Download presentation
Presentation is loading. Please wait.

1
Fast and Reliable Estimation Schemes in RFID Systems Murali Kodialam and Thyaga Nandagopal Bell Labs, Lucent Technologies Presented by : Joseph Gunawan

2
Common problem that arise ESTIMATION Problem of quick estimation of the number of tags in the field up to a desired level of accuracy.

3
What is RFID? RFID, Radio Frequency Identification, is not a new subject that is going to be proposed anymore. It is an identification tag that stores the identity of something. It is very simple and cheap to be largely produced. It has been used in various application ranging from inventory control and tracking to medical-patient management.

4
What is RFID? (cont.) Most of them are designed to have a very long life. It is because they are not designed to use any existing energy sources for transmitting data. Instead, a probe signal sent by a reader node is used as energy for data transmission. The probe itself can be performed via magnetic coupling (called near-field) or electro-magnetic coupling (called far- field). Nowadays, the probe has much larger range and is designed to read hundreds of tags at a time.
 or electro-magnetic coupling (called far- field). Nowadays, the probe has much larger range and is designed to read hundreds of tags at a time..")
5
Classification of RFID Passive tags Semi-passive tags Active tags

6
Classification of RFID (cont.) Tags are considered as active or semi-passive tags if they have their own power source such as batteries. However, semi-passive tags do not use their power source for transmission, but use it primarily to derive other on- board circuitry. Therefore, to be able to derive and to identify things is the main goal of any RFID system.

7
Idea of RFID The idea is described as following: the reader probes a set of tags, and the tags reply back. Since it operates in the wireless medium, Collisions might happen in the process of probing a set of tags. To hinder the collisions, anti-collision schemes needed to be applied into the identification algorithms.

8
Identification Algorithm Probabilistic Deterministic

9
Probabilistic Identification Algorithm The reader communicates through a framed ALOHA scheme length and the tags pick a particular slot in the frame to transmit. This process is repeated by the reader until all tags have transmitted at least once successfully in a slot without collisions. In semi-passive and active tag systems, the reader can acknowledge tags that have succeeded at the end of each frame, therefore it shorts the overall identification time. In passive tags, all tags will continue to transmit in every frame, which lengthens the total time needed to identify all tags.

10
Deterministic Identification Algorithm The reader identifies the set of tags that need to transmit in a given slot, and tries to seduce the contending tag set in the next slot based on the result in the previous slot. These algorithms fall into the class of tree-based identification algorithms, such as a binary tree. On the binary tree, the tags are classified based on their id and the reader moving down the tree at each step to identify all nodes. Deterministic algorithms are typically faster than probabilistic schemes in terms of actual tag response slots used, however, they suffer from large reader overhead since address ranges need to be specified to isolate contending tag subsets using a probe at the beginning of each slot.

11
Algorithm Requirements. An estimation of the actual number of tags t in the system is required by both of the algorithms. The estimation is used: ◦To set the optimal frame size in framed ALOHA. ◦To guide the tree-based identification process for computing the expected number of slots needed for identification. The estimation process should also be able to use non- identifiable information, such as a string of bits used by all tags, to compute the size of the tag set t.

12
System Model A set of readers and many tags Use a Listen-before-Talk model approach, where tags listen to the reader’s request before they talk back.

13
System Model (cont.) Assumption on the model: There exist a separate estimation phase for identification process. Framed-slotted ALOHA model is used for tags to transmit back to the reader. The tags respond with a bit-string that contains some error-detection (such as CRC) embedded in the string when probed by the reader in the estimation phase. The length of this common bit-string is defined as the minimum length string such that the reader can detect collisions when multiple tags transmit the same string in a given slot. The reader can thus detect collisions in the estimation phase and identify a successful transmission in any slot by only one tag. There is no identification problem, also referred to as collision resolution or conflict resolution in related work.
 embedded in the string when probed by the reader in the estimation phase. The length of this common bit-string is defined as the minimum length string such that the reader can detect collisions when multiple tags transmit the same string in a given slot. The reader can thus detect collisions in the estimation phase and identify a successful transmission in any slot by only one tag. There is no identification problem, also referred to as collision resolution or conflict resolution in related work..")
14
System Model (cont.) The estimator performance is measured in terms of the number of slots needed to perform the estimation to the desired accuracy level. The goal is to achieve the desired performance in as little time as possible. In other words, if it takes le slots to compute ˆt, the estimate of t tags with a certain accuracy, and li slots to uniquely identify ˆt tags, then, we need se.le < li.si, where se and si are the sizes of the bit strings transmitted during the estimation and identification phases respectively.

