Download presentation
Presentation is loading. Please wait.

1
Beyond Content-Based Retrieval: Modeling Domains, Users, and Interaction Susan Dumais Microsoft Research http://research.microsoft.com/~sdumais IEEE ADL99 - May 21, 1998

2
Research in IR at MS zMicrosoft Research (http://research.microsoft.com) yAdaptive Systems and Interaction - IR/UI yMachine Learning and Applied Statistics yData Mining yNatural Language Processing yCollaboration and Education yDatabase yMSR Cambridge; MSR Beijing zMicrosoft Product Groups … many IR-related

3
IR Themes & Directions zImprovements in matching algorithms and representation yProbabilistic/Bayesian models xp(Relevant|Document), p(Concept|Words) yNLP: Truffle, MindNet zBeyond content-matching yUser/Task modeling yDomain/Object modeling yAdvances in presentation and manipulation WWW8 Panel Finding Anything in the Billion-Page Web: Are Algorithms the Answer? Moderator: Prabhakar Raghavan, IBM Almaden

4
Traditional View of IR Query Words Ranked List

5
Whats Missing? Query Words Ranked List User Modeling Domain Modeling Information Use

6
Domain/Obj Modeling zNot all objects are equal … potentially big win yA priori importance yInformation use (readware; collab filtering) zInter-object relationships yLink structure / hypertext ySubject categories - e.g., text categorization. text clustering zMetadata yE.g., reliability, recency, cost -> combining

7
User/Task Modeling zDemographics zTask -- Whats the users goal? ye.g., Lumiere zShort and long-term content interests ye.g., Implicit queries xInterest model = f(content_similarity, time, interest) ye.g., Letiza, WebWatcher, Fab
 ye.g., Letiza, WebWatcher, Fab.")
8
Information Use zBeyond batch IR model (query->results) yConsider larger task context zHuman attention is critical resource … no Moores Law for human capabilities yTechniques for automatic information summarization, organization, discover, filtering, mining, etc. zAdvanced UIs and interaction techniques yE.g, tight coupling of search, browsing to support information management

9
The Broader View of IR Query Words Ranked List User Modeling Domain Modeling Information Use

10
Beyond Content Matching zDomain/Object modeling èA priori importance èText classification and clustering zUser/Task modeling yImplicit queries and Lumiere zAdvances in presentation and manipulation yCombining structure and search (e.g., DM)
")
11
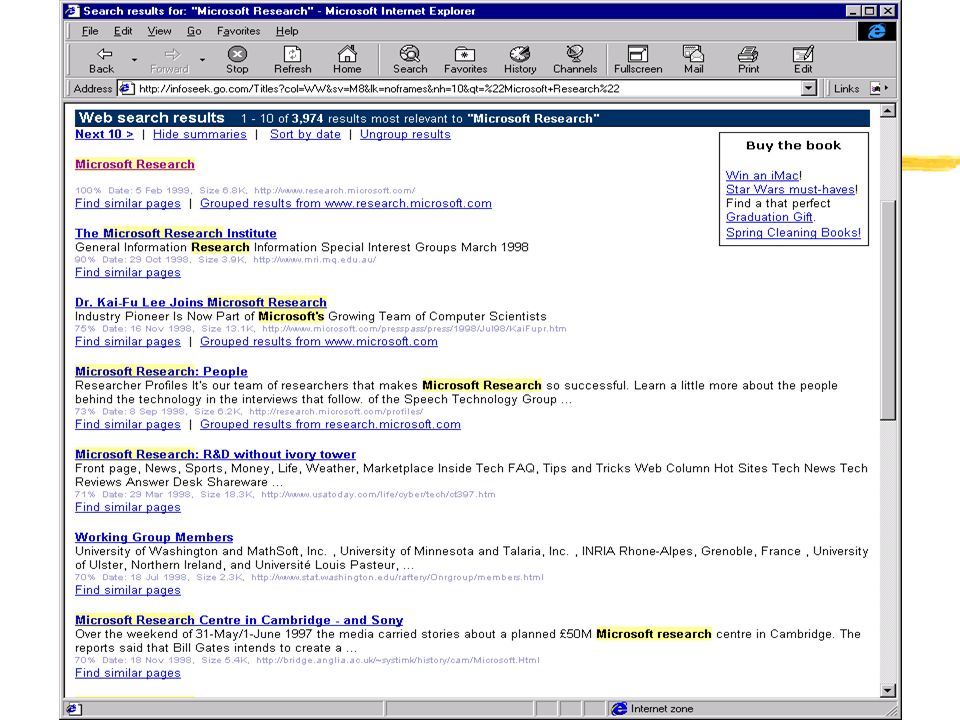
zExample: Web query for Microsoft Research

16
Estimating Priors zLink Structure yGoogle - Brin & Page yClever (Hubs/Authorities) - Kleinberg et al. yWeb Archeologist - Bharat, Henzinger ysimilarities to citation analysis zInformation Use yAccess Counts - e.g., DirectHit yCollaborative Filtering

17
New Relevance Ranking zRelevance ranking can include: ycontent-matching … of couse ypage/site popularity ypage quality yspam or porn or other downweighting yetc. zCombining these - relative weighting of these factors tricky and subjective

