representing protein domains conserved in molecular evolution. The CD Search Service can be used to search CDD.CD Search Service Electronic-PCR (e-PCR) Can be used to compare a query sequence to mapped sequence-tagged sites to find a possible map location for the query sequence. Entrez Gene Find information on sequence analyses for a particular gene and organism. Gene Expression Omnibus (GEO) GEO provides several tools to assist with the visualization and exploration of curated GEO data. ORF Finder A graphical analysis tool that finds all open reading frames of a selected minimum size in a user s sequence or in a sequence already in the database. Open Mass Spectrometry Search Algorithm OMSSA allows for identification of MS/MS peptide spectra by searching libraries of known protein sequences. Trace Archive Developed to store the raw sequence data underlying sequences generated by various genome projects. VecScreen A tool for identifying segments of a nucleic acid sequence that may be of vector, linker, or adapter origin before using Tools for Sequence Analysis or submission..")
10
What Are SNPs and How Are They Found? A Single Nucleotide Polymorphism, or SNP (pronounced "snip"), is a small genetic change, or variation, that can occur within a person's DNA sequence. The genetic code is specified by the four nucleotide "letters" A (adenine), C (cytosine), T (thymine), and G (guanine). SNP variation occurs when a single nucleotide, such as an A, replaces one of the other three nucleotide letters—C, G, or T.
, is a small genetic change, or variation, that can occur within a person s DNA sequence. The genetic code is specified by the four nucleotide letters A (adenine), C (cytosine), T (thymine), and G (guanine). SNP variation occurs when a single nucleotide, such as an A, replaces one of the other three nucleotide letters—C, G, or T..")
11
An example of a SNP is the alteration of the DNA segment AAGGTTA to ATGGTTA, where the second "A" in the first snippet is replaced with a "T". SNPs found within a coding sequence are of particular interest to researchers because they are more likely to alter the biological function of a protein. Because of the recent advances in technology, coupled with the unique ability of these genetic variations to facilitate gene identification, there has been a recent flurry of SNP discovery and detection.

