Download presentation
Presentation is loading. Please wait.

1
Feature Subset Selection using Minimum Cost Spanning Trees Mike Farah - 18548059 Supervisor: Dr. Sid Ray

2
Outline Introduction Pattern Recognition Feature subset selection Current methods Proposed method IFS Results Conclusion

3
Introduction: Pattern Recognition The classification of objects into groups by learning from a small sample of objects Apples and strawberries: Classes: apples and strawberries Features: colour, size, weight, texture Applications: Character recognition Voice recognition Oil mining Weather prediction …

4
Introduction: Pattern Recognition Pattern representation Measuring and recording features Size, colour, weight, texture…. Feature set reduction Reducing the number of features used Selecting a subset Transformations Classification The resulting features are used for classification of unknown objects

5
Introduction: Feature subset selection Can be split into two processes: Feature subset searching Not usually feasible to exhaustively try all feature subset combinations Criterion function Main issue of feature subset selection (Jain et al. 2000) Focus of our research
 Focus of our research.")
6
Current methods Euclidean distance Statistical properties of the classes are not considered Mahalanobis distance Variances and co-variances of the classes are taken into account

7
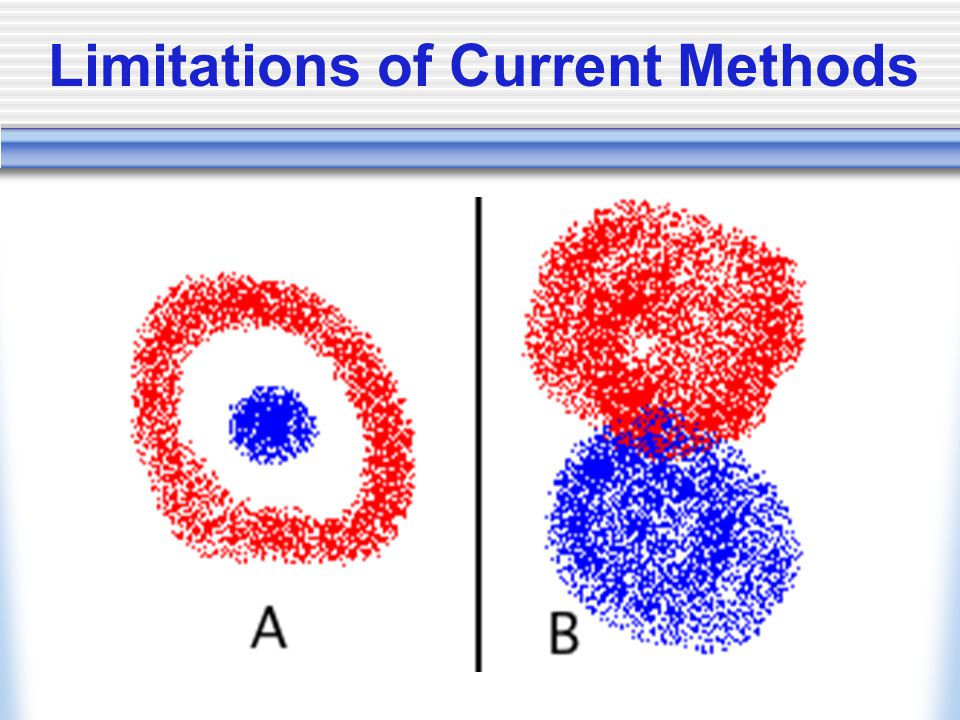
Limitations of Current Methods

9
Friedman and Rafsky’s two sample test Minimum spanning tree approach for determining whether two sets of data originate from the same source A MST is built across the data from two sources, edges which connect samples of different data sets are removed If many edges are removed, then the two sets of data are likely to originate from the same source

10
Friedman and Rafsky’s two sample test Method can be used as a criterion function MST built across the sample points Edges which connect samples of different classes are removed A good subset is one that provides discriminatory information about the classes, therefore the fewer edges removed the better

11
Limitations of Friedman and Rafsky’s technique

12
Our Proposed Method Use the number of edges and edge lengths in determining the suitability of a subset A good subset will have a large number of short edges connecting samples of the same class And a small number of long edges connecting samples of different classes

13
Our Proposed Method We experimented with using average edge length and weighted average - weighted average was expected to perform better

