Download presentation
Presentation is loading. Please wait.

1
Nonlinear Dimension Reduction Presenter: Xingwei Yang The powerpoint is organized from: 1.Ronald R. Coifman et al. (Yale University) 2. Jieping Ye, (Arizona State University)
 2. Jieping Ye, (Arizona State University).")
2
Motivation Linear projections will not detect the pattern.

3
Nonlinear PCA using Kernels Traditional PCA applies linear transformation May not be effective for nonlinear data Solution: apply nonlinear transformation to potentially very high- dimensional space. Computational efficiency: apply the kernel trick. Require PCA can be rewritten in terms of dot product. More on kernels later

4
Nonlinear PCA using Kernels Rewrite PCA in terms of dot product The covariance matrix S can be written as Let v be The eigenvector of S corresponding to nonzero eigenvalue Eigenvectors of S lie in the space spanned by all data points.

5
Nonlinear PCA using Kernels The covariance matrix can be written in matrix form: Any benefits?

6
Nonlinear PCA using Kernels Next consider the feature space: The (i,j)-th entry of is Apply the kernel trick: K is called the kernel matrix.
-th entry of is Apply the kernel trick: K is called the kernel matrix.")
7
Nonlinear PCA using Kernels Projection of a test point x onto v: Explicit mapping is not required here.

8
Diffusion distance and Diffusion map A symmetric matrix M s can be derived from M as M and M s has same N eigenvalues, Under random walk representation of the graph M : left eigenvector of M : right eigenvector of M : time step 8/14

9
If one starts random walk from location x i, the probability of landing in location y after r time steps is given by For large , all points in the graph are connected (M i,j >0) and the eigenvalues of M Diffusion distance and Diffusion map has the dual representation (time step and kernel width). where e i is a row vector with all zeros except that i th position = 1.

10
Diffusion distance and Diffusion map One can show that regardless of starting point x i Left eigenvector of M with eigenvalue 0 =1 with Eigenvector 0 ( x ) has the dual representation : 1. Stationary probability distribution on the curve, i.e., the probability of landing at location x after taking infinite steps of random walk (independent of the start location). 2. It is the density estimate at location x.
. 2. It is the density estimate at location x..")
11
Diffusion distance For any finite time r, k and k are the right and left eigenvectors of graph Laplacian M. is the k th eigenvalue of M r (arranged in descending order). Given the definition of random walk, we denote Diffusion distance as a distance measure at time t between two pmfs as with empirical choice w(y)=1/ 0 (y).
. Given the definition of random walk, we denote Diffusion distance as a distance measure at time t between two pmfs as with empirical choice w(y)=1/ 0 (y)..")
12
Diffusion Map Diffusion distance : Diffusion map : Mapping between original space and first k eigenvectors as Relationship : This relationship justifies using Euclidean distance in diffusion map space for spectral clustering. Since, it is justified to stop at appropriate k with a negligible error of order O( k+1 / k ) t ).
 t )..")
13
Example: Hourglass

14
Example: Image imbedding

15
Example: Lip image

16
Shape description

17
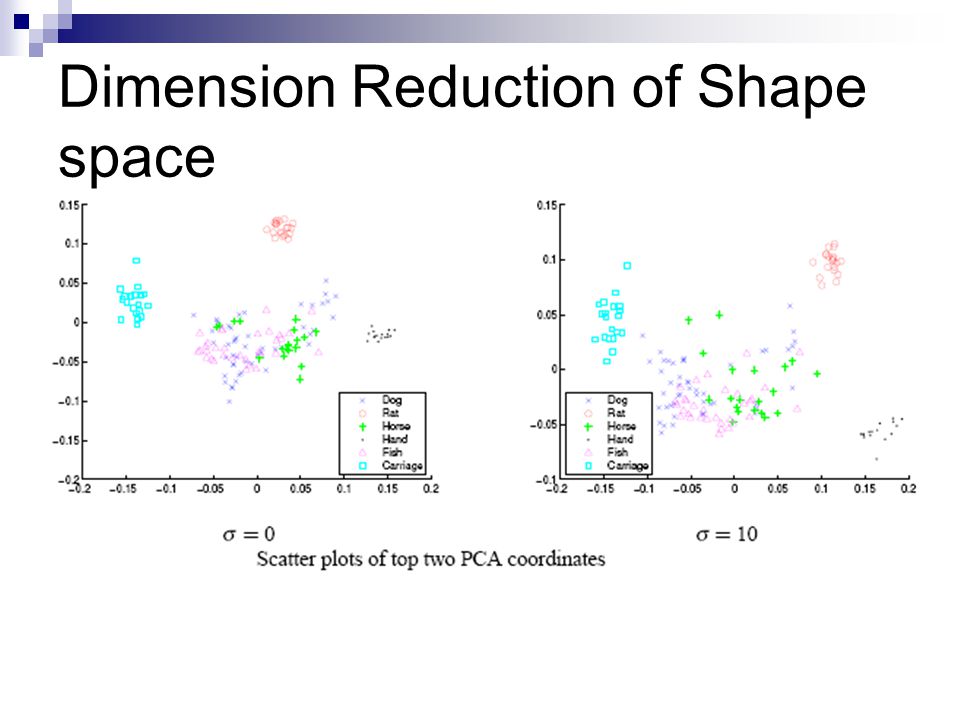
Dimension Reduction of Shape space

20
References Unsupervised Learning of Shape Manifolds (BMVC 2007) Diffusion Maps(Appl. Comput. Harmon. Anal. 21 (2006)) Geometric diffusions for the analysis of data from sensor networks (Current Opinion in Neurobiology 2005)
) Geometric diffusions for the analysis of data from sensor networks (Current Opinion in Neurobiology 2005).")
Similar presentations


>")

 Book: There will be class-notes/slides. Homework: reading material, some exercises, some MATLAB implementations.>")















