Download presentation
Presentation is loading. Please wait.

1
Speed, Accurate and Efficient way to identify the DNA

2
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
3
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
4
Describing the genetic information for cell growth, division and functions. Diagnoses the case of an organism or a human, for example: - check if he has certain disease such as cancer or not. feature of the human body. -Such as ( height, eye color, the shape of the nose, hair, skin color, gender,……. ).
..")
5
Chromosomes Genes Nucleotide bases Adenine (A) Guanine (G) Cytosine (C) Thymine (T).
 Guanine (G) Cytosine (C) Thymine (T).")
6
Genes structure

7
FASTA format is a text-based format used to represent any type of sequences as DNA.

9
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
10
biological sequences develop from preexisting sequences instead of being invented by nature from the beginning. Three types of changes can occur at any given position within a sequence: –Point mutations. –Insertion. –Deletions. Two identical characters produces a match, Two different nonblank characters produces a mismatch, and a blank is called an indel (insertion/deletion) or gap.
 or gap..")
11
Global Sequence Alignment –Needleman-Wunsch Algorithm Local Sequence Alignment –Smith-Waterman Algorithm

12
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
13
The computational cost is very high, requiring a number of operations proportional to the product of the length of two sequences. The algorithm has a complexity of O(NxM) Previous solutions: –FPGA: High cost. Not suitable for all users –Approximated algorithms: Less accurate Current Solution: Parallelization on Graphics Cards.
 Previous solutions: –FPGA: High cost. Not suitable for all users –Approximated algorithms: Less accurate Current Solution: Parallelization on Graphics Cards..")
14
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
15
GPU ( Graphics Processing Unit) GPU is viewed as a compute device operating as a coprocessor to the main CPU (host). CPU and GPU are separate devices with separate memory.

16
CUDA Compute Unified Device Architecture CUDA is NVidia's scalable parallel programming model and a software environment for parallel computing. Language: CUDA C, minor extension to C/C++. A heterogeneous serial-parallel programming model.

17
CUDA CUDA program = serial code + parallel kernels (all in CUDA C). -Serial C code executes in a host thread (CPU thread). - Parallel kernel code executes in many device threads (GPU threads).
. - Parallel kernel code executes in many device threads (GPU threads)..")
18
CUDA ARCHITECTURE Blocks and grids may be 1d, 2d, or 3d. Blocks and grids may be 1d, 2d, or 3d. gridDim, blockIdx, blockDim, threadIdx. gridDim, blockIdx, blockDim, threadIdx. Threads/blocks have unique IDs. Threads/blocks have unique IDs.

19
CUDA Kernels A kernel is a function executed on the CUDA device. Threads are grouped into warps of 32 threads. -Warps are grouped into thread blocks. -Thread blocks are grouped into grids. Each kernel has access to certain variables that define its position. - threadIdx.x. - blockIdx.x. -gridDim.x, blockDim.x.

20
Kernel Call Syntax Kernels are called with the >> syntax. Function name >>(arg[1],arg[2],…). Where: Dg = dimensions of the grid (type dim3). Db = dimensions of the block (type dim3).
. Where: Dg = dimensions of the grid (type dim3). Db = dimensions of the block (type dim3)..")
21
Function Type Qualifiers The kernel was defined as __global__. This specifies that the function runs on the device and is callable from the host only. __device__ and __host__ are other available qualifiers. __device__ - executed on device, callable only from device. __host__ - default if not specified. Executed on host, callable from host only.

22
CUDA PROGARM ING Basic steps Transfer data from CPU to GPU. Explicitly call the GPU kernel designed - CUDA will implicitly assign threads to each multiprocessor and assign resources for computations. Transfer results back from GPU to CPU.

23
GPU ( Graphics Processing Unit) GPU is viewed as a compute device operating as a coprocessor to the main CPU (host). CPU and GPU are separate devices with separate memory.

24
CUDA Compute Unified Device Architecture CUDA is NVidia's scalable parallel programming model and a software environment for parallel computing. Language: CUDA C, minor extension to C/C++. A heterogeneous serial-parallel programming model.

25
CUDA CUDA program = serial code + parallel kernels (all in CUDA C). -Serial C code executes in a host thread (CPU thread). - Parallel kernel code executes in many device threads (GPU threads).
. - Parallel kernel code executes in many device threads (GPU threads)..")
26
CUDA ARCHITECTURE Blocks and grids may be 1d, 2d, or 3d.Blocks and grids may be 1d, 2d, or 3d. gridDim, blockIdx, blockDim, threadIdx.gridDim, blockIdx, blockDim, threadIdx. Each kernel has access to certain variables that define its position.Each kernel has access to certain variables that define its position. - threadIdx.x. - threadIdx.x. - blockIdx.x. - blockIdx.x. -gridDim.x, blockDim.x. -gridDim.x, blockDim.x.

27
CUDA Kernels A kernel is a function executed on the CUDA device. Threads are grouped into warps of 32 threads. -Warps are grouped into thread blocks. -Thread blocks are grouped into grids.

28
Kernel Call Syntax Kernels are called with the >> syntax. >>. Where: Dg = dimensions of the grid (type dim3). Db = dimensions of the block (type dim3).
. Db = dimensions of the block (type dim3)..")
29
Function Type Qualifiers The kernel was defined as __global__. This specifies that the function runs on the device and is callable from the host only. __device__ and __host__ are other available qualifiers. __device__ - executed on device, callable only from device. __host__ - default if not specified. Executed on host, callable from host only.

