Download presentation
Presentation is loading. Please wait.

1
Biological networks: Types and origin Protein-protein interactions, complexes, and network properties Thomas Skøt Jensen Center for Biological Sequence Analysis The Technical University of Denmark

2
Networks in electronics Radio kindly provided by Lazebnik, Cancer Cell, 2002

3
Model Generation Interactions Radio kindly provided by Lazebnik, Cancer Cell, 2002 Parts List YER001W YBR088C YOL007C YPL127C YNR009W YDR224C YDL003W YBL003C … YDR097C YBR089W YBR054W YMR215W YBR071W YBL002W YNL283C YGR152C … Sequencing Gene knock-out Microarrays etc. Interactions Genetic interactions Protein-Protein interactions Protein-DNA interactions Subcellular Localization Dynamics Microarrays Proteomics Metabolomics

4
Types of networks

5
Interaction networks in molecular biology Protein-protein interactions Protein-DNA interactions Genetic interactions Metabolic reactions Co-expression interactions Text mining interactions Association networks

6
Interaction networks in molecular biology Protein-protein interactions Protein-DNA interactions Genetic interactions Metabolic reactions Co-expression interactions Text mining interactions Association networks

7
Characterization of physical interactions Obligation –obligate (protomers only found/function together) –non-obligate (protomers can exist/function alone) Time of interaction –permanent (complexes, often obligate) –strong transient (require trigger, e.g. G proteins) –weak transient (dynamic equilibrium)
 –weak transient (dynamic equilibrium).")
8
ol Examples: GPCR obligate, permanent non-obligate, strong transient

9
Approaches by interaction type Physical Interactions –Yeast two hybrid screens –Affinity purification (mass spec) –Protein-DNA by chIP-chip Other measures of ‘association’ –Genetic interactions (double deletion mutants) –Functional associations (STRING) –Co-expression
 –Protein-DNA by chIP-chip Other measures of ‘association’ –Genetic interactions (double deletion mutants) –Functional associations (STRING) –Co-expression")
10
Yeast two-hybrid method Y2H assays interactions in vivo. Uses property that transcription factors generally have separable transcriptional activation (AD) and DNA binding (DBD) domains. A functional transcription factor can be created if a separately expressed AD can be made to interact with a DBD. A protein ‘bait’ B is fused to a DBD and screened against a library of protein “preys”, each fused to a AD.
 and DNA binding (DBD) domains. A functional transcription factor can be created if a separately expressed AD can be made to interact with a DBD. A protein ‘bait’ B is fused to a DBD and screened against a library of protein preys , each fused to a AD..")
11
Yeast two-hybrid method Fields and Song

12
Issues with Y2H Strengths –High sensitivity (transient & permanent PPIs) –Takes place in vivo –Independent of endogenous expression Weaknesses: False positive interactions –Auto-activation –‘sticky’ prey –Detects “possible interactions” that may not take place under real physiological conditions –May identify indirect interactions (A-C-B) Weaknesses: False negatives interactions –Similar studies often reveal very different sets of interacting proteins (i.e. False negatives) –May miss PPIs that require other factors to be present (e.g. ligands, proteins, PTMs)
 –May miss PPIs that require other factors to be present (e.g. ligands, proteins, PTMs).")
13
Protein interactions by immuno-precipitation followed by mass spectrometry Start with affinity purification of a single epitope- tagged protein This enriched sample typically has a low enough complexity to be fractionated on a standard polyacrylamide gel Individual bands can be excised from the gel and identified with mass spectrometry.

14
Affinity Purification

15
Strengths High specificity Well suited for detecting permanent or strong transient interactions (complexes) Detects real, physiologically relevant PPIs Weaknesses Less suited for detecting weaker transient interactions (low sensitivity) May miss complexes not present under the given experimental conditions (low sensitivity) May identify indirect interactions (A-C-B)
 Detects real, physiologically relevant PPIs Weaknesses Less suited for detecting weaker transient interactions (low sensitivity) May miss complexes not present under the given experimental conditions (low sensitivity) May identify indirect interactions (A-C-B)")
16
Protein-protein interaction data growth Error rate may be as high as 30-50 %

17
Topology based scoring of interactions Low confidence (4 unshared interaction partners) High confidence (1 unshared interaction partners) ABC Yeast two-hybrid Low confidence (rarely purified together) High confidence (often purified together) Complex pull-downs D de Lichtenberg et al., Science, 2005
 High confidence (1 unshared interaction partners) ABC Yeast two-hybrid Low confidence (rarely purified together) High confidence (often purified together) Complex pull-downs D de Lichtenberg et al., Science, 2005")
18
Filtering by subcellular localization de Lichtenberg et al., Science, 2005

19
Reducing the error rate in PPI data Benchmark by measuring the overlap between the curated MIPS complexes and different PPI data sets derived from high-throughput screens. Overlap with curated MIPS complexesEstimated error rate de Lichtenberg et al., Science, 2005

20
Filtering reduces coverage and increases specificity

21
Network Properties Graphs, paths, topology

22
Graphs Graph G=(V,E) is a set of vertices V and edges E A subgraph G’ of G is induced by some V’ V and E’ E Graph properties: –Connectivity (node degree, paths) –Cyclic vs. acyclic –Directed vs. undirected

23
Sparse vs Dense G(V, E) where |V|=n, |E|=m the number of vertices and edges Graph is sparse if m~n Graph is dense if m~n 2 Complete graph when m=n 2
 where |V|=n, |E|=m the number of vertices and edges Graph is sparse if m~n Graph is dense if m~n 2 Complete graph when m=n 2")
24
Connected Components G(V,E) |V| = 69 |E| = 71
 |V| = 69 |E| = 71")
25
Connected Components G(V,E) |V| = 69 |E| = 71 6 connected components
 |V| = 69 |E| = 71 6 connected components")
26
Paths A path is a sequence {x 1, x 2,…, x n } such that (x 1,x 2 ), (x 2,x 3 ), …, (x n-1,x n ) are edges of the graph. A closed path x n =x 1 on a graph is called a graph cycle or circuit.