14
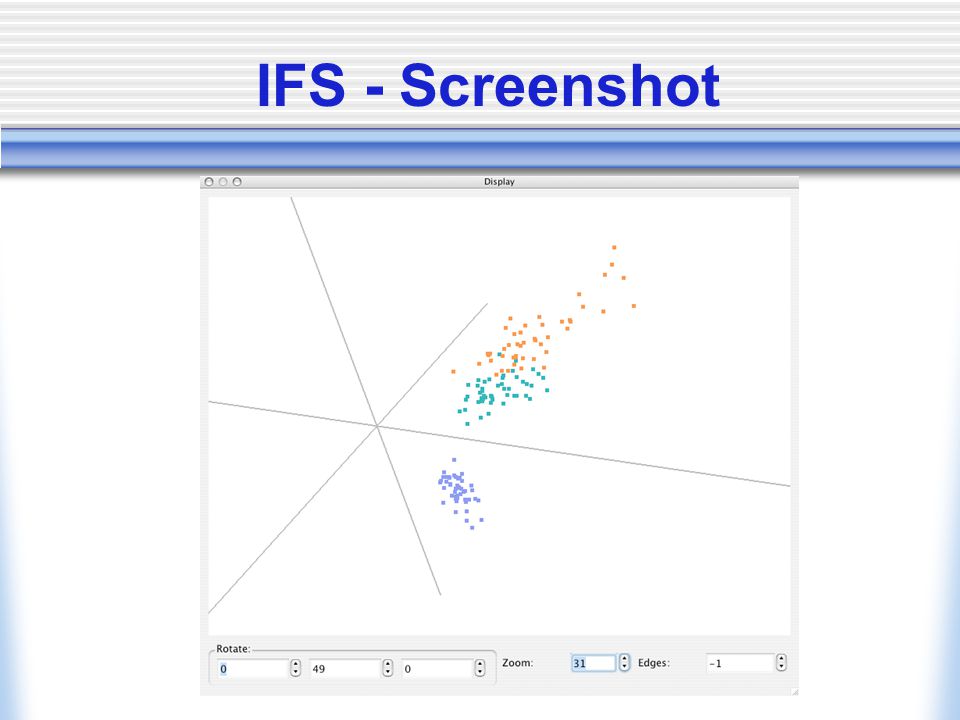
IFS - Interactive Feature Selector Developed to allow users to experiment with various feature selection methods Automates the execution of experiments Allows visualisation of data sets, and results Extensible, developers can add criterion functions, feature selectors and classifiers easily into the system

15
IFS - Screenshot

17
Experimental Framework Data setNo. SamplesNo. FeatsNo. Classes Iris15043 Crab20072 Forensic Glass21497 Diabetes33282 Character757208 Synthetic75075

18
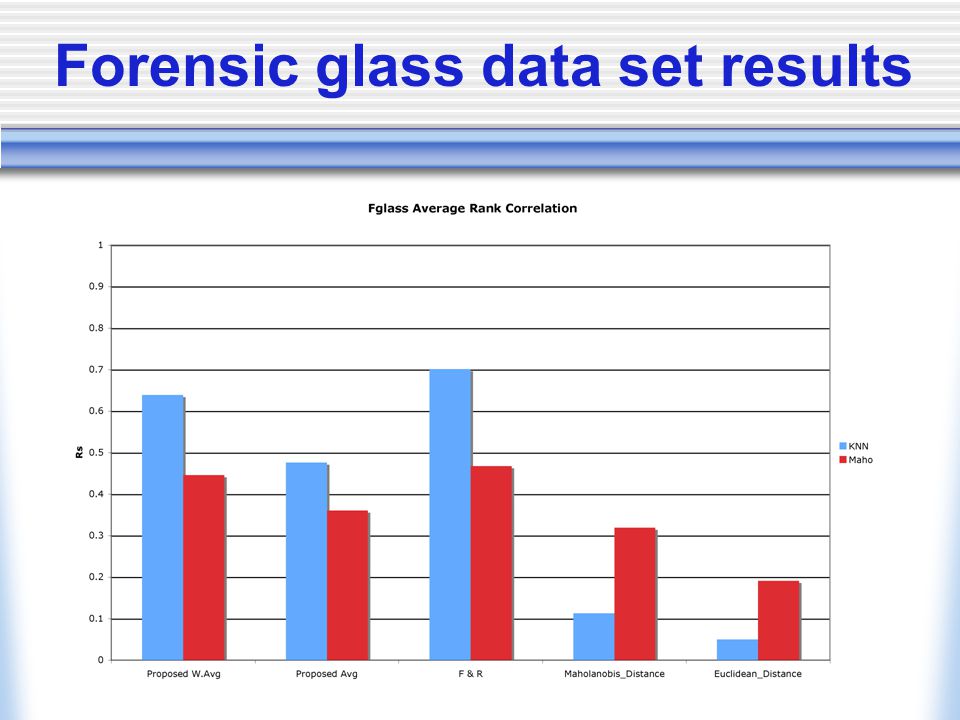
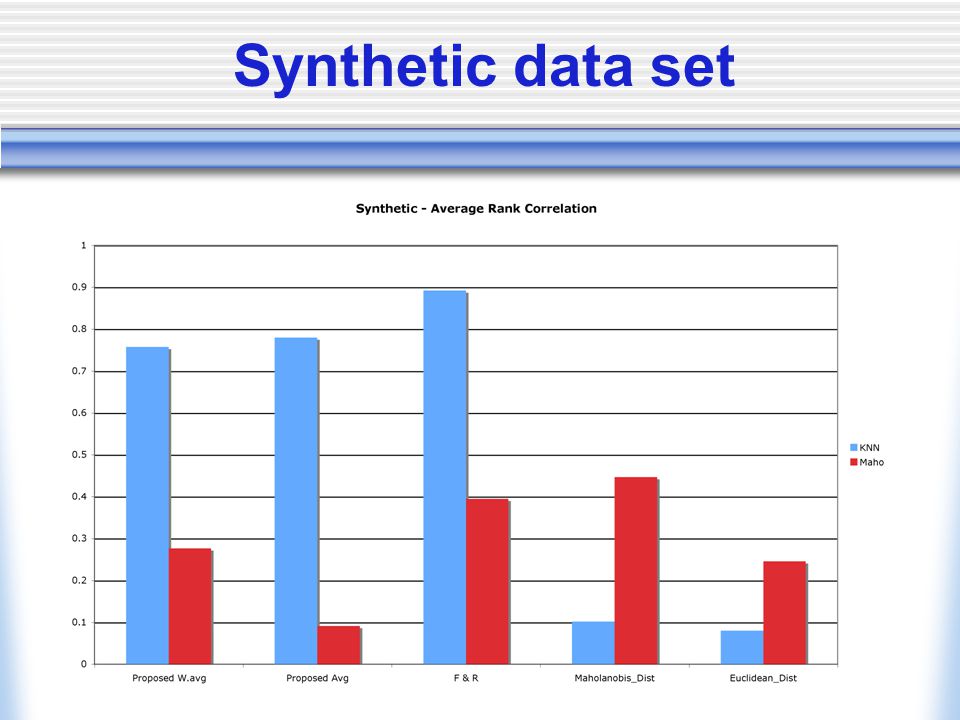
Experimental Framework Spearman’s rank correlation A good criterion function will have good correlation with the classifier, subsets which are ranked high should achieve high accuracy levels Subset chosen Final subsets selected by criterion functions are compared to the optimal subset chosen by the classifier Time

