Download presentation
Presentation is loading. Please wait.

1
Stat 112: Lecture 14 Notes Finish Chapter 6:
Checking and Remedying Constant Variance Assumption (Section 6.5) Checking and Remedying Normality Assumption (Seciton 6.6) Outliers and Influential Points (Section 6.7) Homework 4 is due next Thursday. Please let me know of any ideas you want to discuss for the final project.
 Checking and Remedying Normality Assumption (Seciton 6.6) Outliers and Influential Points (Section 6.7) Homework 4 is due next Thursday. Please let me know of any ideas you want to discuss for the final project.")
2
Assumptions of Multiple Linear Regression Model
Linearity: Constant variance: The standard deviation of Y for the subpopulation of units with is the same for all subpopulations. Normality: The distribution of Y for the subpopulation of units with is normally distributed for all subpopulations. The observations are independent.

3
Checking Constant Variance Assumption
Residual plot versus explanatory variables should exhibit constant variance. Residual plot versus predicted values should exhibit constant variance (this plot is often most useful for detecting nonconstant variance)
")
4
The spread increases with y
Heteroscedasticity When the requirement of a constant variance is violated we have a condition of heteroscedasticity. Diagnose heteroscedasticity by plotting the residual against the predicted y. + ^ y Residual + + + + + + + + + + + + + + ^ + + + y + + + + + + + + + The spread increases with y ^

5
How much traffic would a building generate?
The goal is to predict how much traffic will be generated by a proposed new building of 150,000 occupied sq ft. (Data is from the MidAtlantic States City Planning Manual.) The data tells how many automobile trips per day were made in the AM to office buildings of different sizes. The variables are x = “Occupied Sq Ft of floor space in the building (in 1000 sq ft)” and Y = “number of automobile trips arriving at the building per day in the morning”.
 The data tells how many automobile trips per day were made in the AM to office buildings of different sizes. The variables are x = Occupied Sq Ft of floor space in the building (in 1000 sq ft) and. Y = number of automobile trips arriving at the building per day in the morning .")
6
The heteroscedasticity shows here.

7
Reducing Nonconstant Variance/Nonnormality by Transformations
A brief list of transformations y’ = y1/2 (for y > 0) Use when the spread of residuals increases with y’ = log y (for y > 0) Use when the distribution of the residuals is skewed to the right. y’ = y2 Use when the spread of residuals is decreasing with , Use when the error distribution is left skewed
 Use when the spread of residuals increases with. y’ = log y (for y > 0) Use when the distribution of the residuals is skewed to the right. y’ = y2. Use when the spread of residuals is decreasing with , Use when the error distribution is left skewed.")
8
To try to fix heteroscedasticity we transform Y to Log(Y)
This fixes heteroskedasticity BUT it creates a nonlinear pattern.

9
To fix nonlinearity we now transform x to Log(x), without changing the Y axis anymore.
The resulting pattern is both satisfactorily homoscedastic AND linear.

10
Often we will plot residuals versus predicted.
For simple regression the two residual plots are equivalent

11
Checking Normality If the disturbances are normally distributed, about 68% of the standardized residuals should be between –1 and +1, 95% should be between –2 and +2 and 99% should be between –3 and +3. Standardized residual for observation i= Graphical methods for checking normality: Histogram of (standardized) residuals, normal quantile plot of (standardized) residuals.
 residuals, normal quantile plot of (standardized) residuals.")
12
Normal Quantile Plots Normal quantile (probability) plot: Scatterplot involving ordered residuals (values) with the x-axis giving the expected value of the kth ordered residual on the standard normal scale (residual / ) and the y-axis giving the actual residual. JMP implementation: Save residuals, then click Analyze, Distribution, red triangle next to Residuals and Normal Quantile Plot. If the residuals follow approximately a normal distribution, they should fall approximately on a straight line.
 plot: Scatterplot involving ordered residuals (values) with the x-axis giving the expected value of the kth ordered residual on the standard normal scale (residual / ) and the y-axis giving the actual residual. JMP implementation: Save residuals, then click Analyze, Distribution, red triangle next to Residuals and Normal Quantile Plot. If the residuals follow approximately a normal distribution, they should fall approximately on a straight line.")
13
Traffic and office space ex. Cont.

