Download presentation
Presentation is loading. Please wait.

1
CHAPTER 2 Building Empirical Model

2
Basic Statistical Concepts Consider this situation: The tension bond strength of portland cement mortar is an important characteristics of the product. An engineer is interested in comparing the strength of a modified formulation in which polymer latex emulsion have been added during mixing to the strength of unmodified mortar. The experimenter has collected observations on the strength, 10 each for both mortars. The data are shown in Table 2.1

3
Each observations,j is called a run Fluctuation (noise) – experimental error Presence of error implies that response variable is a random variable (can be discreate or continuous)
 – experimental error Presence of error implies that response variable is a random variable (can be discreate or continuous)")
4
Dot diagram for data in Table 2.1 What can you conclude from the dot diagram? Where is the general location or central tendency?

5
Other graphical methods… Histogram For fairly numerous data

6
Other graphical methods… Box plot (or box and whisker plot) median Upper quartiles (75%) lower quartiles (25%)
 median Upper quartiles (75%) lower quartiles (25%)")
7
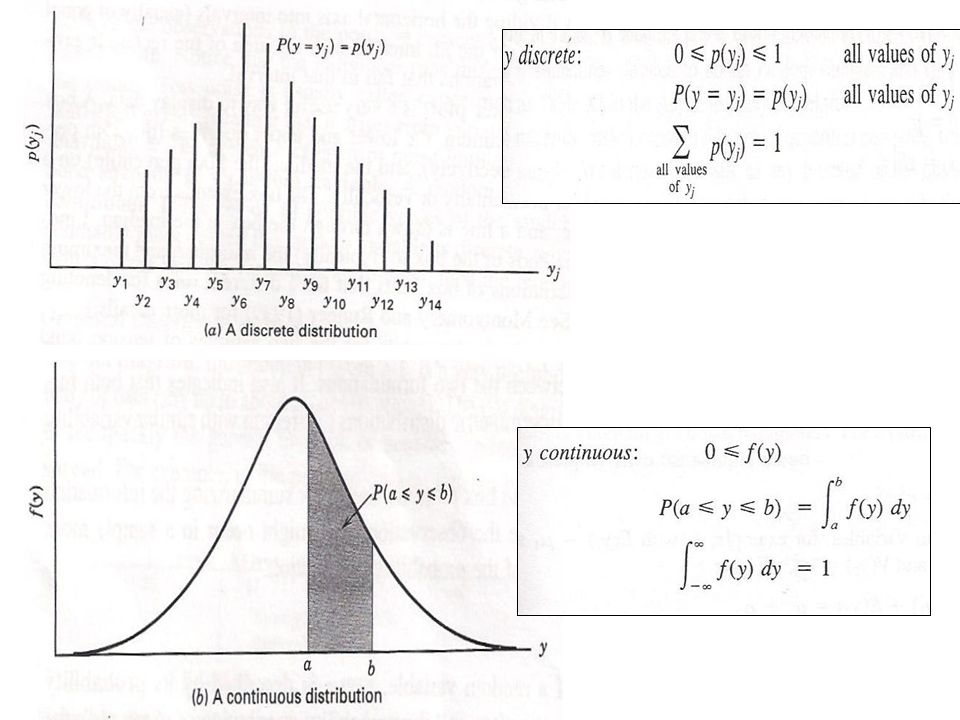
Probability Distributions The probability structure of a random variable, y is described by its probability distributions. If y is discrete – the probability function of y, p(y) If y is continuous – the probability density function, f(y)
 If y is continuous – the probability density function, f(y).")
9
Mean,μ of a probability distribution is a measure of its central tendency or location Mean, Variance and Expected value We may also express the mean in terms of expected value of random variable, y Where E denotes the expected value operator

10
The variability or dispersion of a probability distribution can be measured by the variance, defined as Note that the variance can be expressed entirely in terms of expectation because Finally the variance is used so extensively that it is convenient to define a variance operator, V such that

11
Inferences About Differences In Means, Randomized Design Hypothesis testing Choice of sample size Confidence intervals The case where σ 1 2 ≠ σ 2 2 The case where σ 1 2 and σ 2 2 are known Comparing a single mean to specified value

12
Hypothesis testing Lets reconsider the portland cement experiment. In general, we can consider 2 formulations (unmodified and modified mortar) involved as 2 level of the factor formulations. Let y 11,y 12,y 13,…y 1n1 represent the n1 observations from the first factor level, whereas y 21,y 22,y 23,…y 1n1 represent the n2 observations from the second factor level.
 involved as 2 level of the factor formulations. Let y 11,y 12,y 13,…y 1n1 represent the n1 observations from the first factor level, whereas y 21,y 22,y 23,…y 1n1 represent the n2 observations from the second factor level..")
13
We describe the results of experiment with a model. A simple statistical model : y= j observation from factor level i μ= mean of response ε = normal random variable = random error