19
Forensic glass data set results

21
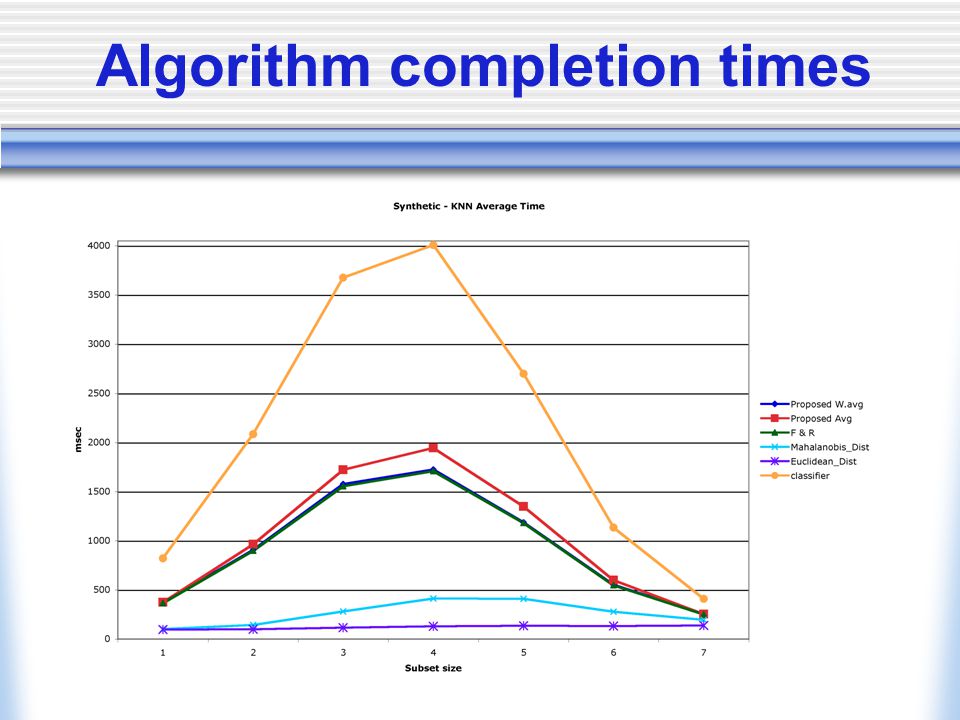
Synthetic data set

23
Algorithm completion times

25
Algorithm complexities K-NN MST criterion functions Mahalanobis distance Euclidean distance

26
Conclusion MST based approaches generally achieved higher accuracy values and rank correlation - in particular with the K-NN classifier Criterion function based on Friedman and Rafsky’s two sample test performed the best

27
Conclusion MST approaches are closely related with the KNN classifier Mahalanobis criterion function suited to data sets with Gaussian distributions and strong feature interdependence Future work: Construct a classifier based on KNN, which gives closer neighbours higher priority Improve IFS

Similar presentations





>")
 divide-and-conquer technique for Minimum Spanning Tree problem Step 1: Divide the graph into N sub-graph by clustering. Step 2: Solve each.>")



 for Clustering Gene Expression Data K. Y. Yeung and W. L. Ruzzo.>")


, I. Grinias (2) and G. Tziritas (3) 07-07-2009.>")





