Download presentation
Presentation is loading. Please wait.

1
Introduction to Microarray Gene Expression
Shyamal D. Peddada Biostatistics Branch National Inst. Environmental Health Sciences (NIH) Research Triangle Park, NC
 Research Triangle Park, NC.")
2
Outline of the four talks
A general overview of microarray data Some important terminology and background Various platforms Sources of variation Normalization of data Analysis of gene expression data - Nominal explanatory variables Two types of explanatory variables Scientific questions of interest A brief discussion on false discovery rate (FDR) analysis Some existing methods of analysis.
 analysis. Some existing methods of analysis.")
3
Outline of the four talks
Analysis of ordered gene expression data Common experimental designs Some existing statistical methods An example Demonstration of ORIOGEN Some open research problems Analysis of data from cell-cycle experiments Some background on cell-cycle experiments Modeling the data Data from multiple experiments Some open research problem

4
Talk 1: An overview of microarray data

5
To perform statistical analysis of any given data
It is important to understand all sources of (i) bias, (ii) variability. Some basic understanding of the underlying technology! Understand the sampling/experimental design
 bias, (ii) variability. Some basic understanding of the underlying technology! Understand the sampling/experimental design.")
6
Some Important Terminology and Background

7
Central Dogma of Molecular Biology

8
Some background terminology: DNA and RNA
DNA (Deoxyribonucleic acid) - Contains genetic code or instructions for the development and function living organisms. It is double stranded. Four Nucleotides (building blocks of DNA) Adenine (A), Guanine (G), Thymine (T), Cytosine (C) Base pairs: (A, T) (G, C) E.g ’ ---AAATGCAT---3’ 3’ ---TTTACGTA---5’
 - Contains genetic code or instructions for the development and function living organisms. It is double stranded. Four Nucleotides (building blocks of DNA) Adenine (A), Guanine (G), Thymine (T), Cytosine (C) Base pairs: (A, T) (G, C) E.g. 5’ ---AAATGCAT---3’ 3’ ---TTTACGTA---5’")
9
Some background terminology: DNA and RNA
RNA (Ribonucleic acid) - transcribed (or copied) from DNA. It is single stranded. (Complimentary copy of one of the strands of DNA) RNA polymerase - An enzyme that helps in the transcription of DNA to form RNA. Four Nucleotides (building blocks of DNA) Adenine (A), Guanine (G), Uracil (U), Cytosine (C) Base pairs: (A, U) (G, C)
 - transcribed (or copied) from DNA. It is single stranded. (Complimentary copy of one of the strands of DNA) RNA polymerase - An enzyme that helps in the transcription of DNA to form RNA. Four Nucleotides (building blocks of DNA) Adenine (A), Guanine (G), Uracil (U), Cytosine (C) Base pairs: (A, U) (G, C)")
10
Some background terminology: Types of RNA
Types of RNA - (transfer) tRNA, (ribosomal) rRNA, etc. mRNA - messenger RNA. Carries information from DNA to ribosomes where protein synthesis takes place (less stable than DNA).
 tRNA, (ribosomal) rRNA, etc. mRNA - messenger RNA. Carries information from DNA to ribosomes where protein synthesis takes place (less stable than DNA).")
11
Some background terminology: Oligos
Oligonucleotide - a short segment of DNA consisting of a few base pairs. In short it is commonly called “Oligo”. “mer” - unit of measurement for an Oligo. It is the number of base pairs. So 30 base pair Oligo would be 30-mer long.

12
Some background terminology: Probes
cDNA - complimentary DNA. DNA sequence that is complimentary to the given mRNA. Obtained using an enzyme called reverse transcriptase. Probes - a short segment of DNA (about 100-mer or longer) used to detect DNA or RNA that compliments the sequence present in the probe.
 used to detect DNA or RNA that compliments the sequence present in the probe.")
13
Some background terminology: “Blots” - Origins of Microarrays
Southern blot (Edwin Southern, 1975 J. Molec. Biol.) A method used to identify the presence of a DNA sequence in a sample of DNA. Western blot (immunoblot) to identify a specific protein from a tissue extract.
 A method used to identify the presence of a DNA sequence in a sample of DNA. Western blot (immunoblot) to identify a specific protein from a tissue extract.")
14
Some background terminology
Southwestern blot to identify and characterize DNA-binding proteins. Northern blot A method used to study the gene expression from a sample of mRNA.

