Download presentation
Presentation is loading. Please wait.

1
Programming with CUDA WS 08/09 Lecture 3 Thu, 30 Oct, 2008

2
Previously CUDA programming model CUDA programming model –GPU as co-processor –Kernel definition and invocation –Thread blocks – 1D, 2D, 3D –Thread ID and threadIdx –Global/shared memory for threads –Compute capability

3
Today Theory/practical course? Theory/practical course? CUDA programming model CUDA programming model –Limitations on number of threads –Grids of thread blocks

4
Today Theory/practical course? Theory/practical course? –The course is meant to be practical –Programming with CUDA –Is that a problem for some of you? –Should we change something?

5
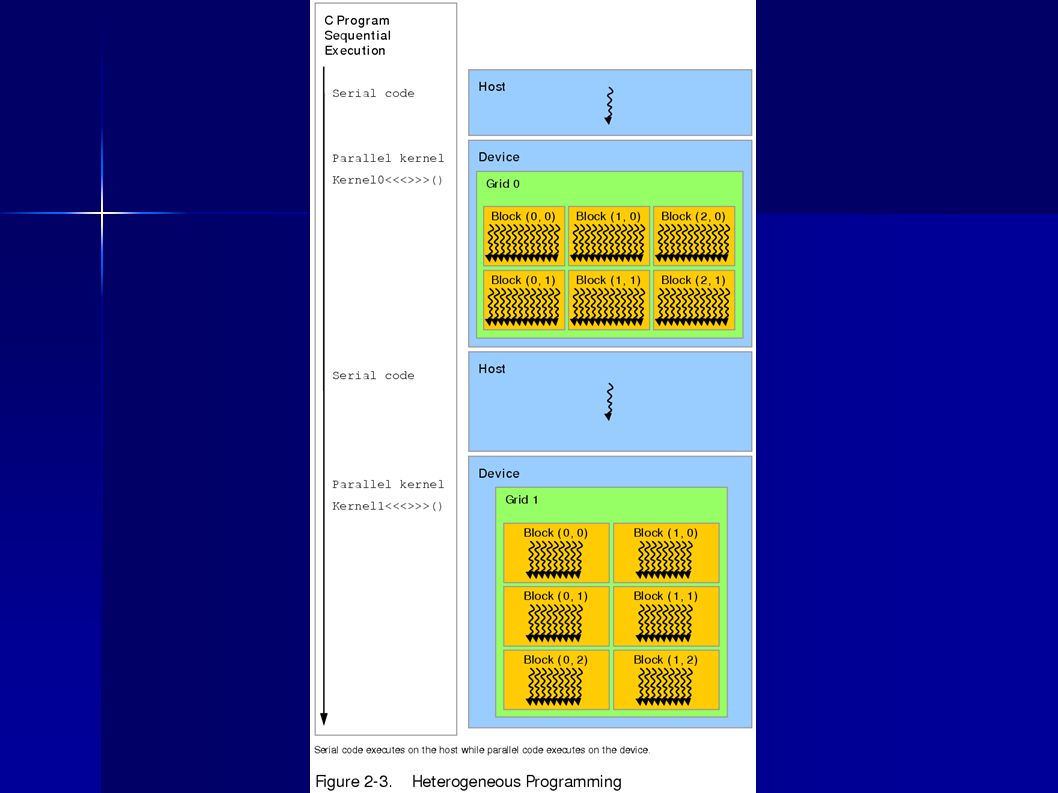
The CUDA Programming Model (cont'd)
")
6
Number of threads A kernel is executed on the device simultaneously by many threads dim3 blockSize(Dx,Dy,Dz); // for 1D block, Dy = 1 // for 2D block, Dz = 1 kernel >>(...) A kernel is executed on the device simultaneously by many threads dim3 blockSize(Dx,Dy,Dz); // for 1D block, Dy = 1 // for 2D block, Dz = 1 kernel >>(...) –# threads = blockSize = Dx*Dy*Dz
; // for 1D block, Dy = 1 // for 2D block, Dz = 1 kernel >>(...) A kernel is executed on the device simultaneously by many threads dim3 blockSize(Dx,Dy,Dz); // for 1D block, Dy = 1 // for 2D block, Dz = 1 kernel >>(...) –# threads = blockSize = Dx*Dy*Dz")
7
A bit about the hardware The GPU consists of several multiprocessors The GPU consists of several multiprocessors Each multiprocessor consists of several processors Each multiprocessor consists of several processors Each processor in a multiprocessor has its local memory in the form of registers Each processor in a multiprocessor has its local memory in the form of registers All processors in a multiprocessor have access to a shared memory All processors in a multiprocessor have access to a shared memory

9
Threads and processors All threads in a block run on the same multiprocessor. All threads in a block run on the same multiprocessor. –They might not all run at the same time –Therefore, threads should be independent of each other – __syncthreads() causes all threads to reach the same execution point before carrying on.
 causes all threads to reach the same execution point before carrying on..")
10
Threads and processors How many threads can run on a multiprocessor? How many threads can run on a multiprocessor? –how much memory the multiprocessor has –how much memory does each thread require

11
Threads and processors How many threads can a block have? How many threads can a block have? –how much memory the multiprocessor has –how much memory does each thread require

12
Grids of Blocks What if I want to run more threads? What if I want to run more threads? –Call multiple blocks of threads –These form a grid of blocks A grid can be 1D or 2D A grid can be 1D or 2D

13
Grids of Blocks Example of 1D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); kernel >> (...); Example of 1D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); kernel >> (...); Example of 2D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); dim3 gridDimension (N,N); kernel >> (...); Example of 2D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); dim3 gridDimension (N,N); kernel >> (...);
: int N; // assign some value to N dim3 blockDimension (N,N); kernel >> (...); Example of 1D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); kernel >> (...); Example of 2D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); dim3 gridDimension (N,N); kernel >> (...); Example of 2D grid Invoke (in main): int N; // assign some value to N dim3 blockDimension (N,N); dim3 gridDimension (N,N); kernel >> (...);")
14
Grids of Blocks Invoking a grid: kernel >> (...); Invoking a grid: kernel >> (...); – # threads = gridDimension* blockDimension
; Invoking a grid: kernel >> (...); – # threads = gridDimension* blockDimension")
17
Accessing block information Grids can be 1D or 2D Grids can be 1D or 2D The index of a block in a grid is available through the blockIdx variable The index of a block in a grid is available through the blockIdx variable The dimension of a block is available through the blockDim vairable The dimension of a block is available through the blockDim vairable

18
Arranging blocks Threads in a block should be independent of other threads in the block Threads in a block should be independent of other threads in the block Blocks in a grid should be independent of other blocks in the grid Blocks in a grid should be independent of other blocks in the grid

19
Memory available to threads Each thread has a local memory Each thread has a local memory Threads in a block share a shared memory Threads in a block share a shared memory All threads can access the global memory All threads can access the global memory

21
Memory available to threads All threads have read-only access to constant and texture memories All threads have read-only access to constant and texture memories

23
Memory available to threads An application is expected to manage An application is expected to manage –global, constant and texture memory spaces –Data transfer between host and device memories –(de)allocating host and device memory
allocating host and device memory")
24
Have a nice weekend See you next time

Similar presentations








 runs completely.>")






 is a manufacturer of graphics processor technologies that has begun to promote their.>")




. Code executed on GPU.>")


