Download presentation
Presentation is loading. Please wait.

1
7/14/2015EECS 584, Fall 20111 MapReduce: Simplied Data Processing on Large Clusters Yunxing Dai, Huan Feng

2
Real world problem Count the number of occurences of each word in a huge collections of word lists. –sample input: seven book of Harry Potter

3
Real world problem Count the number of occurences of each word in a huge collections of word lists. WordOccurences The15414 Good5435 Never6546 Tie694.......

4
Possible solution Hash table –each entry is key value pair, (word, occurrence) –scan all the file, put each word into the hash table
 –scan all the file, put each word into the hash table")
5
Real world problem--follow up What if you are given a huge set of files and have access to a large set of machines? Problem with hash table: –low concurrency –hard to scale one node fail, restart all work MapReduce solution

6
7/14/2015 EECS 584, Fall 20116 Map primitive Idea from functional language Given a function, apply the function to all element INDIVIDUALLY in the list, combine the result into a new list e.g. increment each elems from a list by 1

7
7/14/2015 EECS 584, Fall 20117 Reduce primitive Idea from functional language Apply a function to all elems from a list, combine them into a single resule e.g. calculate the sum of a list

8
Map reduce solution--Single node Map each single word into a (key, value) pair. –"Good" -> ("Good", 1) Put together all the pairs that have the same key. Input these pairs to a reduce program. Add the value together –[("Good", 1), ("Good", 1), ("Good", 1)] -> 3
 Put together all the pairs that have the same key. Input these pairs to a reduce program. Add the value together –[( Good , 1), ( Good , 1), ( Good , 1)] -> 3.")
9
Map reduce solution Files in_01 in_02 in_03 in_04 in_05... pairs (The, 1) (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...]....... Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery1....... Reduce
 (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...] Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery Reduce.")
10
Map reduce solution Files in_01 in_02 in_03 in_04 in_05... pairs (The, 1) (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...]....... Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery1....... Reduce
 (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...] Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery Reduce.")
11
Map reduce solution Files in_01 in_02 in_03 in_04 in_05... pairs (The, 1) (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...]....... Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery1....... Reduce
 (Good, 1) (The, 1) (Bad, 1) (Not, 1) (The, 1)... Map list of pairs [(The, 1), (The, 1), (The, 1)...] [(Good, 1), (Good, 1), (Good, 1)...] [(Is, 1), (Is, 1), (Is, 1)...] [(Therofiery, 1)] [(Bad, 1), (Bad, 1), (Bad, 1)...] Merge and Sort Reduce WordOccurences The15414 Good5435 Is6546 Therofiery Reduce.")
12
Map reduce solution What if now we are given a huge number of files. And a large number of machines.

13
It can be scalable! Map can be applied to different part of input in parallel. If part of map tasks failed, just need to restart them instead of restarting all.

14
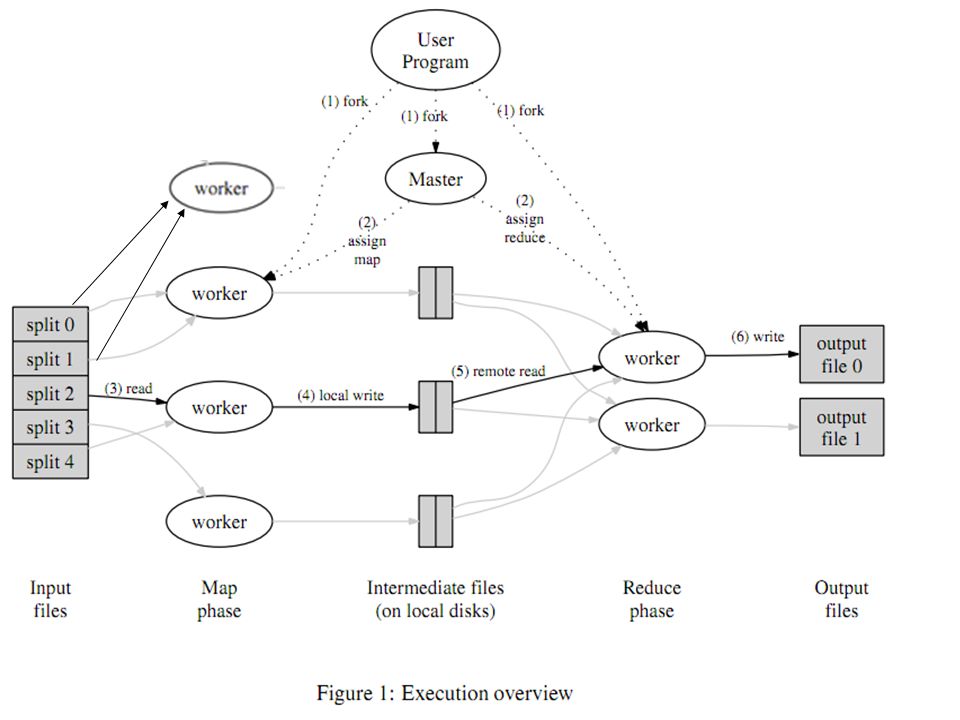
Map reduce solution-scalable version Map : split the file into several parts, apply map function to every part of them. Shuffle : distribute intemediate result into different buckets according to the hash value of key, assign buckets to several reducers. Each reducer sort the pairs by key. Reduce : apply the reduce function to all the elements that have the same key and produce the result.