12
Because SNPs occur frequently throughout the genome and tend to be relatively stable genetically, they serve as excellent biological markers. Biological markers are segments of DNA with an identifiable physical location that can be easily tracked and used for constructing a chromosome map that shows the positions of known genes, or other markers, relative to each other. These maps allow researchers to study and pinpoint traits resulting from the interaction of more than one gene. NCBI plays a major role in facilitating the identification and cataloging of SNPs through its creation and maintenance of the public SNP database (dbSNP).dbSNP This powerful genetic tool may be accessed by the biomedical community worldwide and is intended to stimulate many areas of biological research, including the identification of the genetic components of disease.
.dbSNP This powerful genetic tool may be accessed by the biomedical community worldwide and is intended to stimulate many areas of biological research, including the identification of the genetic components of disease..")
13
What Are ESTs and How Are They Made? An expressed sequence tag or EST is a short sub-sequence of a transcribed cDNA sequence. They may be used to identify gene transcripts, and are instrumental in gene discovery and gene sequence determination. The identification of ESTs has proceeded rapidly, with approximately 65.9 million ESTs now available in public databases An EST is produced by one-shot sequencing of a cloned mRNA (i.e. sequencing several hundred base pairs from an end of a cDNA clone taken from a cDNA library). The resulting sequence is a relatively low quality fragment whose length is limited by current technology to approximately 500 to 800 nucleotides. Because these clones consist of DNA that is complementary to mRNA, the ESTs represent portions of expressed genes.
. The resulting sequence is a relatively low quality fragment whose length is limited by current technology to approximately 500 to 800 nucleotides. Because these clones consist of DNA that is complementary to mRNA, the ESTs represent portions of expressed genes..")
14
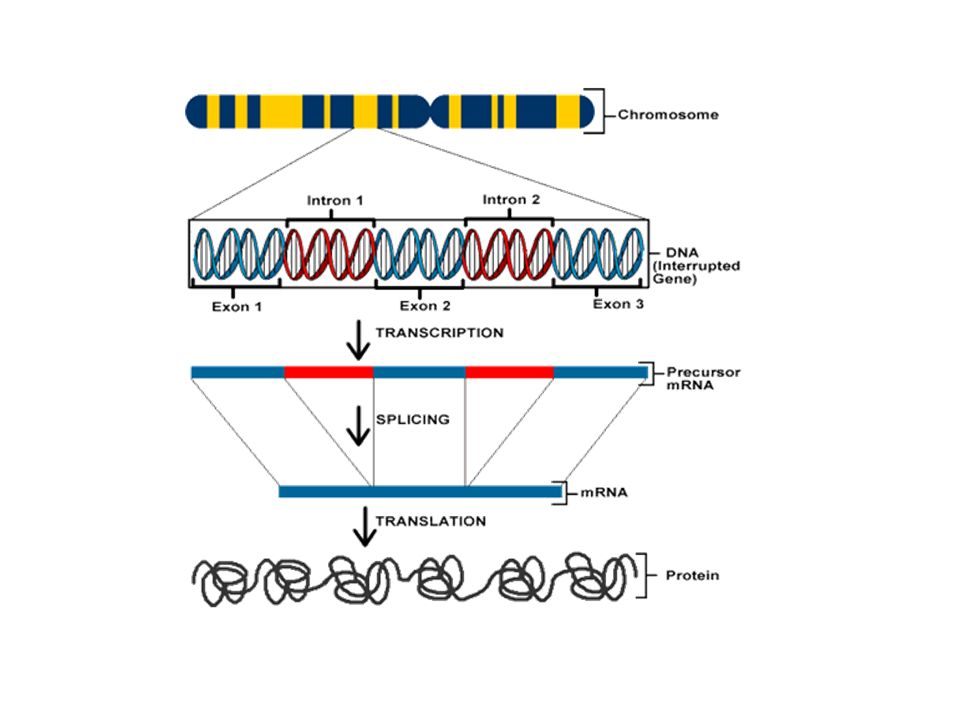
Gene identification is very difficult in humans, because most of our genome is composed of introns interspersed with a relative few DNA coding sequences, or genes. These genes are expressed as proteins, a complex process composed of two main steps. Each gene (DNA) must be converted, or transcribed, into messenger RNA (mRNA), RNA that serves as a template for protein synthesis. The resulting mRNA then guides the synthesis of a protein through a process called translation. Interestingly, mRNAs in a cell do not contain sequences from the regions between genes, nor from the non-coding introns that are present within many genes. Therefore, isolating mRNA is key to finding expressed genes in the vast expanse of the human genome.
 must be converted, or transcribed, into messenger RNA (mRNA), RNA that serves as a template for protein synthesis. The resulting mRNA then guides the synthesis of a protein through a process called translation. Interestingly, mRNAs in a cell do not contain sequences from the regions between genes, nor from the non-coding introns that are present within many genes. Therefore, isolating mRNA is key to finding expressed genes in the vast expanse of the human genome..")
16
In genetics, complementary DNA (cDNA) is DNA synthesized from a mature mRNA template in a reaction catalyzed by the enzyme reverse transcriptase and the enzyme DNA polymerase. cDNA is often used to clone eukaryotic genes in prokaryotes. When scientists want to express a specific protein in a cell that does not normally express that protein, they will transfer the cDNA that codes for the protein to the recipient cell. cDNA is also produced by retroviruses (such as HIV-1, HIV-2, Simian Immunodeficiency Virus, etc.) which is integrated into its host to create a provirus.
 which is integrated into its host to create a provirus..")
17
DNA Library In molecular biology, a library is a collection of DNA fragments that is stored and propagated in a population of micro-organisms through the process of molecular cloning. There are different types of DNA libraries, including cDNA libraries (formed from reverse-transcribed RNA) and genomic libraries (formed from genomic DNA). DNA library technology is a main stay of current molecular biology, and the applications of these libraries depends on the source of the original DNA fragments. There are differences in the cloning vectors and techniques used in library preparation, but in general each DNA fragment is uniquely inserted into a cloning vector and the pool of recombinant DNA molecules is then transferred into a population of bacteria or yeast such that each organism contains on average one construct (vector + insert). the population of organisms is grown in culture, the DNA molecules contained within them are copied and propagated (thus, "cloned").
 and genomic libraries (formed from genomic DNA). DNA library technology is a main stay of current molecular biology, and the applications of these libraries depends on the source of the original DNA fragments. There are differences in the cloning vectors and techniques used in library preparation, but in general each DNA fragment is uniquely inserted into a cloning vector and the pool of recombinant DNA molecules is then transferred into a population of bacteria or yeast such that each organism contains on average one construct (vector + insert). the population of organisms is grown in culture, the DNA molecules contained within them are copied and propagated (thus, cloned )..")
18
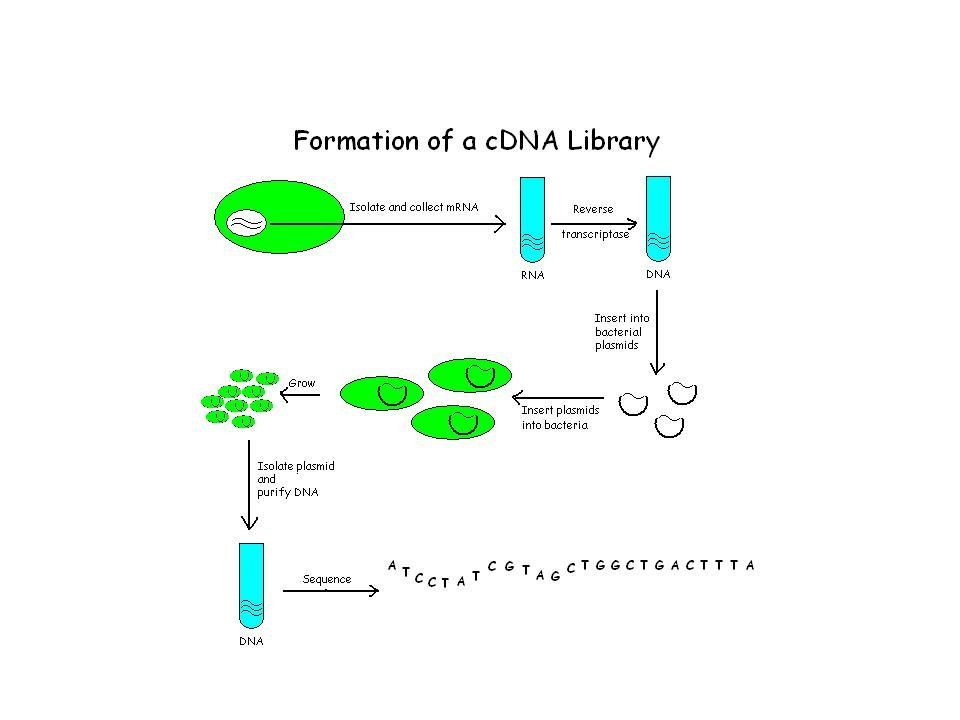
cDNA library A cDNA library represents a sample of the mRNA purified from a particular source (either a collection of cells, a particular tissue, or an entire organism), which has been converted back to a DNA template by the use of the enzyme reverse transcriptase. It thus represents the genes that were being actively transcribed in that particular source under the physiological, developmental, or environmental conditions that existed when the mRNA was purified. cDNA libraries can be generated using techniques that promote "full-length" clones or under conditions that generate shorter fragments used for the identification of "expressed sequence tags".