15
System Model (cont.) Current Implementation : ◦Phillips I-Code system. ◦A frame size f (typically a power of 2) is sent by the readers along with a seed value which is 16-bit number. ◦The seed information along with its identifier used by the tag to hash into an integer in the range [1, f], which specifies the slot in which the frame will contend. ◦The reader sends a different seed in each frame to ensure tags do not necessarily select the same slot in each frame.
 is sent by the readers along with a seed value which is 16-bit number. ◦The seed information along with its identifier used by the tag to hash into an integer in the range [1, f], which specifies the slot in which the frame will contend. ◦The reader sends a different seed in each frame to ensure tags do not necessarily select the same slot in each frame..")
16
System Model (cont.) Model that is approached: ◦Extend the scheme to support variable contention probability p. ◦Therefore, the reader now sends three parameters in each probe: the seed the frame size f the integer [f/p] ◦The tag hashes the combined seed/identifier value into the range [1, [f/p]]. ◦If the hashed value is greater than f, then the tag does not transmit in this frame, else it transmit in the computed slot. ◦Therefore, a frame transmission probability of f/(f/p) = p.
 = p..")
17
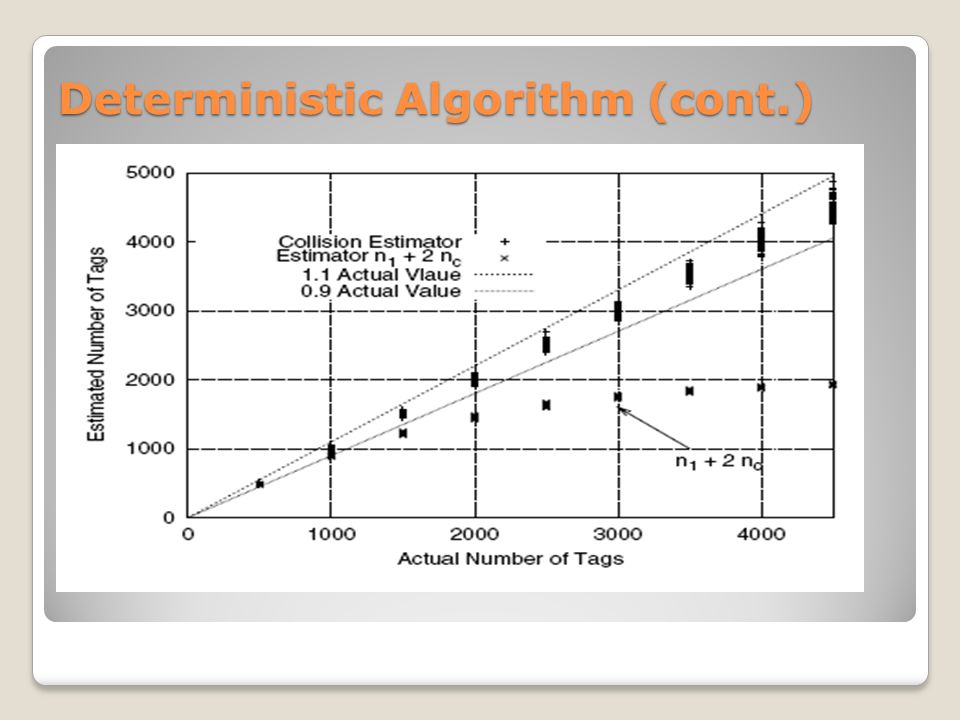
Deterministic Algorithm The reader probes the tags with the frame size f The tags pick a slot j in the frame uniformly at random and transmit in that slot. The indicator random variable Xj is used to determine whether tag transmit to and not transmit to in slot j. Xj = 1 if no tag transmit in slot j, referred as an empty slot, and Xj = 0 otherwise. Similarly, we set Yj = 1 if and only if there is exactly one tag that transmits in slot j, referred as a singleton slot, and Vj = 1 if and only if there are multiple tags that transmit in slot j, referred as a collision. So that, Xj + Yj + Vj = 1 for all slots j.

18
Deterministic Algorithm (cont.) Let N 0 = ∑ Xj from j = 1 to j = f denote the total number of empty slots. N 1 = ∑ Yj from j = 1 to j = f denote the total number of singleton slots. N c = f − N 0 − N 1 denote the number of collision slots. P = t/f, t denotes numbers of tags and f denotes frame size.

19
Deterministic Algorithm (cont.)
")
23
Probabilistic Algorithm (cont.)
")
Similar presentations

















>")