14
1) Statistical hypothesis Is a statement either about the parameters of a probability distribution or the parameters of a model. Decision-making procedure about hypothesis is called hypothesis testing. For example, in the portland cement experiment, we may think that the mean tension bond strengths of two mortar formulation are equal. This may stated formally as:

15
Power = the probability of rejecting null hypothesis, H 0 when the alternative hypothesis, H 1 is true.

16
2) The two-sample t-Test The appropriate test statistic to use for comparing two treatment mean in completely randomized design is
 The two-sample t-Test The appropriate test statistic to use for comparing two treatment mean in completely randomized design is")
17
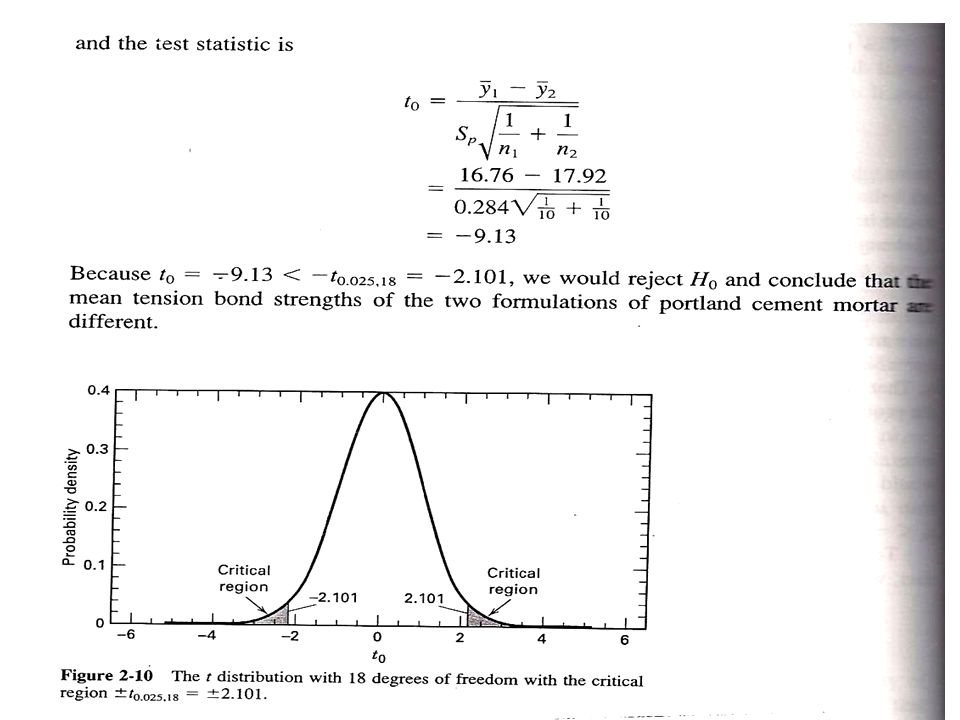
To determine whether to reject H 0 :μ 1 =μ 2, we would compare t 0 to the t distribution with n+n-2 degrees of freedom. If where is the upper α/2 percentage point of t distribution with n 1 +n 2 -2 degrees of freedom, we would reject H 0 and conclude that the mean strength of two formulation of portland cement differ. This test procedure is called two-sample t-test For one sided alternative hypothesis H 1 :μ 1 >μ 2, H 0 would be rejected if For H 1 :μ 1 <μ 2, H 0 would be rejected if

19
Example: From the portland cement data,

21
3) P-values One way to report the results of a hypothesis test is to state that the null hypothesis was or was not rejected at specified α-value or level of confidence. For example; in portland cement mortar formulation, we can say that H 0 :μ 1 =μ 2 was rejected at 0.05 level of confidence. This is inadequate conclusion because no idea exact location of the computed value in rejection region. Moreover, some decision maker might be uncomfortable with α=0.05. To overcome this difficulties P-value approach