19
cDNA libraries are useful in reverse genetics, but they only represent a very small (less than 1%) portion of the overall genome in a given organism. Applications of cDNA libraries include: (1)Discovery of novel genes (2) Cloning of full-length cDNA molecules for in vitro study of gene function (3) Study of the of mRNAs expressed in different cells or tissues (4) Study of alternative splicing in different cells or tissues
Discovery of novel genes (2) Cloning of full-length cDNA molecules for in vitro study of gene function (3) Study of the of mRNAs expressed in different cells or tissues (4) Study of alternative splicing in different cells or tissues.")
20
cDNA is created from a mature mRNA from a eukaryotic cell with the use of an enzyme known as reverse transcriptase. In eukaryotes, a poly-(A) tail (consisting of a long sequence of adenine nucleotides) distinguishes mRNA from tRNA and rRNA and can therefore be used as a primer site for reverse transcription. mRNA extraction Firstly, the mRNA is obtained and purified from the rest of the RNAs. Several methods exist for purifying RNA such as trizol extraction and column purification. Column purification is done by using oligomeric dT nucleotide coated resins where only the mRNA having the poly-A tail will bind. The rest of the RNAs are eluted out. The mRNA is eluted by using eluting buffer and some heat to separate the mRNA strands from oligo-dT.
 tail (consisting of a long sequence of adenine nucleotides) distinguishes mRNA from tRNA and rRNA and can therefore be used as a primer site for reverse transcription. mRNA extraction Firstly, the mRNA is obtained and purified from the rest of the RNAs. Several methods exist for purifying RNA such as trizol extraction and column purification. Column purification is done by using oligomeric dT nucleotide coated resins where only the mRNA having the poly-A tail will bind. The rest of the RNAs are eluted out. The mRNA is eluted by using eluting buffer and some heat to separate the mRNA strands from oligo-dT..")
21
cDNA construction Once mRNA is purified, oligo-dT (a short sequence of deoxy-thymine nucleotides) is tagged as a complementary primer which binds to the poly- A tail providing a free 3'-OH end that can be extended by reverse transcriptase to create the complementary DNA strand. Now, the mRNA is removed by using a RNAse enzyme leaving a single stranded cDNA (sscDNA). This sscDNA is converted into a double stranded DNA with the help of DNA polymerase. However, for DNA polymerase to synthesize a complementary strand a free 3'-OH end is needed. This is provided by the sscDNA itself by generating a hair pin loop at the 3' end by coiling on itself.
. This sscDNA is converted into a double stranded DNA with the help of DNA polymerase. However, for DNA polymerase to synthesize a complementary strand a free 3 -OH end is needed. This is provided by the sscDNA itself by generating a hair pin loop at the 3 end by coiling on itself..")
22
The polymerase extends the 3'-OH end and later the loop at 3' end is opened by the scissoring action of S 1 nuclease. Restriction endonucleases and DNA ligase are then used to clone the sequences into bacterial plasmids. The cloned bacteria are then selected, commonly through the use of antibiotic selection. Once selected, stocks of the bacteria are created which can later be grown and sequenced to compile the cDNA library.