15
Microarrays …

16
Northern blot Vs Microarray
Rate of expression analysis Thousands of genes at a time (High throughput) Few genes at a time Automation Automation possible Manual Scope Allows to explore relationships among several 100’s of genes at the same time Limited
 Few genes at a time. Automation. Automation possible. Manual. Scope. Allows to explore relationships among several 100’s of genes at the same time. Limited.")
17
What is a Microarray? Sequences from thousands of different genes are immobilized, or attached, at fixed locations. Spotted, or actually synthesized directly onto the support.

18
Microarray Technology
Two color dye array (Spotted array) Spotted cDNA microarrays Spotted oligo microarrays Single dye array In situ oligo microarrays
 Spotted cDNA microarrays. Spotted oligo microarrays. Single dye array. In situ oligo microarrays.")
19
Microarray Technology

20
Spotted Microarrays

21
Spotted DNA Microarray
Slides carrying spots of target DNA are hybridized to fluorescently labeled cDNA from experimental and control cells and the arrays are imaged at two or more wavelengths Expression profiling involves the hybridization of fluorescently labeled cDNA, prepared from cellular mRNA, to microarrays carrying thousands of unique sequences.

22
Spotted DNA Microarray
Spotted DNA array is typically “home made” so you need to think about: cDNA or Oligo Location of the Oligo in a given gene Oligo length - number of bp?

23
Spotted DNA Microarray
Gene expression: Y < 0; gene is over expressed in green labeled sample compared to red-labeled sample Y = 0; gene is equally expressed in both samples Y > 0; gene is over expressed in red-labeled sample compared to green labeled sample

24
Single Dye Microarrays

25
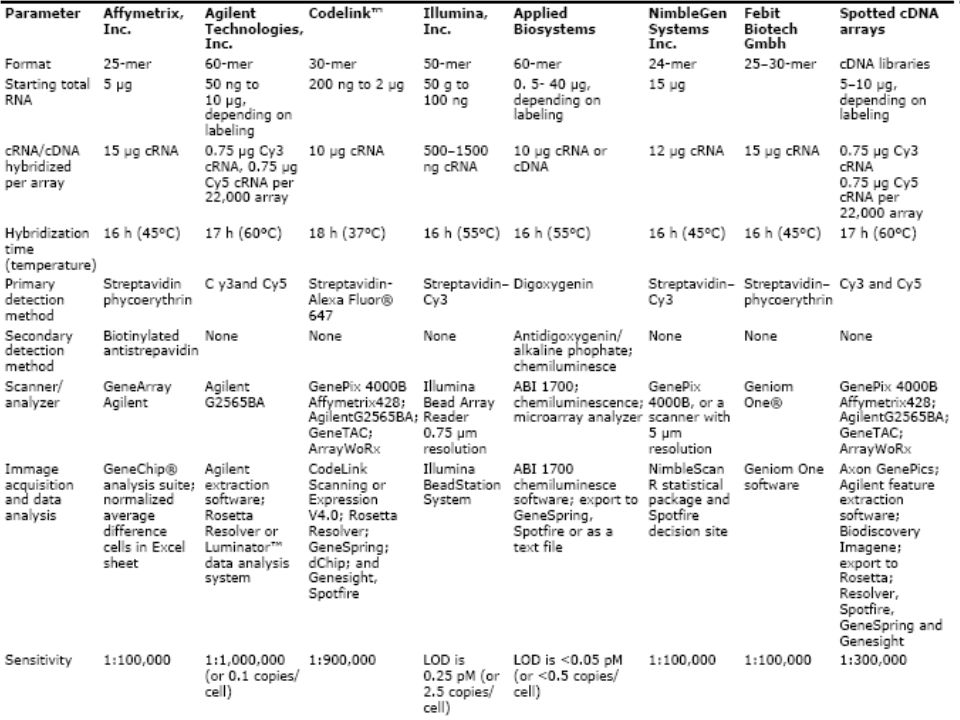
Major Commercial Platforms
More than 50 companies are currently offering various DNA microarray platforms, reagents and software Affymetrix dominated the marker for many years *Agilent has one and two-color microarray platform

