Download presentation
Presentation is loading. Please wait.

1
Why do people use LOCF? Or why not?
Naitee Ting, Allison Brailey Pfizer Global R&D CT Chapter Mini Conference

2
Outline Last Observation Carried Forward (LOCF) Data set description
Modeling approaches Concerns in clinical Trials SAP concerns Why or why not use LOCF

3
Observed data from each patient over time

4
Complete Data

5
Last-Observation-Carried-Forward

6
LOCF Conservative? Or anti-conservative? Biased point estimate
May underestimate variance

9
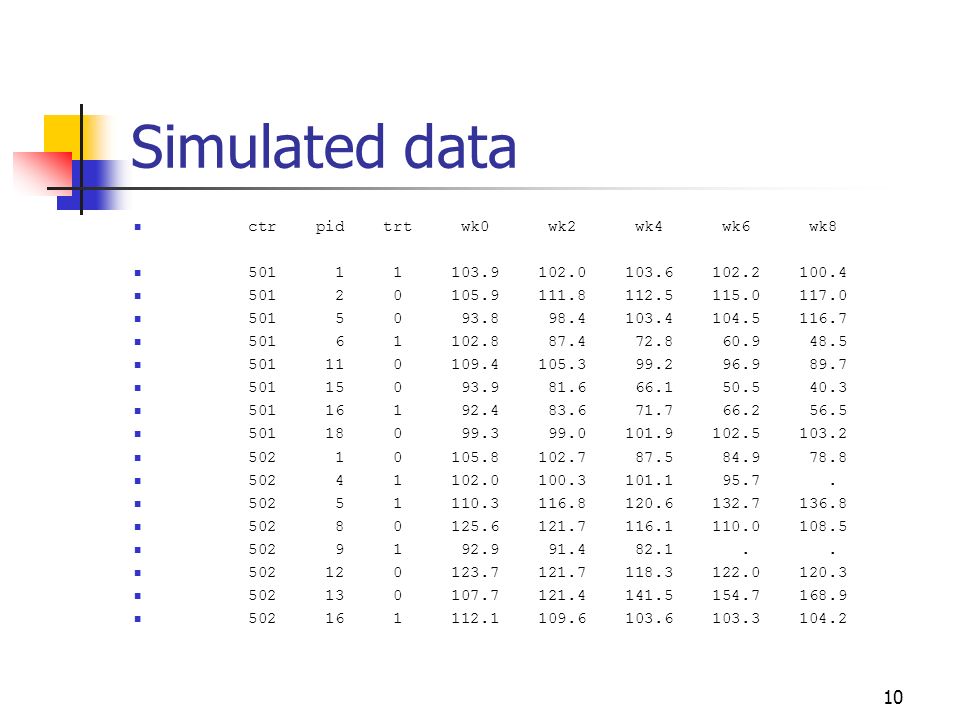
Data set Simulated - standing diastolic BP
Eight week study of test drug vs placebo Clinic visit every 2 weeks Primary endpoint – change in standing BP from baseline to week 8 Patients completed the study or dropped out at various time points Missing completely at random

10
Simulated data ctr pid trt wk0 wk2 wk4 wk6 wk8
11
Modeling approaches Many proposals to deal with dropouts
Mixed model approach Repeated measures Random intercept, random slope Single imputation Multiple imputation Imputation model Analysis model

12
ANCOVA on LOCF data TREATMENT | 1 2441.0 4.13 0.0444
Source | df MS F p-Value TREATMENT | CENTER | BASELINE | ERROR | Statistic Test Drug Placebo Raw Mean Adj Mean Std Error N

13
Analysis of completed cases
Source | df MS F p-Value TREATMENT | CENTER | BASELINE | ERROR | Statistic Test Drug Placebo Raw Mean Adj Mean Std Error N

14
Naive interpretation If LOCF provides statistical significance
If completer analysis supports LOCF True story may lie between the two Clinical conclusion can be made

15
Mixed model analysis For demonstration purposes, only repeated measure results are presented proc mixed method=reml ; where week>0 ; class pid trt week ctr ; model y=wk0 trt ctr week trt*week/solution ; repeated week / type=cs subject=pid r rcorr ; estimate 'trt dif at week 8' trt -1 1 trt*week / cl alpha=0.05 ;

16
Results from PROC MIXED
Num Den Effect DF DF F Value Pr > F Baseline Treatment Center <.0001 Week Trt*week Standard Label Estimate Error DF t Value Pr > |t| week 8 dif

17
Single or multiple imputation
Mixed model can be considered as single imputation For imputation, we can use the same model for imputation and analysis However, one model can be used for imputation, but a different one is for analysis

18
Should LOCF be used? After the modeling approaches became available, use of LOCF have been discouraged Models are developed with assumptions More complicated models require more assumptions Are these assumptions justified?

19
Should LOCF be used? LOCF is a model and there are simple assumptions behind it In New Drug Applications (NDA), LOCF is still widely used Why?

20
Different phases in clinical trials
Phase I, II, III, IV Phase I – How often? Phase II – How much? Phase III – Confirm Phase IV – Post-Market

21
DOES THE DRUG WORK? Double-blind, placebo controlled, randomized clinical trial Test hypothesis - does the drug work? Null hypothesis (H0) - no difference between test drug and placebo Alternative hypothesis (Ha) - there is a difference
 - no difference between test drug and placebo. Alternative hypothesis (Ha) - there is a difference.")
22
TYPES OF ERRORS Regulatory agencies focus on the control of Type I error Probability of making a Type I error is not greater than a In general, a = 0.05; i.e., 1 in 20 Avoid inflation of this error Changing the method of analysis to fit data will inflate a

23
MULTIPLE COMPARISONS For 20 independent variables (clinical endpoints), one significant at random For 20 independent treatment comparisons, one significant at random Subgroup analyses can also potentially inflate a Multiple comparison adjustment

24
Report all data Scientific experiments generate data
Outliers may be observed Delete outlier? Clinical trials generate data A wonder drug cures 9,999 patients of 10,000 One died – outlier – delete?

25
Statistical Analysis Plan (SAP)
Pre-specification of analysis Prior to breaking blind Internal agreement within project team Binding document to communicate with regulatory authorities Use of LOCF or modeling approach need to be pre-specified in SAP

26
Modeling approaches Assumptions Can be complicated
Difficult to explain to end users George Box – “All models are wrong, some are useful”

27
Why LOCF? Or why not? Easy to understand
Easy to communicate between statisticians and clinicians, and between sponsor and regulators Lots of prior examples Biased point estimate, biased variance

28
Recommendations Understand the disease Understand data to be collected
Understand the dropout issues Make use of Phase II results Encourage use of statistical models LOCF may still be considered as supportive

Similar presentations
















 Hainan c agGY Ia-1 (2) Anhui agGY Ia-2 (3) agGY Ia-1 2 2 WD-2 WD-8 WD-36 agGY Ia-2 3 3.>")