14
Residuals from the final Log – Log fit

15
Importance of Normality and Corrections for Normality
For point estimation/confidence intervals/tests of coefficients and confidence intervals for mean response, normality of residuals is only important for small samples because of Central Limit Theorem. Guideline: Do not need to worry about normality if there are 30 observations plus 10 additional observations for each additional explanatory variable in multiple regression beyond the first one. For prediction intervals, normality is critical for all sample sizes. Corrections for normality: transformations of y variable (see earlier slide)
")
16
Order of Correction of Violations of Assumptions in Multiple Regression
First, focus on correcting a violation of the linearity assumption. Then, focus on correction violations of constant variance after the linearity assumption is satifised. If constant variance is achieved, make sure that linearity still holds approximately. Then, focus on correctiong violations of normality. If normality is achieved, make sure that linearity and constant variance still approximately hold.

17
Outliers and Influential Observations in Simple Regression
Outlier: Any really unusual observation. Outlier in the X direction (called high leverage point): Has the potential to influence the regression line. Outlier in the direction of the scatterplot: An observation that deviates from the overall pattern of relationship between Y and X. Typically has a residual that is large in absolute value. Influential observation: Point that if it is removed would markedly change the statistical analysis. For simple linear regression, points that are outliers in the x direction are often influential.
: Has the potential to influence the regression line. Outlier in the direction of the scatterplot: An observation that deviates from the overall pattern of relationship between Y and X. Typically has a residual that is large in absolute value. Influential observation: Point that if it is removed would markedly change the statistical analysis. For simple linear regression, points that are outliers in the x direction are often influential.")
18
Outliers in Direction of Scatterplot
Residual Standardized Residual: Under multiple regression model, about 5% of the points should have standardized residuals greater in absolute value than 2, 1% of the points should have standardized residuals greater in absolute value than 3. Any point with standardized residual greater in absolute value than 3 should be examined. To compute standardized residuals in JMP, right click in a new column, click Formula and create a formula with the residual divided by the RMSE.

19
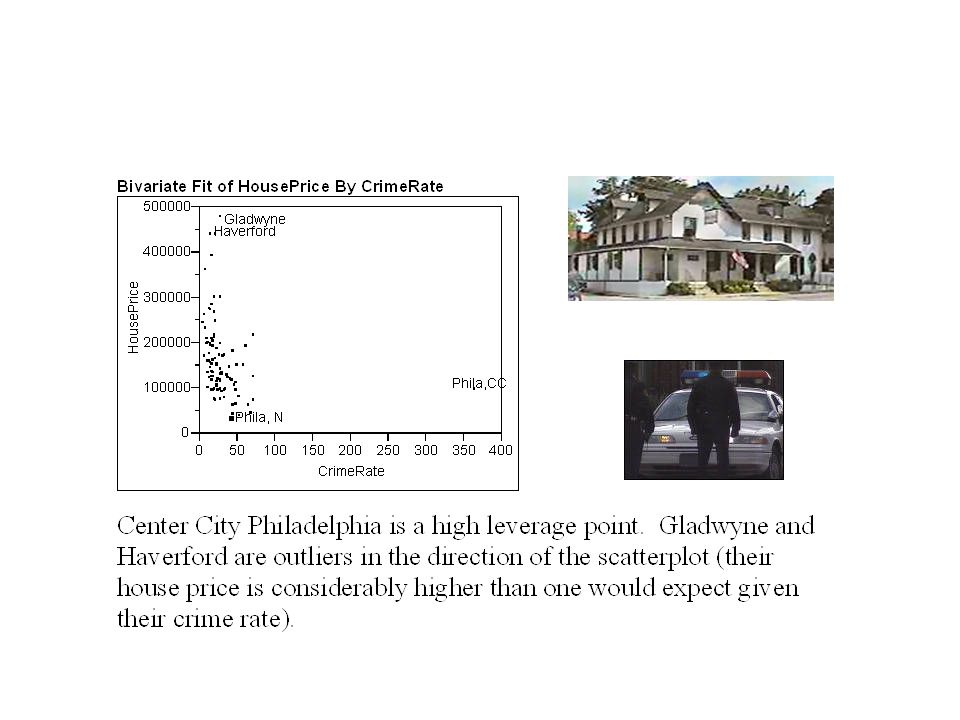
Housing Prices and Crime Rates
A community in the Philadelphia area is interested in how crime rates are associated with property values. If low crime rates increase property values, the community might be able to cover the costs of increased police protection by gains in tax revenues from higher property values. The town council looked at a recent issue of Philadelphia Magazine (April 1996) and found data for itself and 109 other communities in Pennsylvania near Philadelphia. Data is in philacrimerate.JMP. House price = Average house price for sales during most recent year, Crime Rate=Rate of crimes per 1000 population.
 and found data for itself and 109 other communities in Pennsylvania near Philadelphia. Data is in philacrimerate.JMP. House price = Average house price for sales during most recent year, Crime Rate=Rate of crimes per 1000 population.")
21
Which points are influential?
Center City Philadelphia is influential; Gladwyne is not. In general, points that have high leverage are more likely to be influential.