22
P-value is the smallest level of significance that would lead to rejection of null hypothesis. P-value: Smallest level α at which data are significant. Therefore, can determine significance of data. It is not easy to compute exact P-value. However, approximation can be done. For portland cement mortar example, degree of freedom=18. From t- distribution table, the smallest tail area probability is 0.0005, for which t 0.0005,18 = 3.922 Now (H 0 is rejected), so because the alternative hypothesis is two-sided, P-values must be less than 2(0.0005)= 0.001.
, so because the alternative hypothesis is two-sided, P-values must be less than 2(0.0005)=")
23
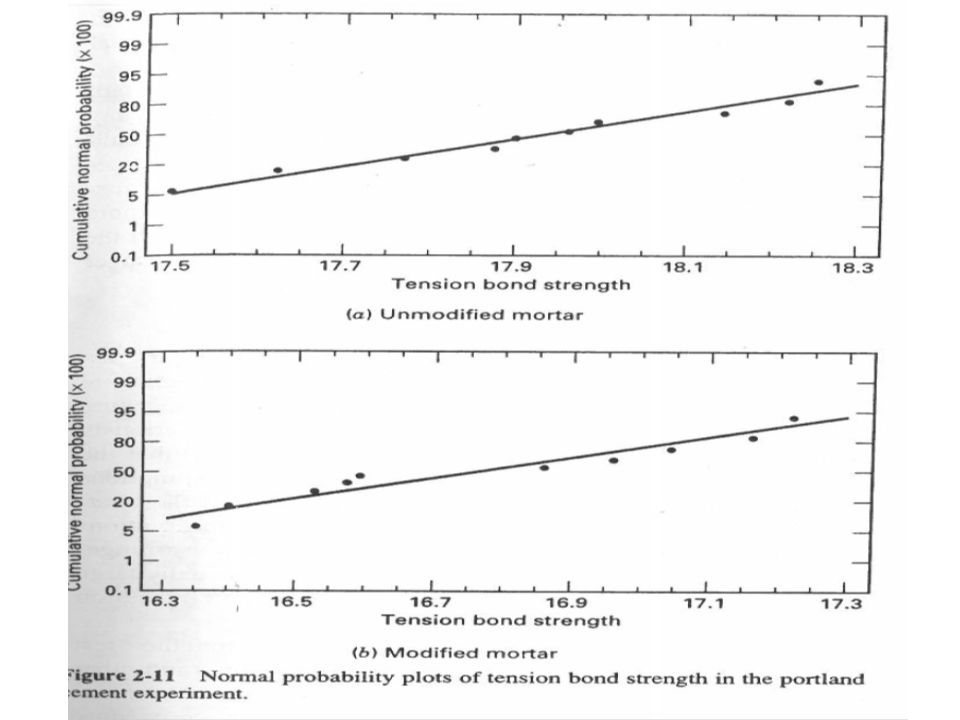
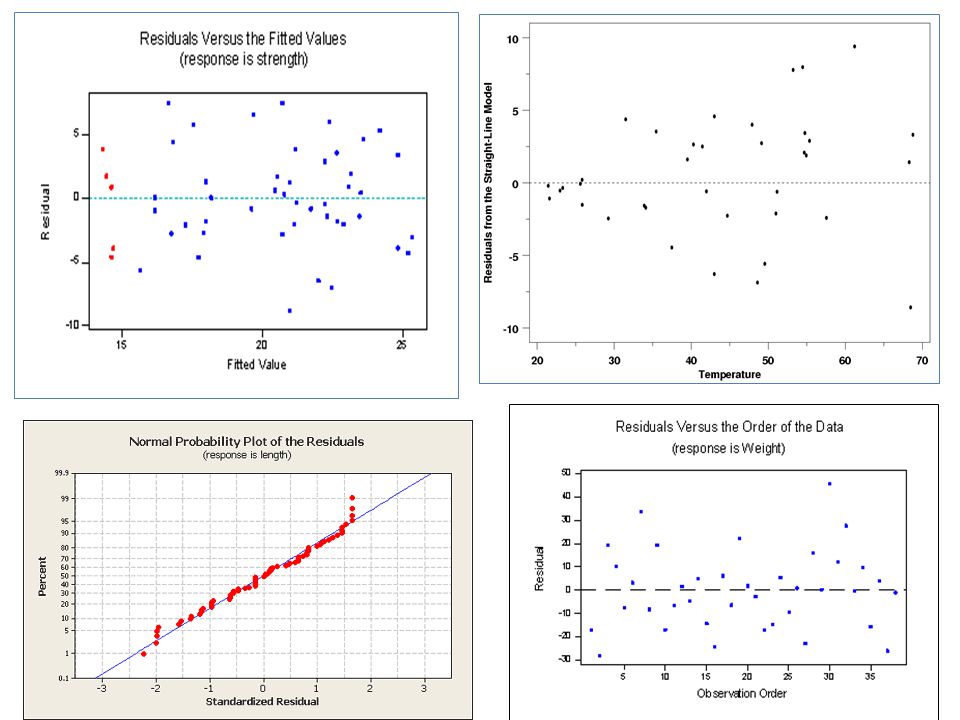
4) Normal probability plot Is a graphical technique for determining whether sample data conform to hypothesized distribution based on subjective visual exam of data. How to interpret? How to construct?? (j-0.5)/n, where j=1,2,3….n
/n, where j=1,2,3….n.")
25
Choice of sample size The choice of sample size and probability of type II error, β are closely related. Suppose we are testing And that the means, μ are not equal. Because H 0 :μ1=μ2 is not true, we are concerned about wrongly failing to reject H 0. β depends on true difference in mean,δ Graph β vs δ is called the operating characteristic curve or O.C. curve. Generally, β error decreases as the sample size increases. So, δ is easier to detect in bigger sample size.