27
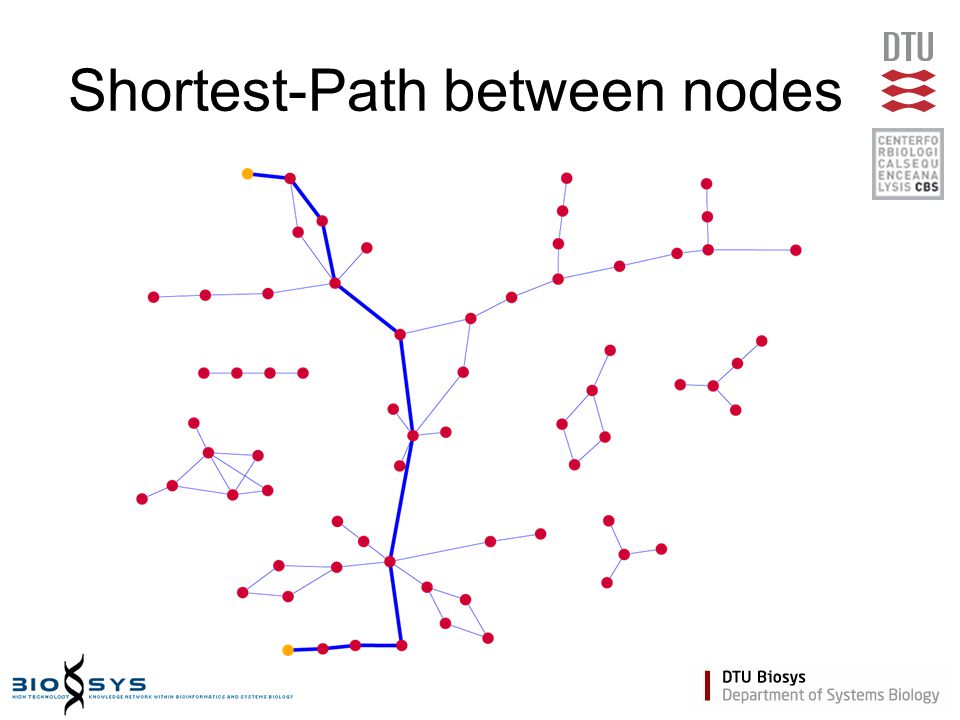
Shortest-Path between nodes

29
Longest Shortest-Path

30
Degree or connectivity

31
Random vs scale-free networks P(k) is probability of each degree k, i.e fraction of nodes having that degree. For random networks, P(k) is normally distributed. For real networks the distribution is often a power- law: P(k) ~ k Such networks are said to be scale-free
 is normally distributed. For real networks the distribution is often a power- law: P(k) ~ k Such networks are said to be scale-free.")
32
“The Swedish sex web” Target the ‘hubs’ to have an efficient safe sex education campaign Lewin Bo, et al., Sex i Sverige; Om sexuallivet i Sverige 1996, Folkhälsoinstitutet, 1998

33
Knock-out lethality and connectivity

34
Clustering coefficient k: neighbors of I n I : edges between node I’s neighbors The density of the network surrounding node I, characterized as the number of triangles through I. Related to network modularity The center node has 8 (grey) neighbors There are 4 edges between the neighbors C = 2*4 /(8*(8-1)) = 8/56 = 1/7
 neighbors There are 4 edges between the neighbors C = 2*4 /(8*(8-1)) = 8/56 = 1/7.")
35
Protein complexes have a high clustering coefficient Proteins subunits are highly interconnected and thus have a high clustering coefficient There exists algorithms, such as MCODE, for identifying subnetworks (complexes) in large protein-protein interaction networks
 in large protein-protein interaction networks")
36
Hierarchical Networks

37
Detecting hierarchical organization

38
Scale-free networks are robust Complex systems (cell, internet, social networks), are resilient to component failure Network topology plays an important role in this robustness –Even if ~80% of nodes fail, the remaining ~20% still maintain network connectivity Attack vulnerability if hubs are selectively targeted In yeast, only ~20% of proteins are lethal when deleted, and are 5 times more likely to have degree k>15 than k<5.
, are resilient to component failure Network topology plays an important role in this robustness –Even if ~80% of nodes fail, the remaining ~20% still maintain network connectivity Attack vulnerability if hubs are selectively targeted In yeast, only ~20% of proteins are lethal when deleted, and are 5 times more likely to have degree k>15 than k<5.")
39
Other interesting features Cellular networks are assortative, hubs tend not to interact directly with other hubs. Hubs tend to be “older” proteins (so far claimed for protein-protein interaction networks only) Hubs also seem to have more evolutionary pressure—their protein sequences are more conserved than average between species (shown in yeast vs. worm)
 Hubs also seem to have more evolutionary pressure—their protein sequences are more conserved than average between species (shown in yeast vs. worm).")
41
Sub-cellular localization coverage

42
Co-localization of interacting proteins

43
Tendency to interact with your cousin

44
Over-representation of highly abundant proteins

45
Coverage versus Accuracy say a lot, of which most is wrong say a lot, of which most is right say little, of which most is wrong say little, of which most is right Specificity Sensitivity

Similar presentations








 genes at once. Can answer questions.>")