18
Text Classification zText Classification: assign objects to one or more of a predefined set of categories using text features yE.g., News feeds, Web data, OHSUMED, Email - spam/no-spam zApproaches: yHuman classification (e.g., LCSH, MeSH, Yahoo!, CyberPatrol) yHand-crafted knowledge engineered systems (e.g., CONSTRUE) *Inductive learning methods x(Semi-) automatic classification
 yHand-crafted knowledge engineered systems (e.g., CONSTRUE) *Inductive learning methods x(Semi-) automatic classification")
19
Inductive Learning Methods zSupervised learning from examples yExamples are easy for domain experts to provide yModels easy to learn, update, and customize zExample learning algorithms yRelevance Feedback, Decision Trees, Naïve Bayes, Bayes Nets, Support Vector Machines (SVMs) zText representation yLarge vector of features (words, phrases, hand-crafted)
 zText representation yLarge vector of features (words, phrases, hand-crafted)")
20
Support Vector Machine zOptimization Problem yFind hyperplane, h, separating positive and negative examples yOptimization for maximum margin: yClassify new items using: support vectors

21
Reuters Data Set ( 21578 - ModApte split) z9603 training articles; 3299 test articles zExample interest article 2-APR-1987 06:35:19.50 west-germany b f BC-BUNDESBANK-LEAVES-CRE 04-02 0052 FRANKFURT, March 2 The Bundesbank left credit policies unchanged after today's regular meeting of its council, a spokesman said in answer to enquiries. The West German discount rate remains at 3.0 pct, and the Lombard emergency financing rate at 5.0 pct. REUTER zAverage article 200 words long

22
Example: Reuters news z118 categories (article can be in more than one category) zMost common categories (#train, #test) zOverall Results yLinear SVM most accurate: 87% precision at 87% recall Trade (369,119) Interest (347, 131) Ship (197, 89) Wheat (212, 71) Corn (182, 56) Earn (2877, 1087) Acquisitions (1650, 179) Money-fx (538, 179) Grain (433, 149) Crude (389, 189)
 zMost common categories (#train, #test) zOverall Results yLinear SVM most accurate: 87% precision at 87% recall Trade (369,119) Interest (347, 131) Ship (197, 89) Wheat (212, 71) Corn (182, 56) Earn (2877, 1087) Acquisitions (1650, 179) Money-fx (538, 179) Grain (433, 149) Crude (389, 189)")
23
ROC for Category - Grain Recall: % labeled in category among those stories that are really in category Precision: % really in category among those stories labeled in category

24
Text Categ Summary z Accurate classifiers can be learned automatically from training examples z Linear SVMs are efficient and provide very good classification accuracy zWidely applicable, flexible, and adaptable representations yEmail spam/no-spam, Web, Medical abstracts, TREC

25
Text Clustering zDiscovering structure yVector-based document representation yEM algorithm to identify clusters zInteractive user interface

26
Text Clustering

27
Beyond Content Matching zDomain/Object modeling yA priori importance yText classification and clustering zUser/Task modeling èImplicit queries and Lumiere zAdvances in presentation and manipulation èCombining structure and search (e.g., DM)
")
28
Lumiere zInferring beliefs about users goals and ideal actions under uncertainty * User query User activity User profile Data structures Pr(Goals, Needs) E. Horvitz, et al.

29
Lumiere

30
Lumiere Office Assistant

31
Visualizing Implicit Queries zExplicit queries: ySearch is a separate, discrete task yResults not well integrated into larger task context zImplicit queries: ySearch as part of normal information flow yOngoing query formulation based on user activities yNon-intrusive results display

35
Data Mountain with Implicit Query results shown (highlighted pages to left of selected page).
.")
36
IQ Study: Experimental Details zStore 100 Web pages y50 popular Web pages; 50 random pages yWith or without Implicit Query highlighting xIQ0: No IQ xIQ1: Co-occurrence based IQ - best case xIQ2: Content-based IQ zRetrieve 100 Web pages yTitle given as retrieval cue -- e.g., CNN Home Page yNo implicit query highlighting at retrieval

37
Find: CNN Home Page

38
Results: Information Storage zFiling strategies

39
Results: Information Storage zNumber of categories ( for semantic organizers ) 7 Categ 23 Categ
 7 Categ 23 Categ")
40
Results: Retrieval Time

41
zLarge variability across users ymin: 3.1 secs ymax: 39.1 secs zLarge variability across queries ymin: 4.9 secs ( NASA home page ) ymax: 24.3 secs ( Welcome to Mercury Center ) zPopularity of Web pages did not matter yTop50: 12.9 secs yRandom50: 12.8 secs
 ymax: 24.3 secs ( Welcome to Mercury Center ) zPopularity of Web pages did not matter yTop50: 12.9 secs yRandom50: 12.8 secs")
42
Implicit Query Highlights zIQ built by observing users reading behavior yNo explicit search required yGood matches returned zIQ user model: yCombines present context (+ previous interests) zResults presented in the context of a user- defined organization
 zResults presented in the context of a user- defined organization")
43
Summary zImproving content-matching zAnd, beyond... yDomain/Object Models yUser/Task Models yInformation Presentation and Use zAlso … y non-text, multi-lingual, distributed zhttp://research.microsoft.com/~sdumais

44
The View from Wired, May 1996 zinformation retrieval seemed like the easiest place to make progress … information retrieval is really only a problem for people in library science -- if some computer scientists were to put their heads together, theyd probably have it solved before lunchtime [GS]
![The View from Wired, May 1996 zinformation retrieval seemed like the easiest place to make progress … information retrieval is really only a problem for people in library science -- if some computer scientists were to put their heads together, theyd probably have it solved before lunchtime [GS]](http://images.slideplayer.com/2/685811/slides/slide_44.jpg "The View from Wired, May 1996 zinformation retrieval seemed like the easiest place to make progress … information retrieval is really only a problem for people in library science -- if some computer scientists were to put their heads together, theyd probably have it solved before lunchtime [GS]")
Similar presentations








>")


 2.Ranked retrieval 3.Probabilistic retrieval.>")

>")




 Task 3.3.>")



 June 6, 2001 ©Prabhakar Raghavan.>")