15
MapReduce Gerneralized Software framework Users are only responsible for provide two functions : map and reduce Easy to scale to large amount of machines.

17
Split the input files into several pieces

18
Each piece is assigned to one worker(mapper)
")
19
Before sorting, the key value pairs are hashed by key into R buckets.

20
(The, 1), (Good, 1), (The 1), (Never, 1)
, (Good, 1), (The 1), (Never, 1)")
21
(Is, 1), (Is, 1), (Tie, 1), (Work, 1)
, (Is, 1), (Tie, 1), (Work, 1)")
22
(The, 1), (Good, 1), (The 1), (Never, 1) (Is, 1), (Is, 1), (Tie, 1), (Work, 1) Each bucket is read by one worker(reducer), then sort and produce the results.
, (Good, 1), (The 1), (Never, 1) (Is, 1), (Is, 1), (Tie, 1), (Work, 1) Each bucket is read by one worker(reducer), then sort and produce the results.")
23
Master program, control the process and assign work to workers

24
Fault tolerance worker fail : simply assigned the another worker to do it. master fail : restart the whole work

29
Implementation details Locality –Take location information of input files into account –assigned a map task to closest machine of the input data.

30
Implementation details Backup tasks –abnormal machines in a task lengthen the total time. –When a task is almost finished, duplicate remaining tasks as back-up tasks. –Whenever a primary or a backup execution is done, mark the task as finished. TASK1TASK2TASK3 In progress Completed

31
Implementation details Backup tasks –abnormal machines in a task lengthen the total time. –When a task is almost finished, duplicate remaining tasks as back-up tasks. –Whenever a primary or a backup execution is done, mark the task as finished. TASK1TASK2TASK3 In progress Completed

32
Implementation details Backup tasks –abnormal machines in a task lengthen the total time. –When a task is almost finished, duplicate remaining tasks as back-up tasks. –Whenever a primary or a backup execution is done, mark the task as finished. TASK1TASK2TASK3 In progress Completed TASK1 Back Up

33
Implementation details Backup tasks –abnormal machines in a task lengthen the total time. –When a task is almost finished, duplicate remaining tasks as back-up tasks. –Whenever a primary or a backup execution is done, mark the task as finished. TASK1TASK2TASK3 In progress Completed TASK1

34
7/14/2015 EECS 584, Fall 201134 Useful Extensions Partitioning Functions –hash-based or range-based –self-defined partition function Combiner Function (similar to Reduce Function) – –resolve significant repetition in intermediate outputs Skipping Bad Records –errors or bugs –acceptable to ignore a few records Local Execution –help facilitate debugging, profiling and testing
 – –resolve significant repetition in intermediate outputs Skipping Bad Records –errors or bugs –acceptable to ignore a few records Local Execution –help facilitate debugging, profiling and testing")
35
7/14/2015 EECS 584, Fall 201135 Performance & Evaluation Cluster Configuration –1800 nodes –2×2GHz, 4GB memory, 2×160GB IDE, Gb Ethernet link –2-level tree-shaped switched network Grep –in 10 10 100-byte records –M = 15000 R = 1 –take ~150 seconds

36
7/14/2015 EECS 584, Fall 201136 Performance & Evaluation (Sort) Sort –10 10 100-byte records –M = 15000, R = 4000 –Normal, No-Backup, 200 tasks killed A few things to note –Input rate is higher than the shuffle & output rate –no backup, execution flow is similar except the long tail –kill tasks, the tasks restarted & the rate drop to zero
 Sort – byte records –M = 15000, R = 4000 –Normal, No-Backup, 200 tasks killed A few things to note –Input rate is higher than the shuffle & output rate –no backup, execution flow is similar except the long tail –kill tasks, the tasks restarted & the rate drop to zero")
37
7/14/2015 EECS 584, Fall 201137

38
Application of MapReduce Broadly applicable –large-scale machine learning problems –clustering problems for Google News –extraction of data & properties –graph computations Large-Scale Indexing –The indexing code is simpler, smaller (~3800 to ~700) –Indexing process is much easier to operate & easy spead up
 –Indexing process is much easier to operate & easy spead up")
39
MapReduce & Parallel DBMS MapReduce is not novel at all –a entriely new paradigm? MapReduce is a step backwards –no schema –no high-level access language MapReduce Is a poor implementation –no Index –overlook skew –lots of P2P Network traffic in the shuffle phase Missing features –indexes, updates, transactions Not compatible to DBMS Tools

40
MapReduce & Parallel DBMS

41
Parallel database –has significant performance advantage –take a lot of time to tune and setup –are not general enough (UDFs, UDTs) –SQL is not that easy & straightforward MapReduce –easy to setup & easy to program –scalable & fault-tolerant –bruteforce solution
 –SQL is not that easy & straightforward MapReduce –easy to setup & easy to program –scalable & fault-tolerant –bruteforce solution")
42
What is MapReduce A parallel programming model /data processing paradigm rather than a complete DBMS –Does not target everything DBMS targets –It's simple but it works Works for those who –have a lot of data (of some specific type) –UDTs and UDFs are complex to tune –would rather program in sequencial language rather than SQL –no need to index data because data change all the time –do not need to pay
 –UDTs and UDFs are complex to tune –would rather program in sequencial language rather than SQL –no need to index data because data change all the time –do not need to pay")
43
Questions?

Similar presentations




>")

















 INTERESTS: SYSTEMS, WEB.>")