30
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
31
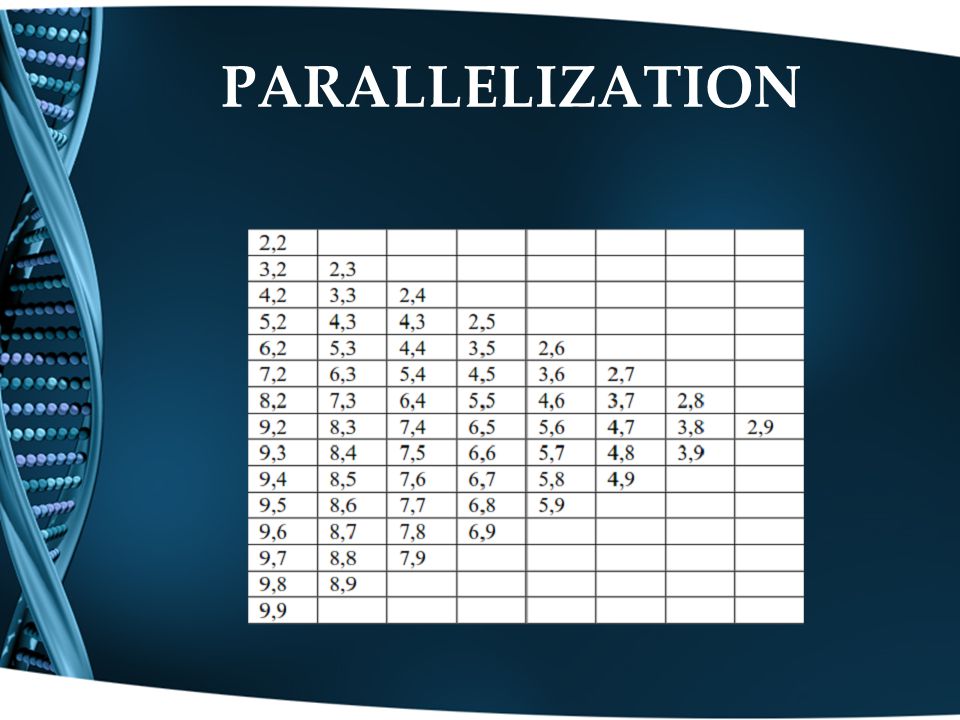
PARALLELIZATION The sequence alignment algorithm consumes large amount of time For processing. parallelization capabilities found in the GPUs. Parallelization=Performance Two levels of polarization level 1: Paralleling the Database comparison -- Assume 14 sequences in the database

32
PARALLELIZATION Parallelization inside single sequence comparing. 1. Initializing the data matrix and pointers

33
PARALLELIZATION

34
data dependency in the calculation steps d PARALLELIZATION

36
Implementation of this paralleling part

37
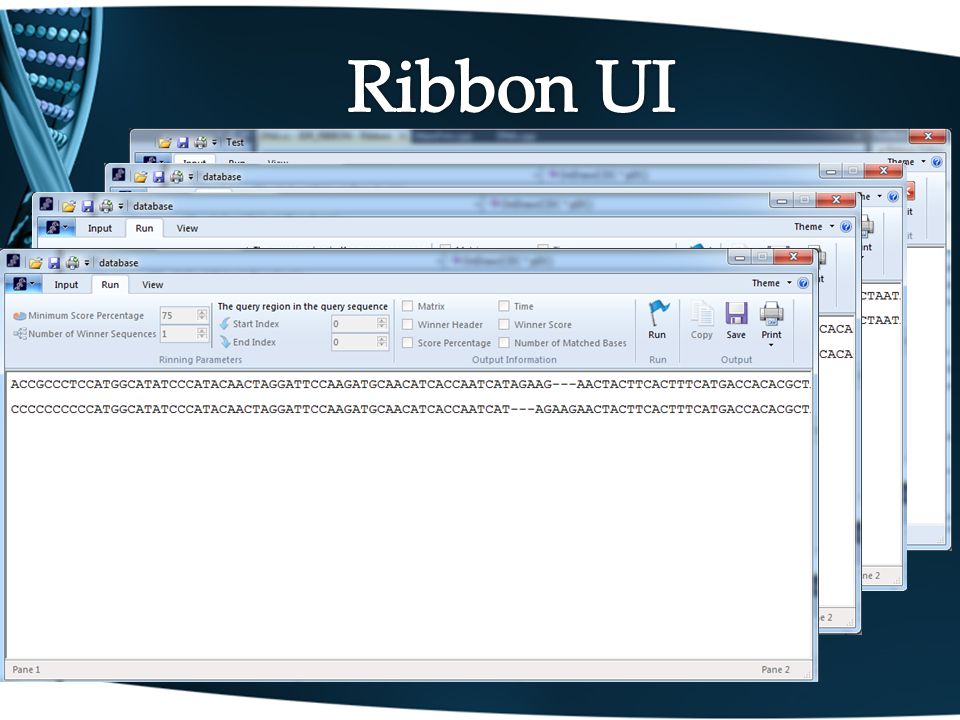
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
39
DNA Overview. Sequence Alignment. Problem & Previous Solutions. GPU & CUDA. Implemented Solution. GUI (Ribbon). Results.
. Results..")
40
Performance

42
Speed Up

44
Any Questions ??

Similar presentations
















 Lecture 18: Application-Driven Hardware Acceleration (4/4)>")