26
Affymetrix GeneChip Each gene is represented by 11 to 20 oligos of 25-mers Probe: An oligo of 25-mer Probe Pair: a PM and MM pair Perfect match (PM): A 25-mer complementary to a reference sequence of interest (part of the gene) Mismatch (MM): same as PM with a single base change for the middle (13th) base (G <-> C, A <-> T) Probe set: a collection of probe-pairs (11 to 20) related to a fraction of gene
: A 25-mer complementary to a reference sequence of interest (part of the gene) Mismatch (MM): same as PM with a single base change for the middle (13th) base (G <-> C, A <-> T) Probe set: a collection of probe-pairs (11 to 20) related to a fraction of gene.")
27
Affymetrix call for the presence of a signal
Affymetrix detection algorithm uses probe pair intensities to obtain detection p-value Using this p-value they decide whether the signal is “ present”, “marginal” or “absent”

28
Affy call Detection of p-value
Calculate Kendall’s tau T for each probe pair T = (PM-MM) / (PM+MM) Determine the statistical significance of the gene by computing the p-value.
 / (PM+MM) Determine the statistical significance of the gene by computing the p-value.")
29
Affy call Ref: Affymetrix Technical Manual

30
Affymetrix Vs Illumina
Ref: Pan Du & Simon Lin

32
Which Platform to Choose?
Every platform has its unique feature Choose platform based on Nature of the study Amount of available RNA Cost Platform comparison in MAQC study

33
MAQC Project Objective: To generate a set of quality control tools for microarray research community 137 participants representing 51 organizations Gene expression from two distinct RNA samples (total 4 samples) Sample A = Universal Human Reference RNA(UHRR)–100% Sample B = Human Brain Reference RNA(HBRR) – 100% Sample C = 75% UHRR + 25% HBRR Sample D = 25% UHRR + 75% HBRR
 Sample A = Universal Human Reference RNA(UHRR)–100% Sample B = Human Brain Reference RNA(HBRR) – 100% Sample C = 75% UHRR + 25% HBRR. Sample D = 25% UHRR + 75% HBRR.")
34
Microarray Data Analysis

35
Why Normalize Data? To “calibrate”/adjust data so as to reduce or eliminate the effects arising from variation in technology and other sources rather than due to true biological differences between test groups.

36
Sources of bias/variation
Tissue or cell lines mRNA It can degrade over time - so there is a potential batch effect if portions of experiment are performed at different times Purity and quantity Dye color effect (spotted arrays) Variation due to technology - is substantially reduced with improved technology Etc.
 Variation due to technology - is substantially reduced with improved technology. Etc.")
37
A useful graphical representation of data
Data matrix: Let

38
A useful graphical representation of data
Let its spectral decomposition be given by where

39
A useful graphical representation of data
Then Plot

40
Common Normalization Methods
Internal Control Normalization Global Normalization Linear Normalization (Spotted arrays) Non-linear Normalization Method (Spotted arrays) - LOWESS curve. ANOVA COMBAT (for batch effect)
 Non-linear Normalization Method (Spotted arrays) - LOWESS curve. ANOVA. COMBAT (for batch effect)")
41
Internal control normalization (Housekeeping gene(s))
Expression of each gene is measured relative to the average of house keeping genes. Basic assumption: Expression of housekeeping genes does not change. Disadvantage: House keeping genes may be highly expressed sometimes. Unexpected regulation of house keeping gene(s) leads to misinterpretation
 leads to misinterpretation.")
42
Global Normalization Basic assumption Regression of
Mean/Median expression ratio of all monitored mRNAs is constant across a chip. Regression of In simple terms the log ratios are corrected by a common “mean” or “median” This method can also be applied to single Dye data

43
Linear Normalization (for spotted arrays)
Basic assumption Mean/Median expression ratio of all monitored mRNAs depends upon the average intensity Regression of

44
Non-Linear Normalization (for spotted arrays)
Basic assumption Mean/Median expression ratio of all monitored mRNAs depends upon the average intensity Regression of Where is estimated by the robust scatter plot smoother LOWESS (Locally WEighted Scatterplot Smoothing)
")
45
Analysis of Variance (ANOVA)
Standard Analysis of Variance model Response variable - Gene expression Explanatory variables: Dye color Batch Other potential effects? Advantage: Statistically significant genes can be identified while controlling for the various experimental conditions/factors.