22
Excluding Observations from Analysis in JMP
To exclude an observation from the regression analysis in JMP, go to the row of the observation, click Rows and then click Exclude/Unexclude. A red circle with a diagonal line through it should appear next to the observation. To put the observation back into the analysis, go to the row of the observation, click Rows and then click Exclude/Unexclude. The red circle should no longer appear next to the observation.

23
Formal measures of leverage and influence
Leverage: “Hat values” (JMP calls them hats) Influence: Cook’s Distance (JMP calls them Cook’s D Influence). To obtain them in JMP, click Analyze, Fit Model, put Y variable in Y and X variable in Model Effects box. Click Run Model box. After model is fit, click red triangle next to Response. Click Save Columns and then Click Hats for Leverages and Click Cook’s D Influences for Cook’s Distances. To sort observations in terms of Cook’s Distance or Leverage, click Tables, Sort and then put variable you want to sort by in By box.
 Influence: Cook’s Distance (JMP calls them Cook’s D Influence). To obtain them in JMP, click Analyze, Fit Model, put Y variable in Y and X variable in Model Effects box. Click Run Model box. After model is fit, click red triangle next to Response. Click Save Columns and then Click Hats for Leverages and Click Cook’s D Influences for Cook’s Distances. To sort observations in terms of Cook’s Distance or Leverage, click Tables, Sort and then put variable you want to sort by in By box.")
24
Center City Philadelphia has both influence (Cook’s Distance much
Greater than 1 and high leverage (hat value > 3*2/99=0.06). No other observations have high influence or high leverage.
. No other. observations have high influence or high leverage.")
25
Rules of Thumb for High Leverage and High Influence
High Leverage Any observation with a leverage (hat value) > (3 * # of coefficients in regression model)/n has high leverage, where # of coefficients in regression model = 2 for simple linear regression. n=number of observations. High Influence: Any observation with a Cook’s Distance greater than 1 indicates a high influence.
 > (3 * # of coefficients in regression model)/n has high leverage, where. # of coefficients in regression model = 2 for simple linear regression. n=number of observations. High Influence: Any observation with a Cook’s Distance greater than 1 indicates a high influence.")
26
What to Do About Suspected Influential Observations?
See flowchart attached to end of slides Does removing the observation change the substantive conclusions? If not, can say something like “Observation x has high influence relative to all other observations but we tried refitting the regression without Observation x and our main conclusions didn’t change.”

27
If removing the observation does change substantive conclusions, is there any reason to believe the observation belongs to a population other than the one under investigation? If yes, omit the observation and proceed. If no, does the observation have high leverage (outlier in explanatory variable). If yes, omit the observation and proceed. Report that conclusions only apply to a limited range of the explanatory variable. If no, not much can be said. More data (or clarification of the influential observation) are needed to resolve the questions.
. If yes, omit the observation and proceed. Report that conclusions only apply to a limited range of the explanatory variable. If no, not much can be said. More data (or clarification of the influential observation) are needed to resolve the questions.")
28
General Principles for Dealing with Influential Observations
General principle: Delete observations from the analysis sparingly – only when there is good cause (observation does not belong to population being investigated or is a point with high leverage). If you do delete observations from the analysis, you should state clearly which observations were deleted and why.
. If you do delete observations from the analysis, you should state clearly which observations were deleted and why.")
Similar presentations
 Inferences from multiple regression analysis.>")



 –Outliers and Influential Points (Section 6.7) Homework.>")

 Bani K. Mallick1 STAT 651 Lecture #18.>")

>")



 Review>")

 R-squared statistic (10.4.1) Residual plots (11.2) Influential observations (11.3, 11.4.3.>")
>")

>")