24
The problem, however, is that mRNA is very unstable outside of a cell; therefore, scientists use special enzymes to convert it to complementary DNA (cDNA). cDNA is a much more stable compound and, importantly, because it was generated from a mRNA in which the introns have been removed, cDNA represents only expressed DNA sequence. cDNA is a form of DNA prepared in the laboratory using an enzyme called reverse transcriptase. cDNA production is the reverse of the usual process of transcription in cells because the procedure uses mRNA as a template rather than DNA. Unlike genomic DNA, cDNA contains only expressed DNA sequences, or exons.

25
Once cDNA representing an expressed gene has been isolated, scientists can then sequence a few hundred nucleotides from either end of the molecule to create two different kinds of ESTs. Sequencing only the beginning portion of the cDNA produces what is called a 5' EST. A 5' EST is obtained from the portion of a transcript that usually codes for a protein. These regions tend to be conserved across species and do not change much within a gene family. Sequencing the ending portion of the cDNA molecule produces what is called a 3' EST. Because these ESTs are generated from the 3' end of a transcript, they are likely to fall within non-coding, or untranslated regions (UTRs), and therefore tend to exhibit less cross-species conservation than do coding sequences.
, and therefore tend to exhibit less cross-species conservation than do coding sequences..")
26
ESTs are generated by sequencing cDNA, which itself is synthesized from the mRNA molecules in a cell. The mRNAs in a cell are copies of the genes that are being expressed. mRNA does not contain sequences from the regions between genes, nor from the non-coding introns that are present within many interesting parts of the genome.

28
Because ESTs represent a copy of just the interesting part of a genome, that which is expressed, they have proven themselves again and again as powerful tools in the hunt for genes involved in hereditary diseases. ESTs also have a number of practical advantages in that their sequences can be generated rapidly and inexpensively, only one sequencing experiment is needed per each cDNA generated, and they do not have to be checked for sequencing errors because mistakes do not prevent identification of the gene from which the EST was derived.

29
Genomic libraries A genomic library is a set of clones that together represents the entire genome of a given organism. The number of clones that constitute a genomic library depends on (1) the size of the genome in question and (2) the insert size tolerated by the particular cloning vector system. For most practical purposes, the tissue source of the genomic DNA is unimportant because each cell of the body contains virtually identical DNA (with some exceptions).
 the size of the genome in question and (2) the insert size tolerated by the particular cloning vector system. For most practical purposes, the tissue source of the genomic DNA is unimportant because each cell of the body contains virtually identical DNA (with some exceptions)..")
30
Applications of genomic libraries include: (1) Determining the complete genome sequence of a given organism (2) Serving as a source of genomic sequence for generation of transgenic animals through genetic engineering (3) Study of the function of regulatory sequences in vitro (4) Study of genetic mutations in cancer tissues
 Determining the complete genome sequence of a given organism (2) Serving as a source of genomic sequence for generation of transgenic animals through genetic engineering (3) Study of the function of regulatory sequences in vitro (4) Study of genetic mutations in cancer tissues")
31
dbEST: A Descriptive Catalog of ESTs Scientists at NCBI created dbEST to organize, store, and provide access to the great mass of public EST data that has already accumulated and that continues to grow daily. Using dbEST, a scientist can access not only data on human ESTs but information on ESTs from over 300 other organisms as well. Whenever possible, NCBI scientists annotate the EST record with any known information. For example, if an EST matches a DNA sequence that codes for a known gene with a known function, that gene's name and function are placed on the EST record. Annotating EST records allows public scientists to use dbEST as an avenue for gene discovery. By using a database search tool, such as NCBI’s BLAST, any interested party can conduct sequence similarity searches against dbEST.

Similar presentations















 Lecture 11 Biotechnology (Text Chapters: 10.15-10.17; 31.1-31.10)>")
>")