46
Some important experimental designs
Pooled Samples versus Separate samples Sometimes there may not be sufficient biological sample/specimen from a given animal. In such cases biological samples are pooled from several identical animals to form a sample.

47
An example of a pooling design (for each treatment group)
Subjects Pool Observations (Microarray chips)
")
48
The pooling design Subjects Pool Observations (Microarray chips) 9 3 6
(3 per pool) More generally: n p m (r=n/p per pool)
 More generally: n p m. (r=n/p per pool)")
49
The standard design Subjects # Pool Observations (Microarray chips)
(r=1) More generally: n p=n m=n
 More generally: n p=n m=n.")
50
Some issues What are the underlying parameters?
Effect of pooling on power. The basic assumption. Validity of the assumption.

51
Parameters Total variation in the expression of a gene can be decomposed in to: Biological variation Technical variation Biological samples (n) Number of pools (p) Biological samples per pool (r=n/p) Observed number of samples (e.g. microarrays) (m)
 Number of pools (p) Biological samples per pool (r=n/p) Observed number of samples (e.g. microarrays) (m)")
52
Some comments about pooling
Variance of the estimated mean expression of a gene depends on: number of pools (p) number of bio samples per pool (r) number of arrays (m) biological variation Technical variation. Pooling works well when the biological variation in the gene expression is substantially larger than the technical variation.
 number of bio samples per pool (r) number of arrays (m) biological variation. Technical variation. Pooling works well when the biological variation in the gene. expression is substantially larger than the technical variation.")
53
Power comparisons # Bio #Micro Pool size Power
5/group 5/group 1 (Standard design) 6/group 6/group 1 (Standard design) 6/group 3/group 2 (i.e 3 pools/group) 8/group 4/group (i.e. 4 pools/group) 10/group 5/group (i.e. 5 pools/group) Zhang and Gant (2005)
 /group 6/group 1 (Standard design) /group 3/group 2 (i.e 3 pools/group) /group 4/group 2 (i.e. 4 pools/group) /group 5/group 2 (i.e. 5 pools/group) Zhang and Gant (2005)")
54
Power comparisons Conditions of the simulation study:
Biological variation is 4 times the technical variation. False positive rate is Detect 2-fold expression. Data are normally distributed.

55
A fundamental assumption
Biological averaging: Suppose an experiment consists of pooling “r” samples. Then the expression of a gene in the pooled sample is assumed to be the average of the gene’s expression in the “r” samples. This assumption need not be true especially if the expression values are transformed non-linearly.

56
Some important experimental designs
Reference designs (Spotted array) Each treatment sample is hybridized against a common reference control. Loop designs (Spotted array) Suppose we have a control and three experimental groups A, B and C. Then hybridize Control and A, A with B, B with C and C with A.
 Each treatment sample is hybridized against a common reference control. Loop designs (Spotted array) Suppose we have a control and three experimental groups A, B and C. Then hybridize Control and A, A with B, B with C and C with A.")
57
Data Analysis - Preliminaries
Normalization Transformation of data (usual methods) Perhaps first fit ANOVA and plot the residuals Log transformation Square root More generally, Box-Cox family of transformations Identify potential outliers in the data (again, perhaps use the residuals)
 Perhaps first fit ANOVA and plot the residuals. Log transformation. Square root. More generally, Box-Cox family of transformations. Identify potential outliers in the data (again, perhaps use the residuals)")
58
Data Analysis Method of Analysis depends upon the scientific question of interest. In the next three lectures we describe several general methods and illustrate some using real data!

Similar presentations







 Allows study of thousands of genes at.>")



 Trupti Joshi Computer Science Department 317 Engineering Building North 573-884-3528(O)>")