26
d Example of O.C curve for the case where variance σ 1 2 and σ 2 2 are unknown but equal, and α= 0.05 From the curve; The greater the difference in mean, the smaller β error As the sample size increases, β gets smaller

27
How to use the O.C curve to calculate sample size? Suppose that δ=0.1, therefore, If σ = 0.25, then d= 0.2. If we want to reject the null hypothesis 95% of the time when μ1-μ2=0.1, then β=0.05 and d=0.2 yields n*=15 Since, therefore n = 8

28
Confidence intervals an interval within which the value of parameter or parameters in question would be expected to lie. Recall that an interval such as:

29
L and U are called lower and upper confidence limits. 1-α is called confidence coefficient. If α = 0.05, Equation 8.29 is called a 95% confidence interval for μ.

30
How to calculate confidence interval? is a 100(1-α) percent confidence interval for μ1-μ2.
 percent confidence interval for μ1-μ2.")
31
Example From portland cement mortar example discuss earlier; the actual 95% confidence interval estimate for difference in mean tension strength, Thus the confidence interval is μ1-μ2 = -1.16 kgf/cm 2 ±0.27 kgf/cm 2 Or the difference in mean strength is -1.16 and the accuracy of this estimate is ±0.27 kgf/cm 2

32
The case where σ 1 2 ≠ σ 2 2 If we are testing, And cannot assume the variances are equal, the test statistic becomes With calculation of degree of freedom as follows

33
The case where σ 1 2 and σ 2 2 are known If both variances are known, then the hypothesis

34
Comparing a single mean to specified value If we are testing, The test statistics, The confidence interval,

35
SUMMARY

37
Regression model

38
Regression model & Empirical model Suppose there is a single dependent variable or response,y that depends on k independent or regressor variables, for example x 1,x 2,x 3,…x k The relationship between y and k is characterized by mathematical model called a regression model. Regression model is the basis of empirical model *empirical model is created from experimental observations

39
Linear Regression Model Suppose we wish to develop an empirical model which relates viscosity of polymer to the temperature, x 1 and catalyst feed rate,x 2 This is multiple linear regression model. Why? β =regression coefficient x =predictor variables or regressor In general, any regression model that is linear in parameters is a linear regression model, regardless of the surface that is generated (normally related to model with interaction). Methods for estimating parameters in multiple linear regression is called model fitting. Typical method is method of least squares
. Methods for estimating parameters in multiple linear regression is called model fitting. Typical method is method of least squares.")
40
Least squares estimation of the parameters

46
Matrix Approach To Multiple Linear Regression

56
Properties of the least squares estimators and estimation of σ 2

58
Hypothesis Testing In Multiple Regression Test for significance of regression Test on individual regression coefficients and groups of coefficients

59
Test for significance of regression

64
Test on individual regression coefficients and groups of coefficients The model might be more effective with the inclusion of additional variables or with deletion of one or more regressor. test individual or groups of regression coefficient

67
Why C 22 = 0.0000015? Because of covariance matrix, C

68
Confidence interval in multiple regression On individual regression coefficient On the mean response

69
Confidence interval in multiple regression- On individual regression coefficient

71
Confidence interval in multiple regression- On the mean response

75
Thank you…

76
Quiz 1.Discuss one function of a regression model. 2.Define residual. List 2 plot that can be constructed using residual values. 3.Justify the importance of test of significance of a regression model. If the H o is accepted, what does it means? 4.An experiment was conducted to examine the effect of T and P on growth. Given, f 0 = MS R /MS E, MS E = 4.356, and f value from the f table = 2.3. Propose an appropriate conclusion if MS R value < 4.

Similar presentations
































>")











